







背景
之前都是标准的表格建模和时间序列的预测,现在做一点不一样的数据结构的模型方法。
推荐系统一直是想学想做的,以前读研时候想学没多少相关代码,现在AI资源多了,虽然上班没用到这方面的知识,但是还是想熟悉一下这方面的内容,就找了这么一个电影数据集学习一下,深度学习框架也是自己熟悉的Tensorflow,就做个推荐系统的数据案例分享一下。
数据介绍
数据表很多,主要是电影的基本信息,评分,关键词等等,多个表里面,下面代码可以需要预处理一下。
因为是推荐系统嘛,所以还有用户ID编号,要给用户推荐的,整体数据表比较多,但是基本也是可以直接用某一个组件进行合并关联,最后整理为一张大表的表格的二维数据,其还是结构化的、标准化的数据,没有那么的抽象。
当然,本篇博客的所有代码文件和案例数据获取还是可以参考:推荐系统
代码实现
推荐系统本质上是一种旨在向用户推荐相关项目的系统/模型/算法。它可以是电影、音乐等等。一般来说,当涉及到用户与服务提供商或买家与电子商务之间的关系时,就非常需要推荐。最终良好的推荐将是一个双赢的解决方案,对双方都有利,因为用户会因为得到了他们想要的东西而更有面子,而服务提供商也会获得更多利润。你可能会思考这些推荐的影响有多大?事实上影响非常大。
McKindsey 指出,推荐在以下方面发挥着至关重要的作用:
- Google Play 上 40% 的应用程序安装率
- Youtube上60% 的观看时间
- 35% 的亚马逊购买量
- 在 Netflix 上观看的电影中75%
在本案例中,我们将使用两种方法来构建电影推荐系统,即内容推荐和使用 tensorflow 框架的深度学习。
安装库准备
- 本文深度学习框架基于TensorFlow,不会安装可以参考我的博客:Anaconda安装和深度学习环境的安装(TensorFlow、Pytorch)_anaconda python 深度学习环境 pytorch tensorflow-CSDN博客
- 推荐系统框是tensorflow-recommenders,它需要安装和TensorFlow对应的版本
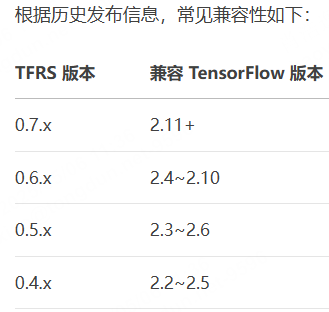
我TensorFlow比较老,2.7,所以我安装0.6版本, TensorFlow2.11以上版本直接装最新的就好了。
#!pip install tensorflow-recommenders==0.6.0安装好了之后就可以写代码了。
数据探索性分析
首先,EDA 可以让我们了解我们正在处理的数据。从数据中获得一些见解、信息甚至错误也是很有用的
导入包
import string,re
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_recommenders as tfrs
from collections import Counter
from typing import Dict, Text
from ast import literal_eval
from datetime import datetime
from wordcloud import WordCloud
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号
#import warnings
#warnings.filterwarnings('ignore')读取数据
先把这三个数据文件读取了,然后按照ID进行合并。
