







蒙特·卡罗方法(Monte Carlo method),也称统计模拟方法,是二十世纪四十年代中期由于科学技术的发展和电子计算机的发明,而被提出的一种以概率统计理论为指导的一类非常重要的数值计算方法。是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。与它对应的是确定性算法。蒙特·卡罗方法在金融工程学,宏观经济学,计算物理学(如粒子输运计算、量子热力学计算、空气动力学计算)等领域应用广泛。
蒙特卡罗方法的解题过程可以归结为三个主要步骤:构造或描述概率过程;实现从已知概率分布抽样;建立各种估计量。
-
通常不能保证计算出来的结果总是正确的, 一般只能断定所给解的正确性不小于p ( 1/2<p<1)
-
通过算法的反复执行(即以增大算法的执行时间为代价),能够使发生错误的概率 小到可以忽略的程度 (越算越好)
-
由于每次执行的算法是独立的,故k次执行均发生错误的概率为(1-p)k
-
对于判定问题(回答只能是“Yes”或 “No”)
- 带双错的(two-sided error): 回答”Yes”或”No”都 有可能错
- 带单错的(one-sided error):只有一种回答可能
优点
- 对于某一给定的问题,随机算法所需的时 间与空间复杂性,往往比当前已知的确定性算法要好
- 到目前为止设计出来的各种随机算法,无 论是从理解上还是实现上,都是极为简单的
- 随机算法避免了去构造最坏情况的例子
蒙特卡罗算法在一般情况下可以保证对问题的所有实例都以高概率给出正确解,但是通常无法判定一个具体解是否正确。
设p是一个实数,且1/2 <p <1。如果一个蒙特卡罗算法对于问题的任一实例得到正确解的概率不小于p,则称该蒙特卡罗算法是p正确的,且称p – 1/2是该算法的优势。如果对于同一实例,蒙特卡罗算法不会给出2个不同的正确解答,则称该蒙特卡罗算法是一致的。
有些蒙特卡罗算法除了具有描述问题实例的输入参数外,还具有描述错误解可接受概率的参数。这类算法的计算时间复杂性通常由问题的实例规模以及错误解可接受概率的函数来描述。对于一个一致的p正确蒙特卡罗算法,要提高获得正确解的概率,只要执行该算法若干次,并选择出现频次最高的解即可。
统计画图的一个好工具seaborn
Seaborn是Python中的可视化库。它建立在Matplotlib之上。http://codingdict.com/article/8890
我只挑了我喜欢的图,列了代码实现方便查找和使用。
import numpy as np
from matplotlib import pyplot as plt
def sinplot(flip=1):
x = np.linspace(0, 14, 100)
for i in range(1, 5):
plt.plot(x, np.sin(x + i * .5) * (7 - i) * flip)
import seaborn as sb
sb.set_style("whitegrid")
sinplot()
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],kde = False)
plt.show()kde 标志设置为False。结果,将去除核估计图的表示并且仅绘制直方图。

import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()散点图是可视化分布的最方便的方式,其中每个观察通过x和y轴在二维图中表示。

import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.set_style("ticks")
sb.pairplot(df,hue = 'species',diag_kind = "kde",kind = "scatter",palette = "husl")
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.stripplot(x = "species", y = "petal_length", data = df, jitter = Ture)
plt.show()
方块图
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.swarmplot(x = "species", y = "petal_length", data = df)
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('titanic')
sb.barplot(x = "sex", y = "survived", hue = "class", data = df)
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.boxplot(data = df, orient = "h")
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin',data = df);
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('exercise')
sb.factorplot(x = "time", y = "pulse", hue = "kind", kind = 'violin', col = "diet", data = df);
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter);
plt.show()
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
g = sb.PairGrid(df)
g.map_upper(plt.scatter)
g.map_lower(sb.kdeplot, cmap = "Blues_d")
g.map_diag(sb.kdeplot, lw = 3, legend = False);
plt.show()
例子
构建蒙特卡洛模拟,以预测销售补偿预算的潜在值范围
尝试预测下一年应为销售佣金预算的金额。示例中,一个5人销售人员的示例销售佣金如下所示:

