






目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于图像处理的南瓜花授粉检测方法研究
项目背景
南瓜作为一种重要的农作物,其花授粉的成功与否直接影响着产量和品质。南瓜花的授粉过程通常依赖于自然授粉者(如蜜蜂等昆虫)及人工辅助授粉。然而,由于环境变化、授粉者数量减少等原因,南瓜花的授粉效率可能受到影响,导致产量下降。因此,开发一种高效的南瓜花授粉检测系统,可以实时监测授粉状态,帮助农民及时采取措施,以保证授粉的成功率和作物的产量。通过应用深度学习和计算机视觉技术,利用图像处理方法对南瓜花的授粉状态进行自动检测,不仅能够减轻农民的工作负担,也能提高农业生产的智能化水平,推动现代农业的发展。
数据集
南瓜花授粉数据集的制作过程首先涉及图像采集。图像可以通过自主拍摄和互联网采集的方式获取。自主拍摄时,选择在大棚中采集南瓜花的图像,确保不同角度的光照和背景条件,以便捕捉南瓜花授粉过程中的多样性和复杂性。

数据标注环节使用LabelImg进行处理。在这一过程中,首先需要整理采集到的图像,去除模糊和重复的图片,确保数据集的质量。通过LabelImg开源软件对数据集中的每一张图像进行手动标注,该软件是基于Python语言编写的,采用QT制作图形界面,用户友好。

在进行图像标注前,需要将数据集图像存放在一个独立的文件夹中,并在其目录下新建一个文件夹用于存放标注后生成的标签数据。这样可以保证标注过程的有序进行,便于后续的数据管理和训练模型的准备。通过这种方式,创建的南瓜花授粉数据集将为模型的训练提供丰富的样本和精确的标签。
设计思路
卷积神经网络的基本结构通常由输入层、卷积层、池化层、全连接层、输出层以及激活函数等组成。输入层是卷积神经网络的第一层,主要任务是将数据输入到卷积层。
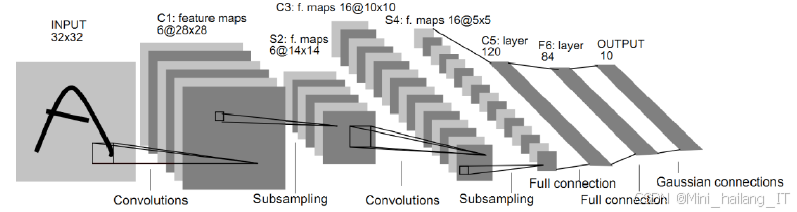
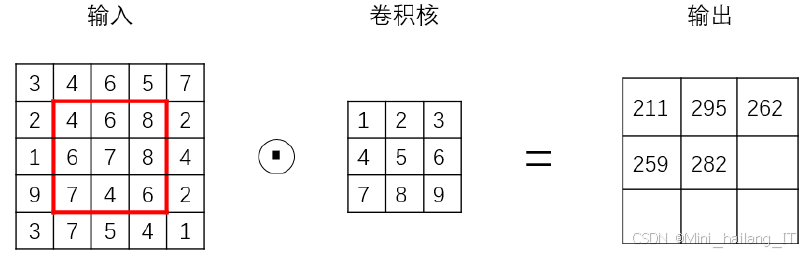
卷积层是卷积神经网络中最重要的一层,利用卷积核在二维特征矩阵上的滑动,对局部进行线性加权计算,达到提取特征信息的目的。不同的卷积核提取到的颜色、纹理等特征信息各不相同,较大的卷积核可以提取更复杂的特征,较小的卷积核则更能表现底层特征。为了在卷积前后保持二维特征的尺寸不变,通常会进行填充,填充方法包括按0填充和重复边界填充。在卷积过程中,卷积核的大小通常为3×3,步长为1。当步长不为1时,卷积核可能无法到达边缘,为避免这种情况,通常会对边缘进行补零。
