







本文是实验设计与分析(第6版,Montgomery著傅珏生译)第8章2水平分式设计第8.3节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
对中等大的因子个数,常用2k设计的较小的分式设计。考虑2k设计的1/4分式设计。此设计包含2k-2个试验,通常叫做2k-2分式析因设计。
2k-2设计的构造方法是,首先写出k一2个因子的完全析因设计的试验组成的基本设计,然后再加上两列,这两列由开头的k一2个因子的拾当交互作用组成的。这样一来,2k-2设计的1/4分式设计有两个生成元。如果P和Q代表选取的生成元,则,I=P和I=Q叫做此设计的生成关系(generating relation)。P和Q的符号(+或者-)决定了采用哪一种l/A分式,与生成元±P和±Q的选择有关的所有4个分式是同一族的成员。P和Q都是正的那个分式是主分式。
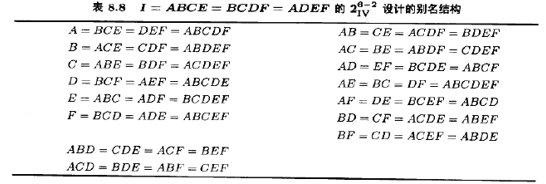
所有等于单位列I的列组成设计的完全定义关系。这由P,Q,以及它们的广义交互作用PQ所组成,也就是说,定义关系是I=P=Q=PQ,称元素P,Q,PQ为定义关系词。任一效应的别名可由效应所在的列乘以定义关系的每个词而得。显然,每一效应有3个别名,实验者要谨慎地选择生成元以避免可能重要的效应相互为别名,作为例子,考虑26--2设计。设选取了I=ABCE和I=BCDF为设计的生成元。生成元ABCE和BCDF的广义交互作用是ADEF,因此,此设计的完全定义关系是
I=ABCE-BCDF=ADEF
从而,此设计分辨度为V。为求得任一效应(例如A)的别名,将此效应与定义关系的每个词相乘即可。对于A,得
A=BCE-ABCDF=DEF
容易证明,每个主效应的别名是三因子交互作用和五因子交互作用,二因子交互作用的别名是另一个二因子交互作用或更高阶交互作用。于是,估计A时,我们实际上是估计A十BCE+DEF+ABCDF,此设计的全部别名结构见表8.8。如果三因子和更高阶的交互作用可被忽路,则此设计给出了主效应的纯净估计量
要构造此设计,首先写出基本设计,它由以A,B,CD为因子的完全26-2=2设计的16个试验所组成。然后加上两个因子E和F,它们的水平分别由交互作用ABC和BCD的加减符号所决定。此方法见表8.9。
构造此设计的另一方法是,先使ABCE和BCDF与区组相混,导出26设计的4个区组,然后选取处理组合在ABCE和BCDF上都为正的区组,这就得出生成关系为I=ABCE和I=BCDF的26-2分式析因设计,因为生成元ABCE和BCDF都是正的,这就是主分式。
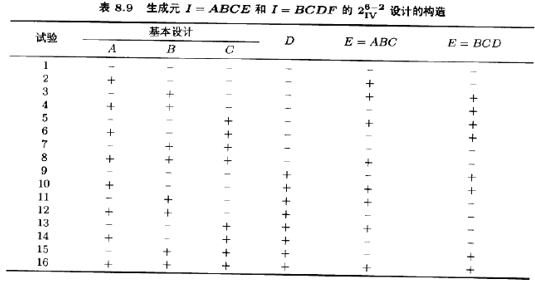
当然,此26-2设计还有3个备选分式设计。它们是生成关系I=ABCE和I=一BCDF,I=-ABCE和I=BCDF,I=-ABCE和I=-BCDF的分式设计。这些分式设计容易
用表8.9所示的方法构成。例如,如果要求出I=ABCE和I=-BCDF的分式设计,则在表8.9的最后一列令F=-BCD,因子F这一列的水平变成
++----++--++++--
此备选分式设计的完全定义关系是I=ABCE=-BCDF=-ADEF。表8.9中别名结构的
某些符号现在更改了,例如,A的别名是A=BCE=-DEF=一ABCDF。这样一来,观测值的线性组合[A]实际上是估计A+BCE-DEF-ABCDF。
