






 本文介绍了如何运用深度学习,特别是卷积神经网络和迁移学习技术,开发一个基于手势控制的鼠标系统,并探讨了如何利用预训练模型如EfficientNetV2进行玉米叶片病害识别。实验中涉及数据集的构建、模型训练和优化策略,如Adam算法的选择和数据增强技术的应用。
本文介绍了如何运用深度学习,特别是卷积神经网络和迁移学习技术,开发一个基于手势控制的鼠标系统,并探讨了如何利用预训练模型如EfficientNetV2进行玉米叶片病害识别。实验中涉及数据集的构建、模型训练和优化策略,如Adam算法的选择和数据增强技术的应用。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的手势识别控制鼠标系统
项目背景
随着人工智能技术的快速发展,人机交互方式正在发生深刻变革。手势识别作为一种直观的人机交互技术,在智能家居、虚拟现实等领域具有广泛的应用前景。基于深度学习的手势识别控制鼠标系统,通过利用深度学习技术和计算机视觉方法,使得用户可以通过手势来控制鼠标,提供了一种新的人机交互方式。此课题的研究对于推动深度学习技术在手势识别领域的应用,提高人机交互的便捷性和自然性,具有重要意义。
数据集
由于网络上没有现有的合适的数据集,我决定自己进行手势演示,收集图片并制作了一个全新的数据集。这个数据集包含了各种手势的照片,其中包括不同年龄段、不同性别的人的手势,以及各种不同的手势动作。通过现场拍摄,我能够捕捉到真实的手势动作和多样的背景环境,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为基于深度学习的手势识别控制鼠标系统研究提供有力的支持,并为该领域的发展做出积极贡献。
数据扩充是提高模型鲁棒性和泛化能力的重要手段。在本研究中,我们对收集到的手势图片数据进行了多样化的数据扩充。包括使用图像处理技术生成新的训练样本,如旋转、缩放、裁剪等。这些扩充后的数据能够帮助模型更好地学习和理解手势的多样性和复杂性,提高模型在实际应用中的表现力。同时,数据扩充还可以增加模型的泛化能力,使其在面对未见过的数据时仍能保持良好的性能。
设计思路
卷积神经网络
卷积神经网络(CNN)是一种深度学习模型,广泛应用于图像处理和计算机视觉领域。它由卷积层、池化层、激活函数、全连接层和输入层组成。卷积层通过卷积运算提取图像的局部特征,并映射到特征图上。激活函数引入非线性变换,增强网络的拟合能力。池化层进行下采样操作,减少参数和计算量,并保持特征的不变性。全连接层整合池化层的输出,形成高维向量,并通过分类器实现最终的任务目标。CNN能够有效地提取图像特征,并用于分类、回归等任务。
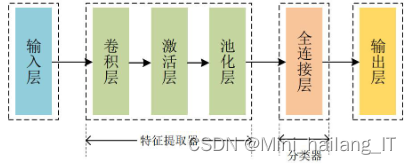
卷积层是卷积神经网络的核心组成部分,通过卷积运算从输入图像中提取有用的特征,并将其映射到新的特征图上。卷积层的关键是卷积核,它定义了不同大小和数量的小矩阵,用于适应不同的图像特征。卷积运算是通过滑动卷积核在输入图像上的过程,每次滑动指定步长,并在对应区域进行逐元素相乘和求和操作,生成新的特征图。这样,通过卷积层的运算,可以捕捉到原始图像的特征响应。