credits = pd.read_csv('./movies_data/credits.csv')
keywords = pd.read_csv('./movies_data/keywords.csv')
movies = pd.read_csv('./movies_data/movies_metadata.csv').\
drop(['belongs_to_collection', 'homepage', 'imdb_id', 'poster_path', 'status', 'title', 'video'], axis=1).\
drop([19730, 29503, 35587]) # Incorrect data type
movies['id'] = movies['id'].astype('int64')
# 合并
df = movies.merge(keywords, on='id').merge(credits, on='id')
#缺失处理一下
df['original_language'] = df['original_language'].fillna('')
df['runtime'] = df['runtime'].fillna(0)
df['tagline'] = df['tagline'].fillna('')
df.dropna(inplace=True)预处理
因为有的列是json字符串,包含很多内容,需要进行一定的预处理
def get_text(text, obj='name'): #json字符串解析
items = literal_eval(text) # 直接转换为列表
values = [item[obj] for item in items] # 列表推导式提取值
return ', '.join(values) if len(values) > 1 else values[0] if values else None
df['genres'] = df['genres'].apply(get_text)
df['production_companies'] = df['production_companies'].apply(get_text)
df['production_countries'] = df['production_countries'].apply(get_text)
df['crew'] = df['crew'].apply(get_text)
df['spoken_languages'] = df['spoken_languages'].apply(get_text)
df['keywords'] = df['keywords'].apply(get_text)
# New columns
df['characters'] = df['cast'].apply(get_text, obj='character')
df['actors'] = df['cast'].apply(get_text)
# 删除cast列
df.drop('cast', axis=1, inplace=True)
df = df[~df['original_title'].duplicated()].reset_index(drop=True) #去重与重置索引洗完查看一下
df.head()
查看你数据框的信息
df.info()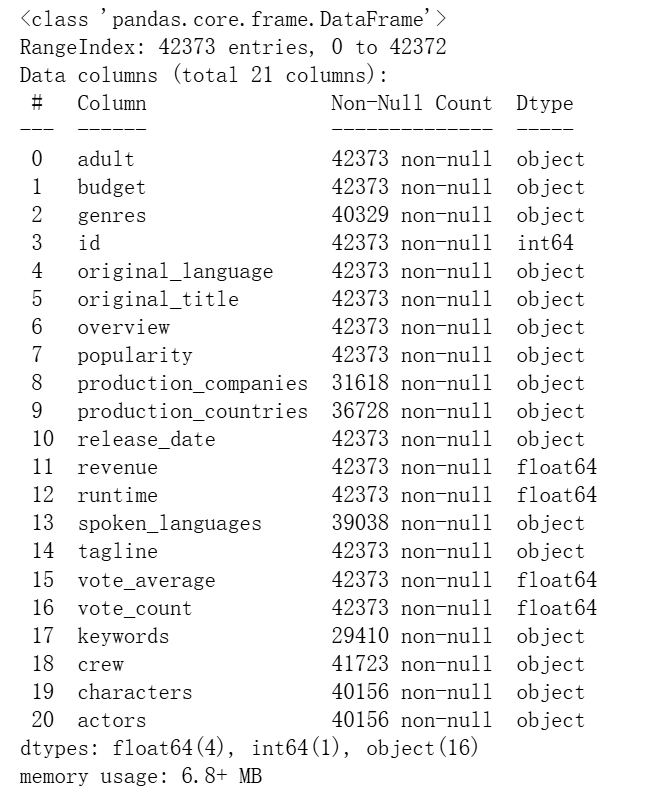