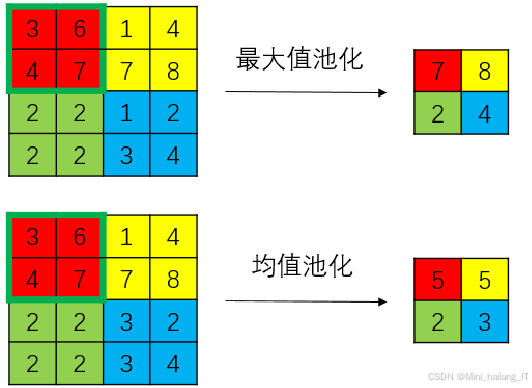
池化层又称下采样层或降采样层,位于卷积层之后,主要用于过滤无用信息和筛选特征量,从而提高网络的运行速度,同时降低过拟合的概率。池化过程与卷积相似,通过滑动核在输入的特征矩阵上以设定的步长进行平移,并进行池化计算。目前常用的池化方法包括最大池化、随机池化和平均池化等。
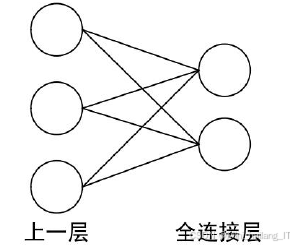
全连接层通常位于池化层后,其主要作用是将卷积和池化得到的高层特征拉平成一维特征,并与前面的特征量依次连接,其中每一个连接代表一个权值,起到权值共享的作用。输出层位于整个卷积神经网络的最后,通过分类器对全连接层的输出进行转化,将分类结果与网络的各类别进行概率对应,输出与对应程度最大的一类。
卷积神经网络中,几乎每一层的运算都是线性运算,线性运算的叠加仍然是线性运算,这样的神经网络在解决线性问题时效果较好,但在面对大量的非线性分类问题时则显得不足,此时需要引入激活函数,以增加卷积神经网络的非线性处理能力,提升特征表达能力。
YOLO的全称为You Only Look Once,YOLO算法只需一次处理即可获得图像中物体的种类和位置信息,完成目标检测任务。此类目标检测算法属于单阶段目标检测算法。YOLO算法的主要流程为:首先将输入图像统一缩放到448×448大小,然后将图像送入卷积神经网络,通过网络得到整张图像的特征图。网络将特征图平均分为S×S个网格,根据特征图分析是否有目标的中心落在该网格内。如果有,该网格负责该目标的预测,以该网格为中心生成B个预测边框。每个预测边框提供自身的中心坐标、宽高以及置信度,同时还得出预测的目标类别信息。最后,通过生成的预测框与真实目标边框的交并比筛选并输出预测值。
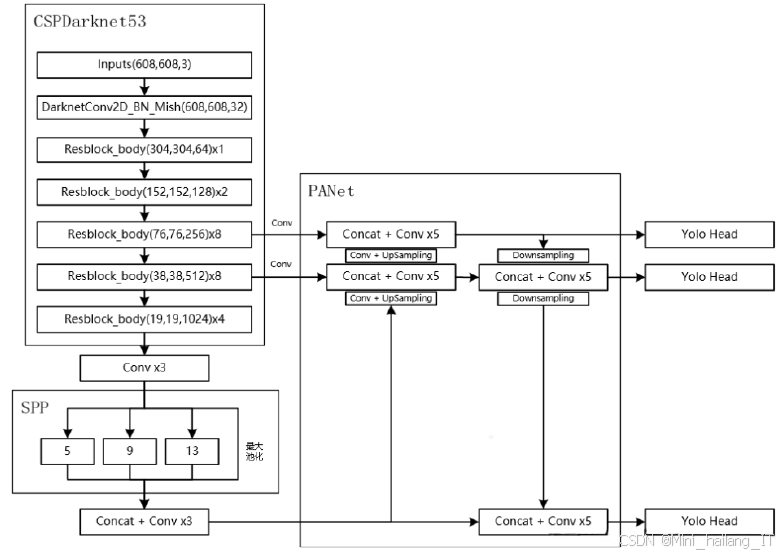