为了增强卷积神经网络的非线性拟合能力,在卷积层后加入激活函数。激活函数是一种非线性变换,它实现输入图像与输出特征图之间的非线性映射,使网络能够学习更高层次的特征和抽象。常用的激活函数包括Sigmoid、Relu和Swish等。Sigmoid函数将网络层的输出值压缩到(0,1)之间,适用于概率预测模型和二分类问题。Sigmoid函数的优点是平滑,输出值变化连续且渐进。然而,Sigmoid函数的缺点是输入值过大或过小时容易导致梯度消失或饱和现象,影响网络的训练效率和效果。激活函数在激活层中起到提高模型鲁棒性、增强非线性表达能力、缓解梯度消失问题和加速模型收敛的作用。常见的激活函数分为饱和非线性函数(如Sigmoid和Tanh)和不饱和非线性函数(如ReLU和LeakyReLU)两种。
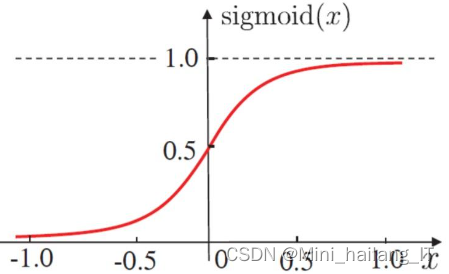
GoogLeNet 模型
在卷积神经网络的发展过程中,仅仅增加网络的深度和宽度并不能持续提高网络性能,反而可能引发过拟合、梯度消失和计算量过大等问题。GoogLeNet的主要贡献是引入了Inception结构,它是一种多尺度的特征提取模块,将这些特征进行拼接,形成更丰富和更高维的特征向量。在使用不同大小的卷积核时,为了保持特征图的尺寸一致,需要设置适当的步长和填充方式。
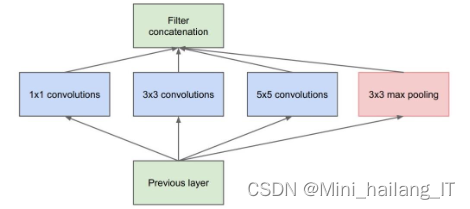
ResNet的主要贡献在于解决了梯度消失或爆炸的问题,并提升了网络性能。其核心思想是残差学习,通过引入跳跃连接的方式,将输入数据直接传递到输出层,避免了中间层对数据的损失或干扰。假设输入数据为𝑥,期望学习到的特征为𝐻(𝑥),则残差学习后学习到的特征为𝐹(𝑥) = 𝐻(𝑥) − 𝑥。在训练ResNet时,主要学习的是残差特征𝐹(𝑥),这简化了学习过程并能提取出新的特征。当残差特征𝐹(𝑥)为0时,该层变成了恒等映射,即直接将输入数据传递到输出层,不会影响网络性能。
深度迁移学习
迁移学习是为了解决深度学习领域中训练样本不足的挑战而提出的方法。其核心目标是利用已有的知识来解决新问题,而不要求训练数据和测试数据服从相同的分布。迁移学习涉及两个基本概念,即领域(Domain)和任务(Task)。领域由特征空间和特征分布组成,源领域是知识来源,目标领域是知识应用。任务由标签空间和条件概率分布组成,源任务是源领域中的任务,目标任务是目标领域中需要进行预测的任务。
根据迁移的内容,迁移学习可以分为四种类型。基于实例的迁移方法通过重新加权源领域中的实例,使其在目标领域中更有利于学习。基于特征表示的迁移方法寻找能够减小源领域和目标领域之间差异的特征表示,以提高分类或回归模型的性能。基于参数的迁移方法利用源领域和目标领域之间共享的参数或先验知识,来初始化或约束目标领域的模型,减少对数据量和训练时间的需求。基于关系型知识的迁移方法在满足源领域和目标领域相关但非独立同分布条件下,建立这两个领域之间关系型知识的映射,实现迁移学习过程。
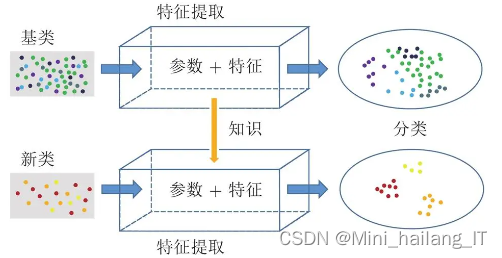
预训练模型是一种常用的深度学习技术,通过在大型数据集上训练好的模型,在自己的数据集上进行微调以适应新任务,从而节省训练时间和资源,并提高模型性能。在本实验中,采用了EfficientNetV2作为预训练模型,并通过微调来提高图像分类的识别精度。微调过程中保留了预训练模型的卷积基部分,替换了原有的分类器,并冻结了部分卷积层参数,只训练新的分类器。解冻网络顶部的卷积层能提取更高层次、更抽象的特征,使模型更适应当前任务,提高识别精度和泛化能力。通过充分利用预训练模型的优势,并结合新任务的需求,实现了更好的模型适应性和性能表现。