可以看到数据20多列,有的列缺失率高一点,42372行数据样本。
把对应的有的数据类型转化一下
# 类型转化一下
df['release_date'] = pd.to_datetime(df['release_date'])
df['budget'] = df['budget'].astype('float')
df['popularity'] = df['popularity'].astype('float')下面进行一些探索性分析,画点图。
可视化 1
plt.figure(figsize=(8,4))
plt.scatter(x=[0.5, 1.5], y=[1,1], s=15000, color=['#06837f', '#fdc100'])
plt.xlim(0,2)
plt.ylim(0.9,1.2)
plt.title('儿童和非儿童电影', fontsize=18, color='#333d29')
plt.text(0.5, 1, '{}\nMovies'.format(str(len(df[df['adult']=='True']))), va='center', ha='center', fontsize=18, weight=600, color='white')
plt.text(1.5, 1, '{}\nMovies'.format(str(len(df[df['adult']=='False']))), va='center', ha='center', fontsize=18, weight=600, color='white')
plt.text(0.5, 1.11, 'Adult', va='center', ha='center', fontsize=17, weight=500, color='#1c2541')
plt.text(1.5, 1.11, 'Non Adult', va='center', ha='center', fontsize=17, weight=500, color='#1c2541')
plt.axis('off')
可以看到两类电影数量差异较大。
可视化 2
df_plot = df[(df['budget'] != 0) & (df['revenue'] != 0)]
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4))
plt.suptitle('预算和收入对电影受欢迎程度的影响', fontsize=18, weight=600, color='#333d29')
for i, col in enumerate(['budget', 'revenue']):
sns.regplot(data=df_plot, x=col, y='popularity',
scatter_kws={"color": "#06837f", "alpha": 0.6}, line_kws={"color": "#fdc100"}, ax=axes[i])
plt.tight_layout()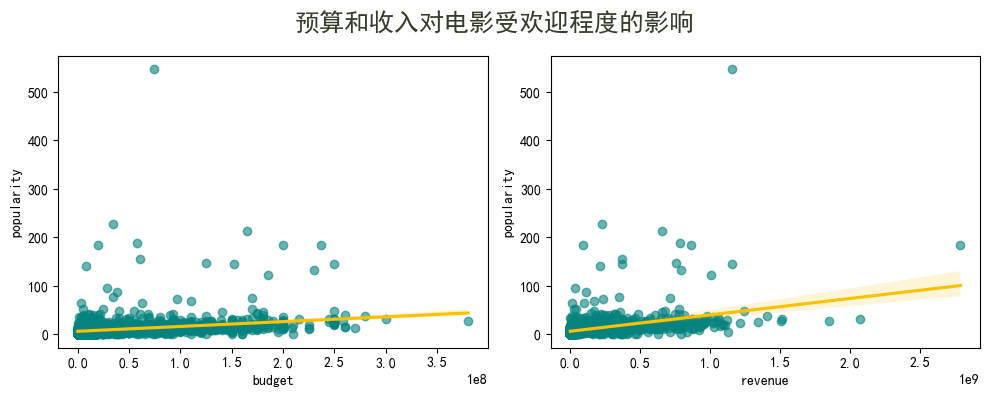
- 预算和收入对电影受欢迎程度的影响微乎其微
可视化 3
ax = sns.jointplot(data=df[(df['budget'] != 0) & (df['revenue'] != 0)], x='budget', y='revenue',