最后,26-2IV分式析因设计可压缩为由4个因子构成的任一子集的单次重复的24设计,只要这一子集不是定义关系中的一个词即可,也可以压缩为由4个因子构成的任一子集的有重复的24设计的1/2分式设计,只要那一子集是定义关系中的一个词就行。如此,表8.9的设计就变成以因子A,B,C,E,或B,C,D,F,或A,D,E,F构成的有两次重复的2-1分式析因设计,因
为那些因子正是定义关系的词。6个因子还有另外12个组合,比如ABCD,ABCF,等等,它们是此设计在单次重复的2设计上的投影。此设计还可压缩为由6个因子的任意3个组成的有4次重复的23设计,或由两个因子组成的有4次重复的22设计。
一般说来,任一2k-2分式析因设计可以压缩为由原来的因子的r≤k-2个元素的某一子集构成的完全析因设计或分式析因设计,构成完全析因设计的那些变量的子集不是完全定义关系中的词。
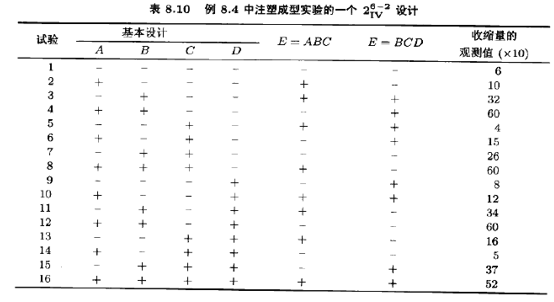
例8.4在注塑成型生产线上制造的零件显得过度收缩。这是在装配时发现的,寻根探源是由注塑成型工序引起的。质量改进小组决定用实验设计去研究注塑成型生产过程,以破小收缩率。小组决定研究6个因--成型湿度(A),螺杆转速〔B),保持时间(C),循环时间(D),射口大小(E),保压压力(F)--每个因子取两个水平。研究的目的是弄清每个因子是怎样影响收缩量的,因子的交互作用怎么样。
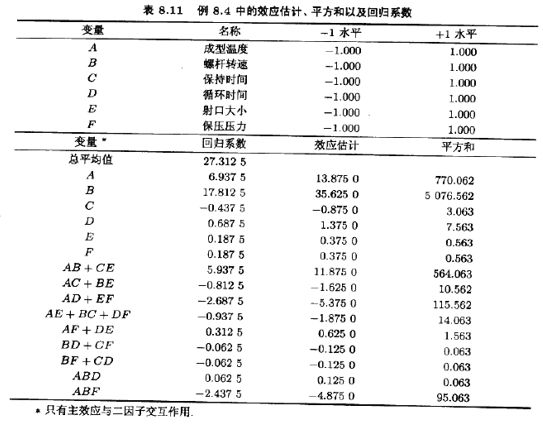
小组决定用表8.9的有16个试验的二水平分式析因设计。此设计再度列于表8.10中,在做设计的16个试验的每一个试验时,测试生产零件得到观测的收缩量(×10)也一起列在该表中。表8.11列出了该实验的效应估计、平方和以及回归系数。
from pyDOE2 import *
import statsmodels.formula.api as smf
import pandas as pd
import statsmodels.api as sm
from sklearn import linear_model
import seaborn as sns
import matplotlib.pyplot as plt
mydoe=fracfact('a b c d abc bcd')
y =[6,10,32,60,4,15,26,60,8,12,34,60,16,5,37,52]
df =pd.DataFrame(mydoe)
df['y']=y
model = smf.ols('df.y~df[0]+df[1]+df[2]+df[3]+df[4]+df[5]+df[0]:df[1]+df[0]:df[2]+df[0]:df[3]+df[1]:df[2]+df[1]:df[3]+df[2]:df[3]', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
Results: Ordinary least squares
=================================================================
Model: OLS Adj. R-squared: 0.927
Dependent Variable: df.y AIC: 100.1884