YOLOv5算法相对于YOLOv4算法最大的改进在于锚框的设置采用自适应生成方式。与YOLOv4中锚框的初始值在每次训练前需要单独运行程序不同,YOLOv5将此功能嵌入代码中,每次训练时自适应计算不同训练集中的最佳锚框值。此外,YOLOv5在其他方面也进行了改进,如自适应图片缩放。在训练阶段,如果图片尺寸不同,需要缩减到统一尺寸后添加黑边,YOLOv5采用缩减黑边的方法来提高推理速度。网络结构方面进行了微调,主干网络引入Focus结构完成切片操作,颈部网络中加入CSP结构提高特征融合,同时将YOLOv4中的预测边框损失函数CIOU_Loss替换为GIOU_Loss。YOLOv5相较于YOLOv4在检测性能上得到了提升。
南瓜花授粉数据可以通过拍摄南瓜花授粉过程的视频或图片获取。数据应包括不同条件下的授粉状态,以确保模型的泛化能力。使用标注工具对收集到的图像进行标注,标注南瓜花的授粉状态,并生成相应的标签文件(如XML或JSON格式)。在完成数据收集和标注后,需要将数据集划分为训练集、验证集和测试集。常用的划分比例为70%用于训练,15%用于验证,15%用于测试。此外,对图像数据进行规范化处理,如调整图像尺寸、归一化像素值等,以便输入到模型中。为了提高模型的鲁棒性,可以对训练数据进行数据增强。这包括旋转、缩放、平移、翻转和颜色调整等操作。
import cv2
import os
def collect_data(video_path, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cap = cv2.VideoCapture(video_path)
count = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
cv2.imwrite(os.path.join(output_dir, f"image_{count}.jpg"), frame)
count += 1
cap.release()
collect_data('pumpkin_pollination_video.mp4', 'pumpkin_flower_images')选择合适的深度学习模型(如YOLOv5)进行训练。定义模型结构后,使用训练集进行训练,并使用验证集进行实时监测,以调整超参数和防止过拟合。在训练完成后,使用测试集对模型进行评估。根据评估结果,分析模型的性能,并进行必要的调优,例如调整学习率、增加正则化或尝试不同的网络架构。