marker="+", s=100, marginal_kws=dict(bins=20, fill=False), color='#06837f')
ax.fig.suptitle('预算 vs 收入', fontsize=18, weight=600, color='#333d29')
ax.ax_joint.set_xlim(0, 1e9)
ax.ax_joint.set_ylim(0, 3e9)
ax.ax_joint.axline((1,1), slope=1, color='#fdc100')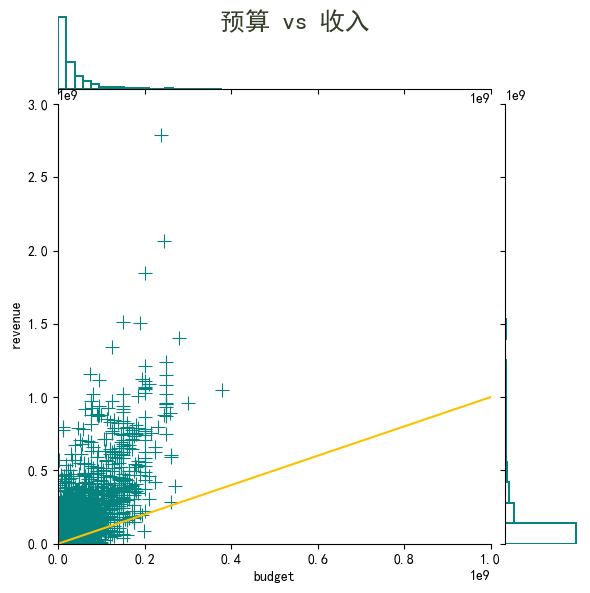
- 大部分电影位于黄线上方,表明这些电影盈利
可视化 4
plt.figure(figsize=(10,10),dpi=128)
plt.title('电影概述中最常见的词汇\n', fontsize=20, weight=400, color='#333d29')
wc = WordCloud(max_words=1000, min_font_size=10,
height=800,width=1600,background_color="white").generate(' '.join(df['overview']))
plt.imshow(wc)
- "life", "one", "find", "love"这些等词在许多场合出现较多
可视化 5
genres_list = []
for i in df['genres']:
if i:
genres_list.extend(i.split(', '))
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,5),dpi=128)
df_plot = pd.DataFrame(Counter(genres_list).most_common(5), columns=['genre', 'total'])
ax = sns.barplot(data=df_plot, x='genre', y='total', ax=axes[0], palette=['#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811'])
ax.set_title('电影最常见的5类', fontsize=18, weight=600, color='#333d29')
sns.despine()
df_plot_full = pd.DataFrame([Counter(genres_list)]).transpose().sort_values(by=0, ascending=False)
df_plot.loc[len(df_plot)] = {'genre': 'Others', 'total':df_plot_full[6:].sum()[0]}
plt.title('电影类别占比', fontsize=18, weight=600, color='#333d29')
wedges, texts, autotexts = axes[1].pie(x=df_plot['total'], labels=df_plot['genre'], autopct='%.2f%%',