Date: 2024-04-25 14:25 BIC: 110.2320
No. Observations: 16 Log-Likelihood: -37.094
Df Model: 12 F-statistic: 16.97
Df Residuals: 3 Prob (F-statistic): 0.0196
R-squared: 0.985 Scale: 32.229
------------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
------------------------------------------------------------------
Intercept 27.3125 1.4193 19.2441 0.0003 22.7958 31.8292
df[0] 6.9375 1.4193 4.8881 0.0164 2.4208 11.4542
df[1] 17.8125 1.4193 12.5505 0.0011 13.2958 22.3292
df[2] -0.4375 1.4193 -0.3083 0.7781 -4.9542 4.0792
df[3] 0.6875 1.4193 0.4844 0.6613 -3.8292 5.2042
df[4] 0.1875 1.4193 0.1321 0.9033 -4.3292 4.7042
df[5] 0.1875 1.4193 0.1321 0.9033 -4.3292 4.7042
df[0]:df[1] 5.9375 1.4193 4.1835 0.0249 1.4208 10.4542
df[0]:df[2] -0.8125 1.4193 -0.5725 0.6071 -5.3292 3.7042
df[0]:df[3] -2.6875 1.4193 -1.8936 0.1546 -7.2042 1.8292
df[1]:df[2] -0.9375 1.4193 -0.6606 0.5561 -5.4542 3.5792
df[1]:df[3] -0.0625 1.4193 -0.0440 0.9676 -4.5792 4.4542
df[2]:df[3] -0.0625 1.4193 -0.0440 0.9676 -4.5792 4.4542
-----------------------------------------------------------------
Omnibus: 23.464 Durbin-Watson: 3.225
Prob(Omnibus): 0.000 Jarque-Bera (JB): 2.493
Skew: -0.000 Prob(JB): 0.287
Kurtosis: 1.066 Condition No.: 1
=================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the
errors is correctly specified.
print(model.params)
anovatable=sm.stats.anova_lm(model)
anovatable
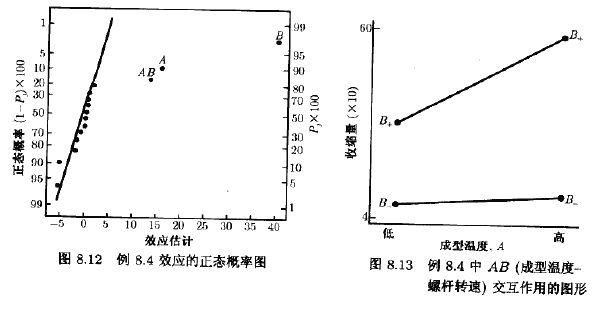