from yolov5 import train
train.run(data='data.yaml', # 数据集配置文件
weights='yolov5s.pt', # 预训练权重
epochs=50,
batch_size=16)在目标检测中,常用的评价指标包括交并比(IoU)、混淆矩阵、准确率、精确率、召回率、平均精度(AP)和平均精度均值(mAP)。通过计算这些指标,可以全面评估模型的性能。
# 伪代码示例,展示如何计算评价指标
def calculate_metrics(predictions, ground_truths):
# 计算IoU、精确率、召回率等
# ...
return metrics
metrics = calculate_metrics(predictions, ground_truths)
print(metrics)将训练好的模型应用于实时监测系统中,通过摄像头实时捕捉南瓜花授粉过程,并进行行为识别。这可以通过将图像输入到模型中,并输出相应的授粉状态来实现。
def predict_pollination_status(frame):
processed_frame = preprocess(frame) # 预处理函数
predictions = model.predict(np.expand_dims(processed_frame, axis=0))
return np.argmax(predictions)
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
status = predict_pollination_status(frame)
# 处理和展示识别结果
# ...
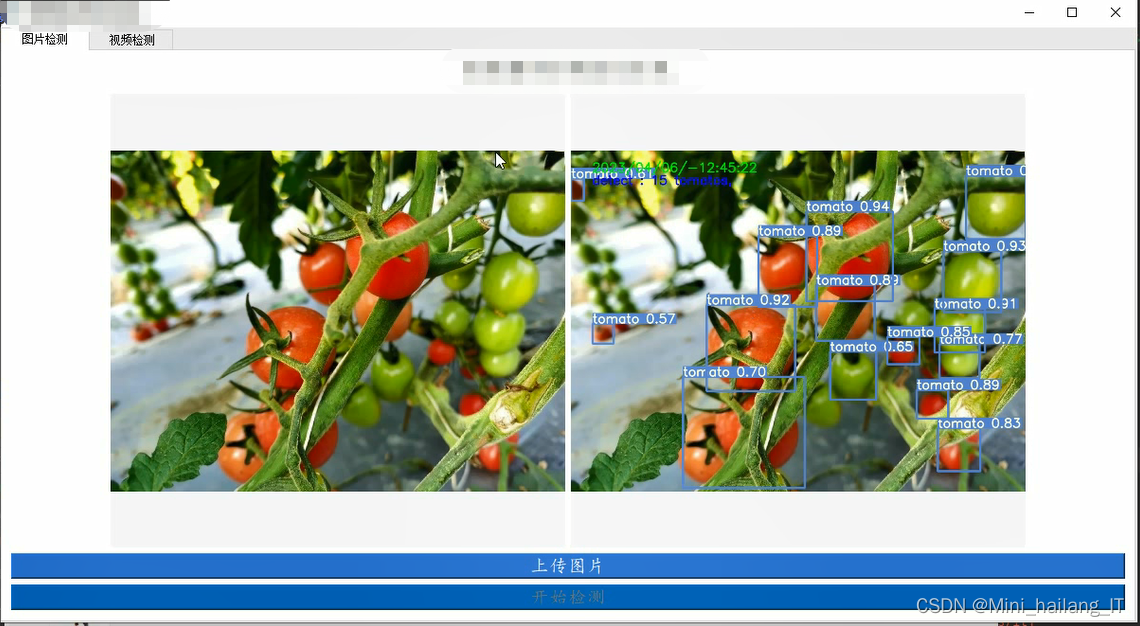
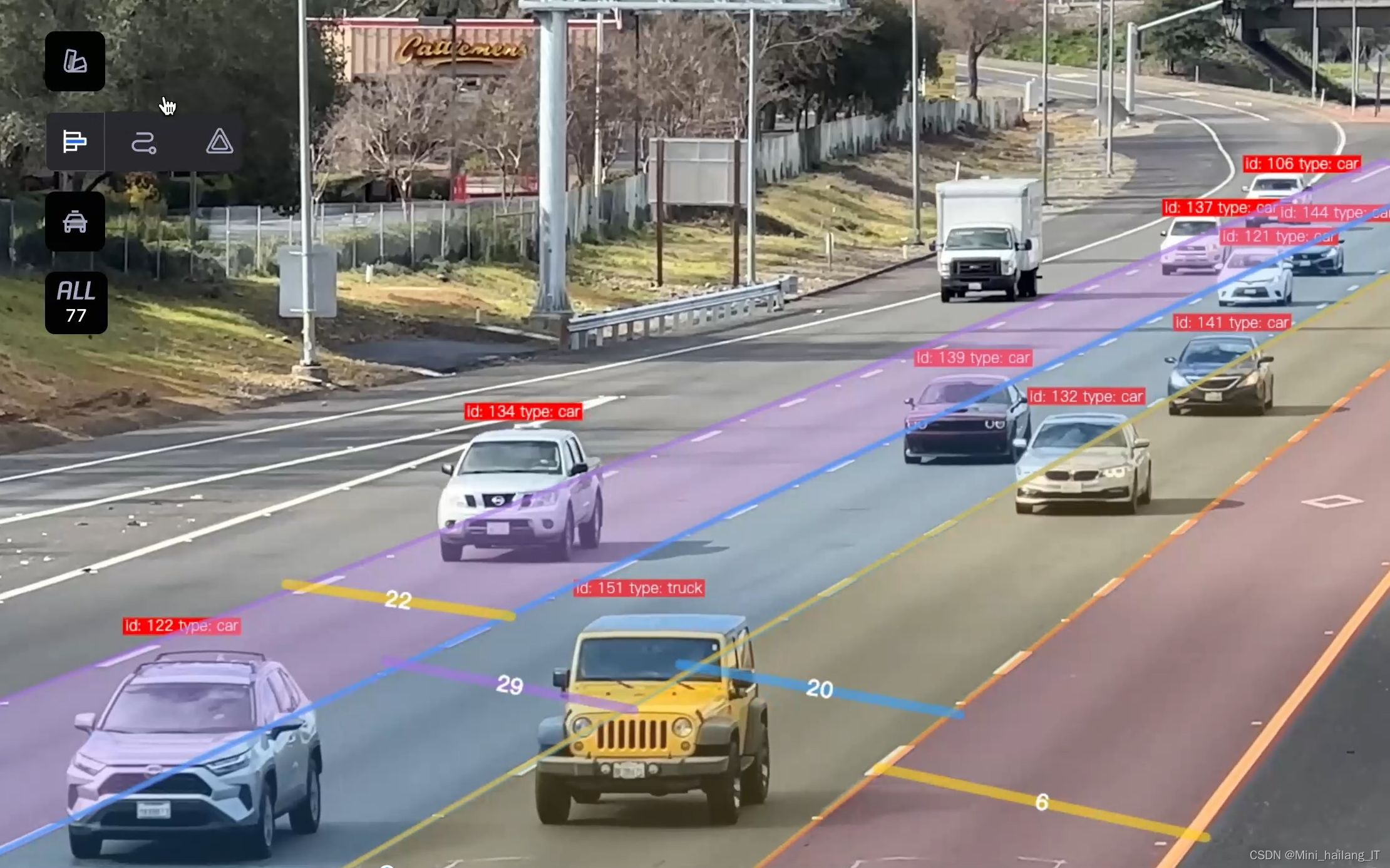
cap.release()海浪学长项目示例:




















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