textprops=dict(fontsize=14), explode=[0,0,0,0,0,0.1], colors=['#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811', '#fdc100'])
for autotext in autotexts:
autotext.set_color('#1c2541')
autotext.set_weight('bold')
axes[1].axis('off')
plt.show()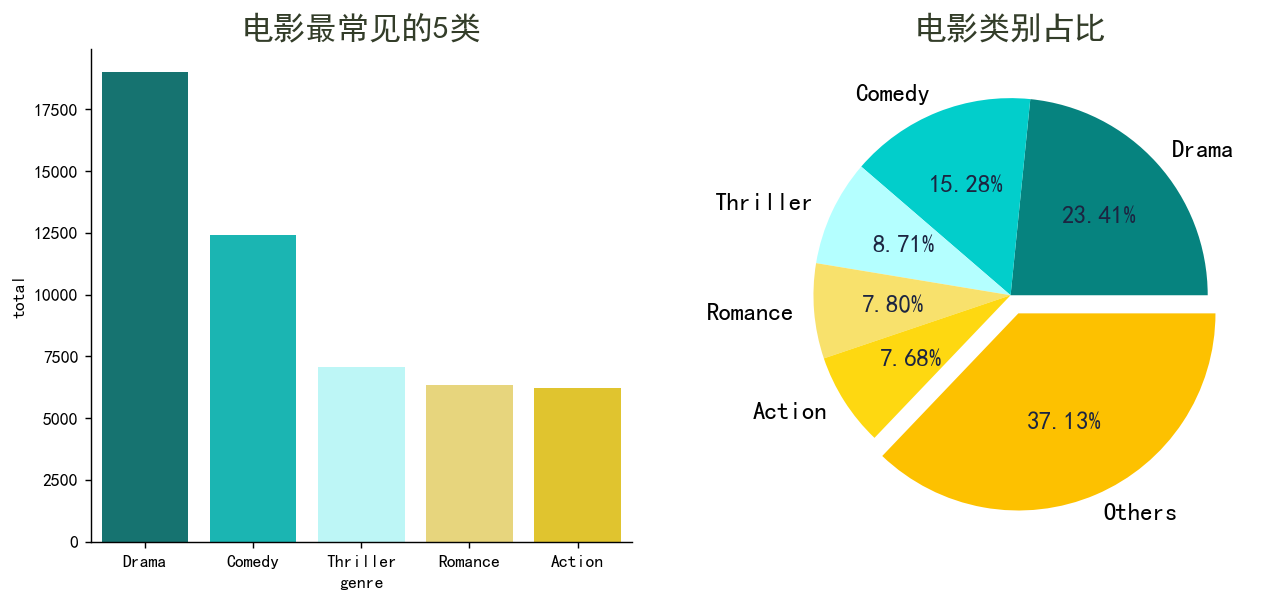
- 戏剧是最主要的类型,有 18000 多部电影
- 除了在 5 种最主要的类型外,数据集中还有许多类型电影。它们占电影类型总数的 38.67
可视化 6
sns.displot(data=df, x='release_date', kind='hist', kde=True,
color='#fdc100', facecolor='#06837f', edgecolor='#64b6ac', line_kws={'lw': 3}, aspect=3)
plt.title('电影发行日期变化量', fontsize=15, weight=300, color='#333d29')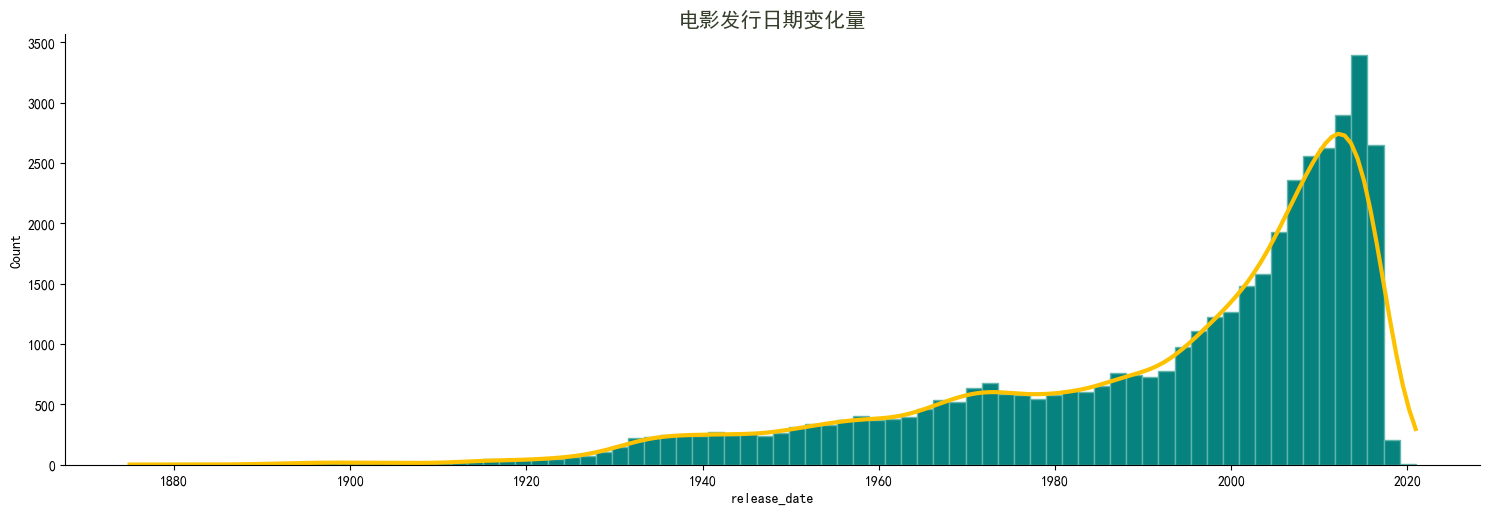
- 从 1930 年开始,电影业比 50 年前有了显著增长
- 2020 年前后上映的电影总量有所下降,是因为数据集只包含了这几年的少量数据
可视化 7
original_language_list = df['original_language'].str.split(', ').explode().dropna().tolist()
spoken_languages_list = df['spoken_languages'].str.split(', ').explode().dropna().tolist()
actors_list = df['actors'].str.split(', ').explode().dropna().tolist()
crew_list = df['crew'].str.split(', ').explode().dropna().tolist()
company_list = df['production_companies'].str.split(', ').explode().dropna().tolist()
country_list = df['production_countries'].str.split(', ').explode().dropna().tolist()fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(11, 9),dpi=128)
# Spoken language plot
df_plot1 = pd.DataFrame(Counter(spoken_languages_list).most_common(5), columns=['language', 'total']).sort_values(by='total', ascending=True)
axes[0,0].hlines(y=df_plot1['language'], xmin=0, xmax=df_plot1['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[0,0].scatter(x=df_plot1['total'], y=df_plot1['language'], s = 75, color='#fdc100')
