







梯度爆炸和梯度消失是由于神经网络过长导致的,一般发生在RNN中。
由于RNN很多被用来解决时间序列的问题,而时间序列问题又具有很明显的先后顺序,需要不断的反向传播以更新网络权重,所以很容易发生梯度爆炸和梯度消失。
在这里科普下带时间序列的场景任务:
1: 语音识别 例如一段文字中我们需要根据语境判断下一个词的词性,这里的语境就是带有前后关联性的任务。
2: DNA 序列分析 我们都知道DNA序列的碱基对是有一定匹配规则的
3: 机器翻译 和语音识别类似,需要判断语境
4: 视频动作分析 给出一个人在运球的视频,我们需要根据前后正帧判断他在进行什么运动
时间序列任务场景特点:强关联性,强因果性
普通神经网络无法很好的解决这类问题,于是RNN应运而生。
梯度消失
梯度消失问题是指在反向传播过程中,位于前面的神经元由于导数或权重的叠加导致原始权重几乎无法得到更新,无法对最终结果参与贡献。可以理解为由于距离过长或者时间久远位于前面的神经元和位于输出层的神经元联系十分微弱。
特点:
- 模型提升很慢,甚至早早停止了训练,更多的训练也不会再改进模型
- 离 输出层 近的层权重改变更多,离 输入层 近的层权重改变更小
- 模型权重指数下降,变得很小
- 模型权重变为零
推导:
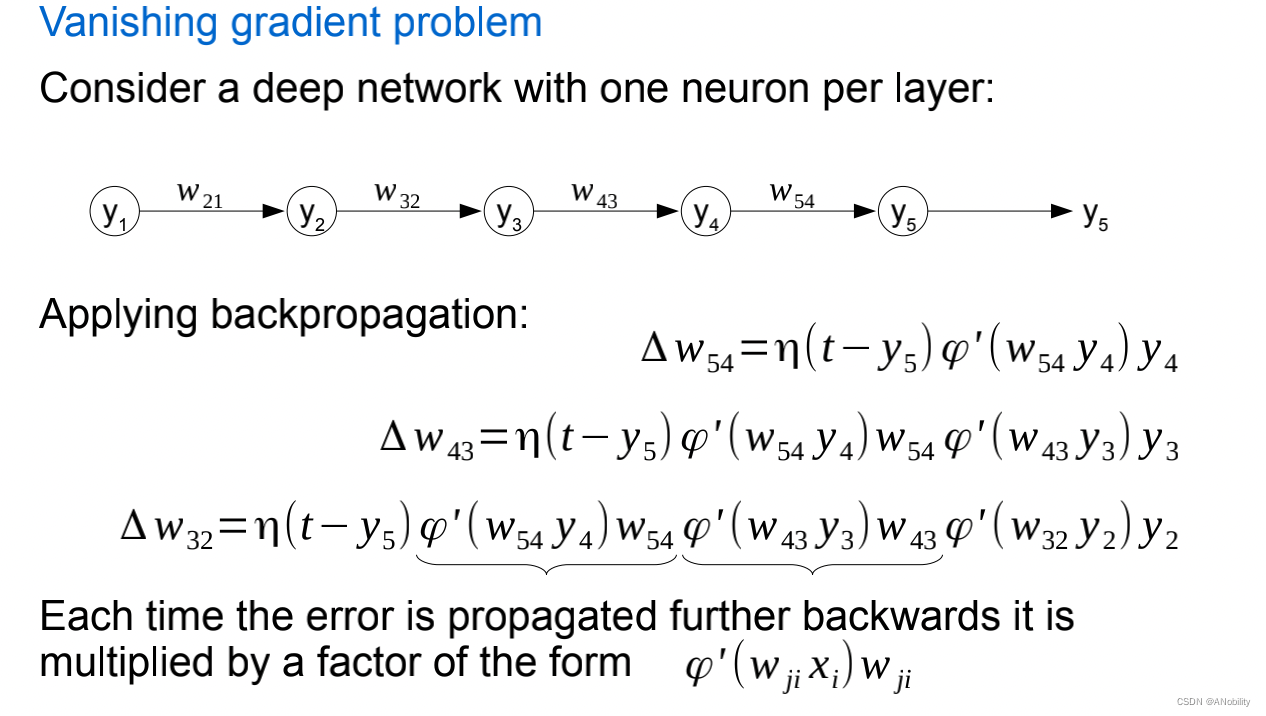


当我们得到
Δ
w
32
=η(
t
−
y
5
)
φ
'
(
w
54
y
4
)
w
54
φ
'
(
w
43
y
3
)
w
43
φ
'
(
w
32
y
2
)
y
2
时我们发现其中有相同的序列
φ
'(
w
ji
x
i)
w
ji
其中
φ
'(
w
ji
x
i) 为激活函数的导数,wji 为这一轮神经网络的权重
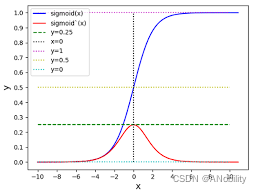
sigmoid 函数导数最高为0.25,所以每乘一次φ'(wji xi)就至少让上一层权重减少3/4,所以越往前的神经元Δwij 就越小。
wji 也会对Δwij 产生影响,当使用标准方法(0均值)初始化权重时,这一项也会很小。
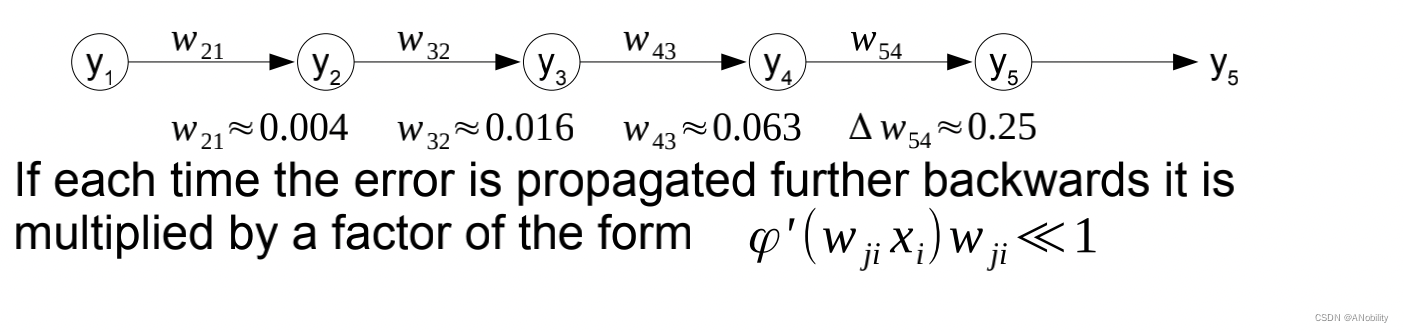
梯度消失
它的产生和梯度消失相似,但是主要是由于wji 的初始权重过大,导致反向传播Δwij 过大

特点:
-
模型没有从训练数据学到很多,导致 loss 没有很好下降
-
模型的 loss 值在每次更新中剧烈变化,很不稳定
-
模型的 loss 值在训练过程中变成 NaN
-
模型权重在训练过程中指数上升
-
模型权重在训练阶段变为 NaN
解决梯度消失和梯度爆炸的方法
● activation functions with non-vanishing derivatives
使用无梯度消失导数的激活函数,例如ReLU
● better ways to initialise weights
更好地初始化权重
● adaptive variations on standard backpropagation
自适应反向传播算法
● batch normalisation (BN)
批归一化
● skip connections
跳链接

















 2870
2870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