在此示例中,佣金是以下公式的结果:佣金金额=实际销售额*佣金率
佣金率基于以下计划百分比表:
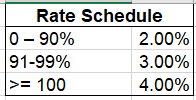
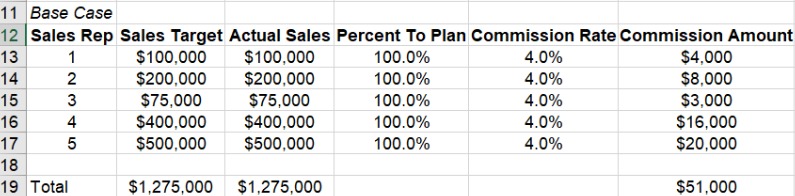
1. 一种简单的方法来预测明年的佣金支出。分析师任务是告诉财务部门明年的销售佣金预算是多少。 一种方法是假设每个人都达到目标的100%,并获得4%的佣金率。 将这些值插入Excel将产生以下结果:
当然相同的佣金率是不现实的,因此要得到相对精确的佣金预算可以加一些随机
蒙特卡洛分析运行具有不同随机输入的许多方案,并汇总结果的分布。运行程序100甚至1000次,我们将获得潜在佣金金额的分布。这种分布可以告知费用在某个窗口之内的可能性。参考已经支付了数年的佣金,我们可以查看目标的百分比的典型历史分布:

该分布看起来像正态分布,平均值为100%,标准偏差为10%,我们可以对输入变量的分布进行建模,使其类似于我们的实际经验。
实际的分布是:

这绝对不是正态分布。 此分布向我们展示了将销售目标设置为6个中1个,并且频率随着数量的增加而降低。 这种分布可能表明目标设定过程非常简单,其中个人被归类为某些群体,并根据其任期,地域规模或销售渠道一致地给定目标。
出于本示例的考虑,我们将使用均匀分布,但为某些值分配较低的概率。
实际销售额可能会发生很大变化,但效果分配仍然保持一致。使用随机分布来生成输入并支持实际销售。
import pandas as pd
import numpy as np
import seaborn as sns
sns.set_style('whitegrid')
def calc_commission_rate(x):
""" Return the commission rate based on the table:
0-90% = 2%
91-99% = 3%
>= 100 = 4%
"""
if x <= .90:
return .02
if x <= .99:
return .03
else:
return .04
#mean of 100% and standard deviation of 10%
avg = 1
std_dev = .1
num_reps = 500
num_simulations = 1000
sales_target_values = [75_000, 100_000, 200_000, 300_000, 400_000, 500_000]
sales_target_prob = [.3, .3, .2, .1, .05, .05]
# Define a list to keep all the results from each simulation that we want to analyze
all_stats = []
# Loop through many simulations
for i in range(num_simulations):
# Choose random inputs for the sales targets and percent to target
sales_target = np.random.choice(sales_target_values, num_reps, p=sales_target_prob)
#generate a list of percentages
pct_to_target = np.random.normal(avg, std_dev, num_reps).round(2)
# Build the dataframe based on the inputs and number of reps
df = pd.DataFrame(index=range(num_reps), data={'Pct_To_Target': pct_to_target,
'Sales_Target': sales_target})
# Back into the sales number using the percent to target rate
df['Sales'] = df['Pct_To_Target'] * df['Sales_Target']
# Determine the commissions rate and calculate it
df['Commission_Rate'] = df['Pct_To_Target'].apply(calc_commission_rate)
df['Commission_Amount'] = df['Commission_Rate'] * df['Sales']
# We want to track sales,commission amounts and sales targets over all the simulations
all_stats.append([df['Sales'].sum().round(0),
df['Commission_Amount'].sum().round(0),
df['Sales_Target'].sum().round(0)])
results_df = pd.DataFrame.from_records(all_stats, columns=['Sales',
'Commission_Amount',
'Sales_Target'])
results_df.describe().style.format('{:,}')
print(results_df)















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