axes[0,0].set_title('\nTop 5 Spoken Languages\nin Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot1['total']):
axes[0,0].text(value+1000, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Original Language plot
df_plot2 = pd.DataFrame(Counter(original_language_list).most_common(5), columns=['language', 'total']).sort_values(by='total', ascending=True)
axes[0,1].hlines(y=df_plot2['language'], xmin=0, xmax=df_plot2['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[0,1].scatter(x=df_plot2['total'], y=df_plot2['language'], s = 75, color='#fdc100')
axes[0,1].set_title('\nTop 5 Original Languages\nin Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot2['total']):
axes[0,1].text(value+1000, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Actor plot
df_plot3 = pd.DataFrame(Counter(actors_list).most_common(5), columns=['actor', 'total']).sort_values(by='total', ascending=True)
axes[1,0].hlines(y=df_plot3['actor'], xmin=0, xmax=df_plot3['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[1,0].scatter(x=df_plot3['total'], y=df_plot3['actor'], s = 75, color='#fdc100')
axes[1,0].set_title('\nTop 5 Actors in Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot3['total']):
axes[1,0].text(value+10, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Crew plot
df_plot4 = pd.DataFrame(Counter(crew_list).most_common(5), columns=['name', 'total']).sort_values(by='total', ascending=True)
