







 本文介绍了如何利用Python和Scrapy技术开发一个基于网易云音乐的数据分析可视化系统,包括数据集的创建、网络爬虫技术的应用、数据预处理、存储以及使用matplotlib等工具进行数据分析和可视化。项目旨在通过音乐数据洞察,提供个性化音乐体验和业务决策支持。
本文介绍了如何利用Python和Scrapy技术开发一个基于网易云音乐的数据分析可视化系统,包括数据集的创建、网络爬虫技术的应用、数据预处理、存储以及使用matplotlib等工具进行数据分析和可视化。项目旨在通过音乐数据洞察,提供个性化音乐体验和业务决策支持。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于python的网易云音乐数据分析可视化系统
项目背景
随着互联网和数字音乐的快速发展,音乐数据的规模和复杂性不断增加。对于音乐从业者和音乐爱好者而言,深入了解和分析音乐数据对于推动音乐产业的发展和提供个性化音乐体验至关重要。基于Python的网易云音乐数据分析可视化系统的研究和开发,旨在利用计算机视觉和数据分析技术,实现对大规模音乐数据的收集、处理和分析,从而为音乐产业、音乐创作和用户提供有价值的洞察和决策支持。
数据集
鉴于网络上缺乏现有的合适音乐数据集,为了支持该课题的研究,我决定利用网络爬虫技术来收集数据。通过爬取网易云音乐平台上的音乐信息、用户评论和用户行为数据,我制作了一个全新的、多样化的网易云音乐数据集。该数据集包含了丰富的音乐信息、用户评价和用户行为,将为我的研究提供更准确、可靠的数据基础。
设计思路
网络爬虫是一种自动化的程序或脚本,用于在互联网上抓取和提取网页信息。它通过模拟人类浏览器的行为,发送HTTP请求获取网页内容,并对网页进行解析和数据提取。网络爬虫在互联网数据采集、搜索引擎索引、数据挖掘等领域发挥着重要作用。其工作流程包括指定起始URL、发送HTTP请求、解析网页、处理数据、存储数据以及处理反爬虫机制。然而,在进行网络爬虫时,应遵守爬虫规则和道德准则,确保合法、合规地获取数据,并对抓取行为进行适当限制,以避免对网站造成过大负担和侵犯他人的权益。
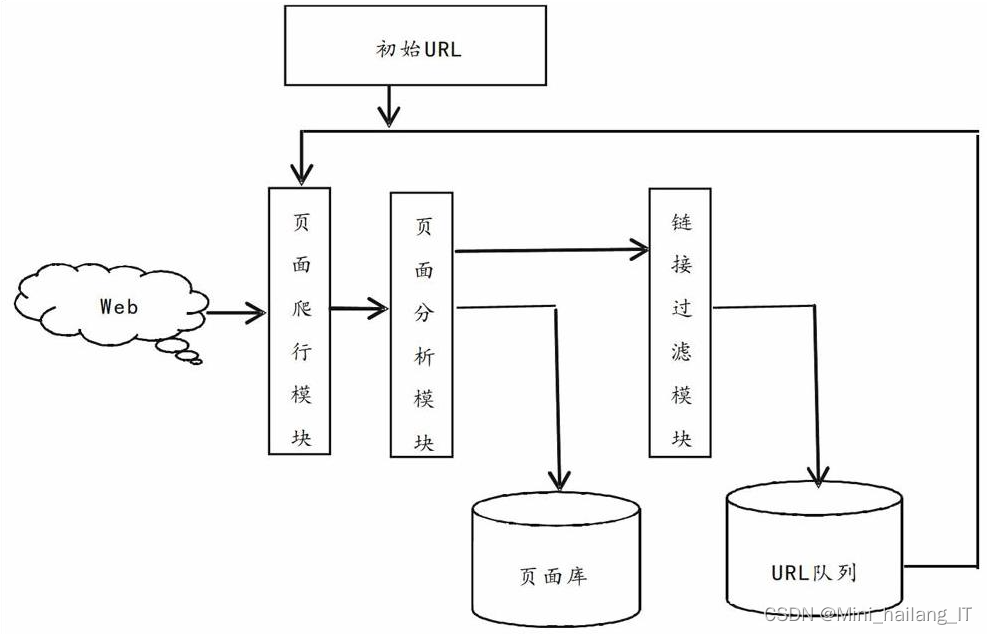
Scrapy爬虫技术在音乐可视化系统中的应用主要集中在数据收集、数据预处理、数据存储以及数据分析和可视化等方面。通过使用Scrapy框架,可以方便地爬取音乐网站上的歌曲信息、艺术家信息和歌单信息等大量音乐数据,这些数据可以作为音乐可视化系统的基础。同时,Scrapy还提供了强大的数据处理和存储功能,可以对原始数据进行清洗、转换和持久化存储。最后,通过对爬取到的音乐数据进行分析和可视化,可以展示音乐的统计信息、时序趋势、情感分析等,为用户呈现丰富的音乐可视化效果。
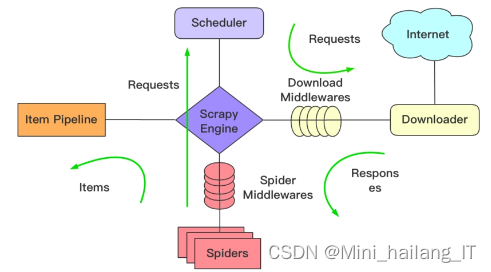
音乐数据分析可视化系统可以采用以下技术思路:
- 数据获取:使用网易云音乐的开放API或爬虫技术,获取用户的听歌记录、歌单信息、评论数据等相关数据。可以使用Python的requests库进行API调用或使用BeautifulSoup或Scrapy进行网页爬取。
- 数据存储:将获取的音乐数据存储到数据库中,可以选择使用关系型数据库(如MySQL)或非关系型数据库(如MongoDB)进行存储。使用Python的数据库连接库(如pymysql或pymongo)进行数据存储和查询操作。
- 数据清洗和预处理:对获取的数据进行清洗、去重和格式化处理。例如,处理缺失值、处理重复数据、格式化日期和时间等。可以使用Python的数据处理库(如pandas)进行数据清洗和预处理。
- 数据分析和可视化:使用Python的数据分析和可视化库(如matplotlib、seaborn、Plotly等)对音乐数据进行分析,并生成交互式的可视化图表和报表。可以对用户的听歌习惯、喜好曲风、歌曲排行榜等进行分析和可视化展示。
- 用户交互界面:设计一个用户友好的交互界面,使用Python的Web框架(如Flask或Django)搭建系统的前端部分,实现用户的登录、数据查询和可视化展示功能。可以使用HTML、CSS和JavaScript等前端技术进行界面设计和交互效果的实现。
相关代码示例:
import requests
import matplotlib.pyplot as plt
# 使用网易云音乐API获取用户的听歌记录
def get_user_play_records(user_id):
url = f"https://music.163.com/api/user/playlist?uid={user_id}"
response = requests.get(url)
data = response.json()
if data["code"] == 200:
playlists = data["playlist"]
record_count = playlists[0]["playCount"]
return record_count
else:
print("获取听歌记录失败")
return None
# 用户ID
user_id = "your_user_id"
# 获取用户的听歌记录
play_records = get_user_play_records(user_id)
# 生成柱状图进行可视化
plt.bar(["听歌记录"], [play_records])
plt.xlabel("指标")
plt.ylabel("数量")
plt.title("网易云音乐听歌记录")
plt.show()海浪学长项目示例:
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