此实验的效应估计值的正态制率图见图8.12,较大的效应只有A(成型温度),B(螺杆转速),以及AB的交互作用。看一下表8.8的别名关系,暂时接受这些结论看来是合理的。图8.13的AB交互作用图表明:当螺杆转速处于低水平时,生产过程对温度很不做感;当螺杆转速处于高水平时,对温度十分敏感。当螺杆转速为低水平,则不管温度运什么水平,得到的平均收缩率约为10%。
据此初步分析,小组决定成型温度与螺杆转速都用低水平。这组条件使零件的平均收缩率减至大约10%。但是,零件之间收缩率的变异性仍然是一个句题。实际上,用上述的调整方法,平均收缩率可近当减少。然而,零件问收缩率的变异性可能还会在装配上引起问题.解决句题的一个办法是,看一下有无因子影响零件收缩率的变异性。
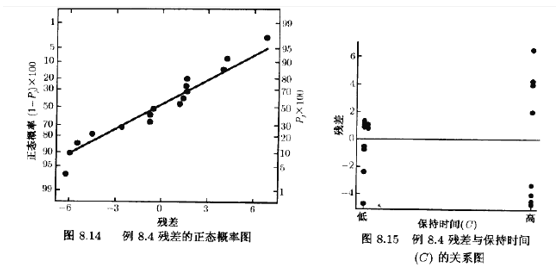
图8.14是残差的正态概率图。此图令人满意。然后作出残差与每个因子的关系图。图8.15是这些图之一,残差与因子C(保持时同)的关系图。此图表明,残差在保持时间处于低水平时远没有处于高水平时那样分散,这些残差是按常规方法从收缩率的顶测模型求得的。因为预测的收缩率
![]()
其中x1,x2,x1x2是规范变量,分别对应于因子A,因子B,以及AB交互作用,于是残差为
![]()
用来产生残差的回归模型实质上是从数据中消除了A,B,AB的位置效应,因此,残差包含有未加说明的变异性信息。图8.15表明,变异性中有一定的模式,当保持时间处于低水平时,零件收缩率的变异性较小,〔请回忆在第6章我们看到的,当位置或均值模型是正确时残差只是反映关于分散效应的信息)
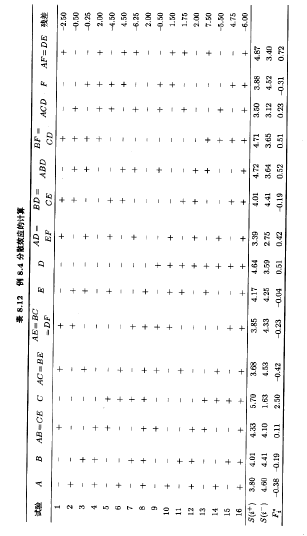
更为详细的残差分析如表8.12所示。此表列出了每个因子低水平(-)和高水平(+)处的残差,并计算出了每个因子低水平和高木平处的残差的标准差。C处于低水平时的残差标准差[S(C-)=1.63]明显小于C处于高水平时的残差标准差[S(C+)=5.70]。
表8.12下面一行表示统计量
![]()
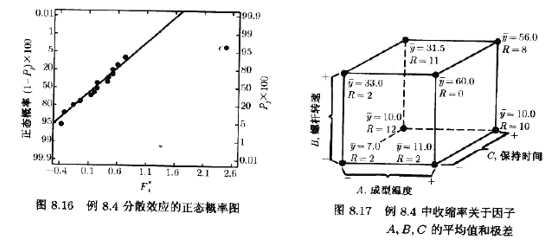
我们知道,如某因子i处于高(+)水平和低(-)水平时,残差的方差相符,则此比值近似服从均值为零的正态分布,所以可用它来判断因子i处于两个水平时响应变异性的差异,因为比值F*C相对较大,我们的结论是,从图8.15观测到的分散效应或变异性效应是真实的。这样一来,在生产中,使保持时间处于低水平就会减少零件之间收缩率的变异性。图8.16是表8.12的F*i值的正态概率图,此图也显示出因子C有较大的分散效应。
图8.17显示了此实验中的数据投影到因子A,B,C的立方体上。收缩率观测值的平均值和极差都在立方体的每个角点上标出。审查一下这张图就会看到,进行生产时,使螺杆转速(B)处于低水平,是减少零件平均收缩率的关键。实际上,当B处于低水平时,温度(A)和保特时间(C)的任一组合都会使零件的平均收缩率取小的数值。不过,检查一下立方体每个角点上收缩率的极差,就会马上看到,如果在生产时想要保持零件之间收缩率变异性取低值的话,使保持时间(C)处于低水平是唯一合理的选择。


















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