axes[1,1].hlines(y=df_plot4['name'], xmin=0, xmax=df_plot4['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[1,1].scatter(x=df_plot4['total'], y=df_plot4['name'], s = 75, color='#fdc100')
axes[1,1].set_title('\nTop 5 Crews in Movies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot4['total']):
axes[1,1].text(value+10, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Company plot
df_plot5 = pd.DataFrame(Counter(company_list).most_common(5), columns=['name', 'total']).sort_values(by='total', ascending=True)
axes[2,0].hlines(y=df_plot5['name'], xmin=0, xmax=df_plot5['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[2,0].scatter(x=df_plot5['total'], y=df_plot5['name'], s = 75, color='#fdc100')
axes[2,0].set_title('\nTop 5 Production Companies\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot5['total']):
axes[2,0].text(value+50, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
# Country plot
df_plot6 = pd.DataFrame(Counter(country_list).most_common(5), columns=['name', 'total']).sort_values(by='total', ascending=True)
axes[2,1].hlines(y=df_plot6['name'], xmin=0, xmax=df_plot6['total'], color= '#06837f', alpha=0.7, linewidth=2)
axes[2,1].scatter(x=df_plot6['total'], y=df_plot6['name'], s = 75, color='#fdc100')
axes[2,1].set_title('\nTop 5 Production Countries\n', fontsize=15, weight=600, color='#333d29')
for i, value in enumerate(df_plot6['total']):
axes[2,1].text(value+900, i, value, va='center', fontsize=10, weight=600, color='#1c2541')
sns.despine()