实验环境
实验在一台配备Intel Xeon Gold 6130 @ 2.10GHz CPU和NVIDIA RTX 2080Ti GPU的Linux工作站上进行。NVIDIA RTX 2080Ti GPU具有4320个CUDA内核和11GB内存,提供了强大的计算加速能力。通过利用GPU的并行计算能力,扩充实验可以在更快的时间内处理大规模的计算任务,提高实验的效率和性能。此配置使得扩充实验能够充分利用GPU的计算资源,并且适用于需要大规模计算和内存需求的深度学习任务。
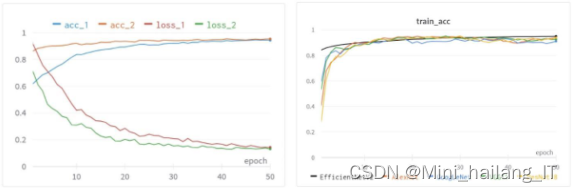
实验结果分析
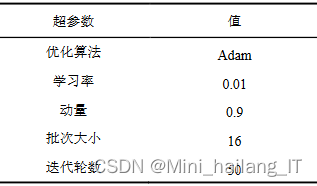
为了更好地训练神经网络,需要选择适当的网络超参数。本章实验采用了Adam算法作为反向传播的优化方法,基于以下几点考虑:1)Adam算法是一种自适应学习率算法,能够根据梯度的变化自动调整学习率,避免了手动调节学习率的麻烦;2)Adam算法具有高效的计算性能和较低的内存需求,适合处理大规模的数据和模型;3)Adam算法对梯度的对角重新缩放具有不变性,能够在不同的尺度下保持稳定的梯度更新方向;4)实践中证明,Adam算法具有较快的收敛速度和较好的泛化能力,能够有效地优化复杂的非凸函数。
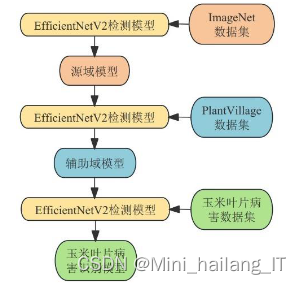
针对识别玉米叶片病害类型的任务,设计了基于深度迁移学习的图像识别流程,包括以下步骤:1)将采集的玉米叶片病害数据集划分为训练集、验证集和测试集,并对训练集的图像进行数据增强操作,增加样本数量和多样性;2)选择EfficientNetV2、VGG、AlexNet、GoogLeNet和ResNet等五种网络作为基础模型,在ImageNet数据集上进行预训练,学习通用特征,然后在PlantVillage数据集上进行二次预训练,学习植物病害的先验知识;3)将预训练好的模型迁移到玉米叶片病害数据集上,对最后一层进行微调,使其适应玉米叶片病害分类任务,并通过测试集评估模型的识别准确率和其他性能指标。
相关代码示例:
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 设置随机种子
tf.random.set_seed(42)
# 数据路径
train_dir = 'path_to_train_data'
test_dir = 'path_to_test_data'
# 数据增强
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
test_datagen = ImageDataGenerator(rescale=1./255)
# 加载训练集和测试集
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical'
)
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical'
)
海浪学长项目示例:























 4197
4197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