plt.tight_layout()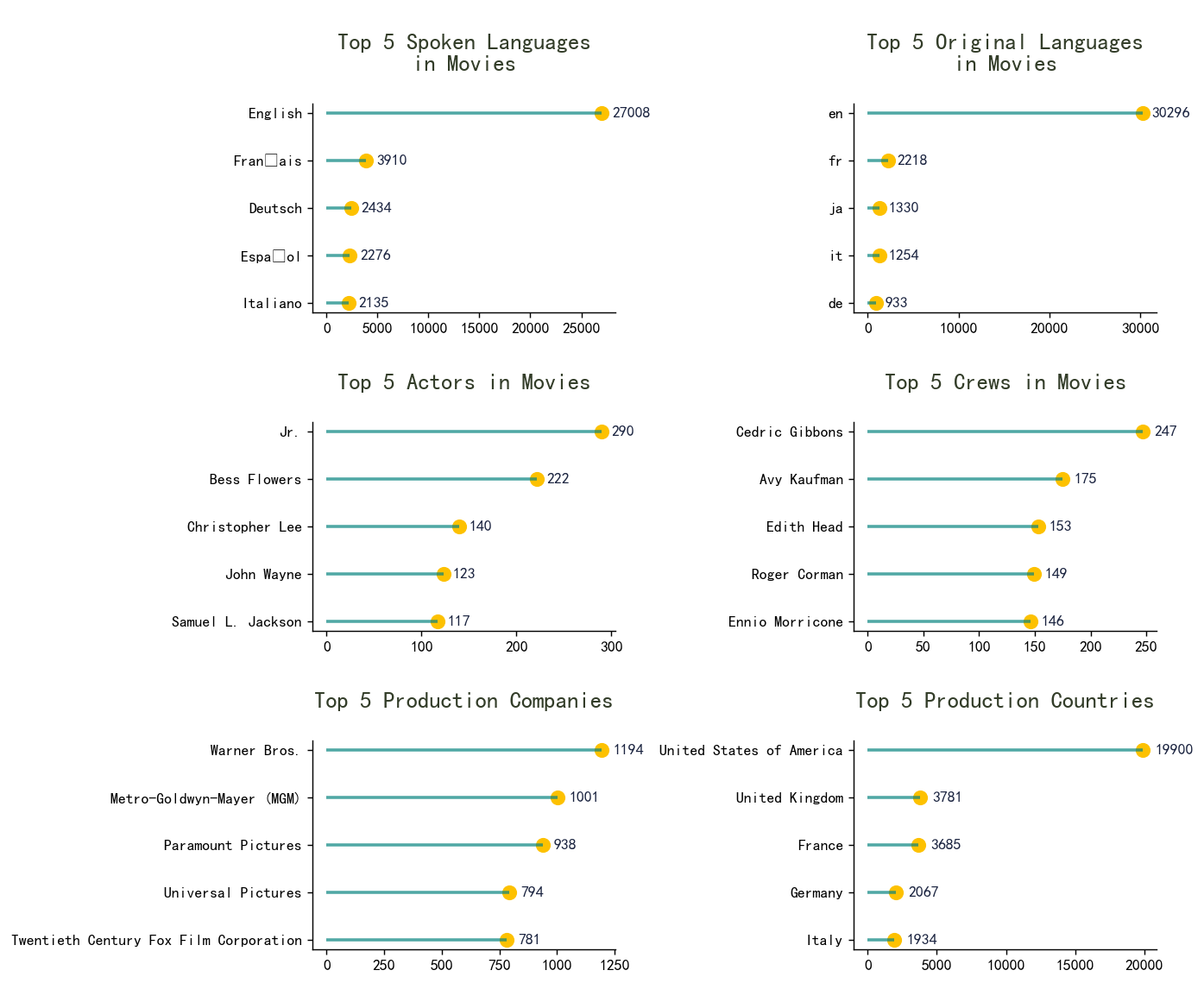
- 在此特定数据集中,英语在电影中的原语和口语中均名列榜首。
- 小吉布森和塞德里克-吉布森分别是榜单中参与电影最多的演员和工作人员
- 华纳兄弟公司以 1194 部电影成为榜单中排名第一的制片公司。
- 许多伟大的制片公司都来自美国。因此美国成为头号制片国也就不足为奇了。
可视化 8
sns.relplot(data=df, x='vote_average', y='popularity', size='vote_count',
sizes=(20, 200), alpha=.5, aspect=2, color='#06837f')
plt.title('评级与受欢迎程度之间的关系', fontsize=15, weight=600, color='#333d29')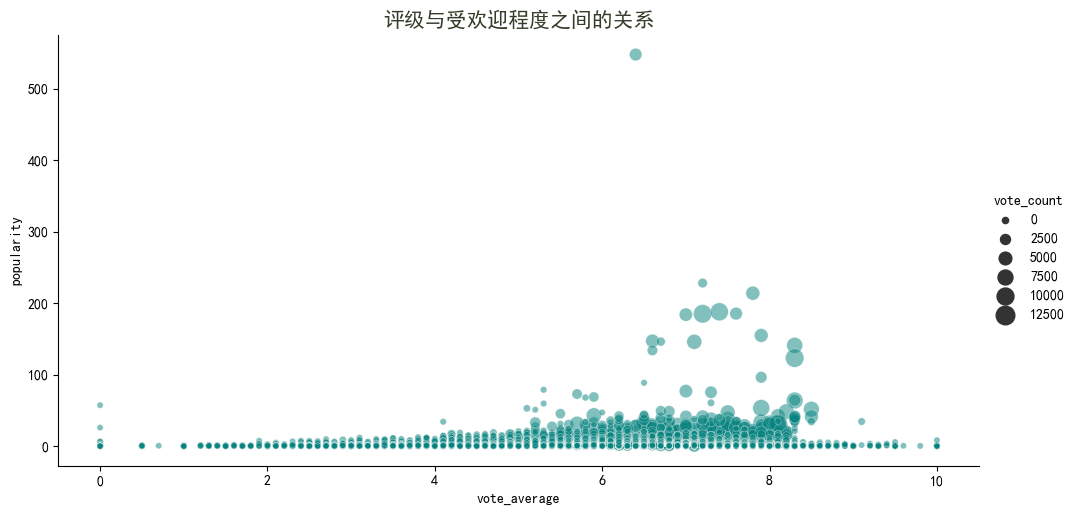
- 获得 0 分或 10 分的电影基本上都是由少数投票者造成的。随着票数的增加,评分很可能在 5 到 8.5 左右。
- 从上图可以看出,受欢迎的电影会得到更多的投票。
可视化 9
df_plot = pd.DataFrame(Counter(genres_list).most_common(5), columns=['genre', 'total'])
df_plot = df[df['genres'].isin(df_plot['genre'].to_numpy())]
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8,5),dpi=128)
plt.suptitle('前5大类别电影的数据分布', fontsize=18, weight=600, color='#333d29')
for i, y in enumerate(['runtime', 'popularity', 'budget', 'revenue']):
sns.stripplot(data=df_plot, x='genres', y=y, ax=axes.flatten()[i], hue='genres',palette=['#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811'])
plt.tight_layout()
- 电影片时长最长的电影类型是剧情片
- 前五名中最不受欢迎的类型是爱情片
- 动作片比其他电影花费更多资金
- 与其他电影相比,其中一部动作片获得了巨大的利润
可视化 10
plt.figure(figsize=(8,6),dpi=128)
plt.title('电影特征的相关性\n', fontsize=18, weight=600, color='#333d29')
sns.heatmap(df.corr(), annot=True, cmap=['#004346', '#036666', '#06837f', '#02cecb', '#b4ffff', '#f8e16c', '#fed811', '#fdc100'])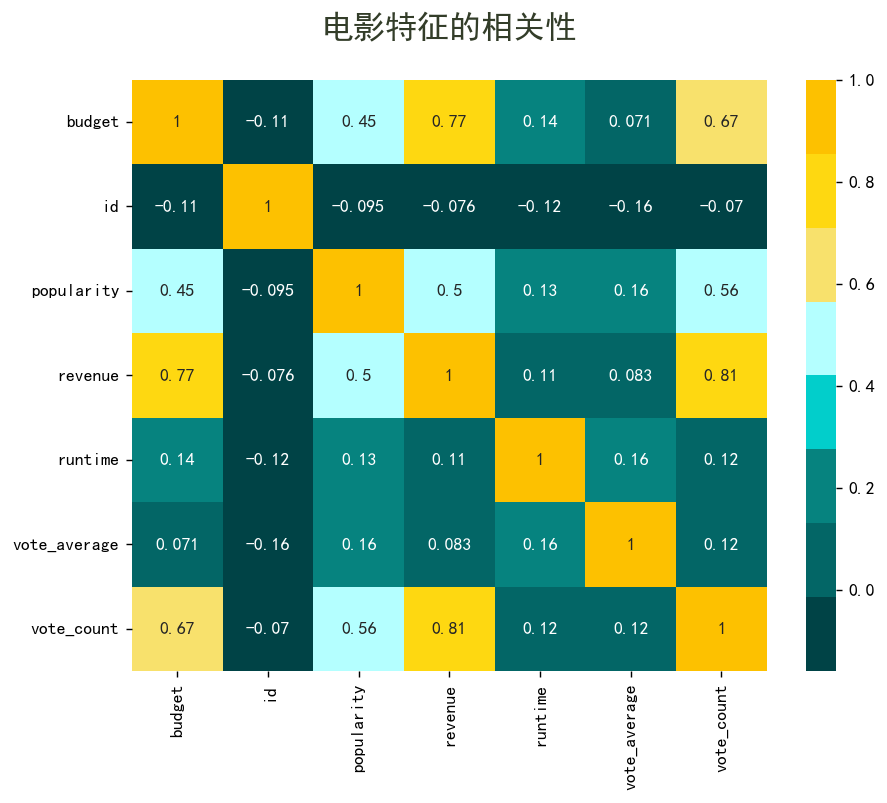
- 票数、预算和受欢迎程度是决定电影收益的三大要素
推荐系统
有很多方法可以用来构建推荐系统。本文我们将探讨其中的两种方法,您可以利用它们创建推荐系统,并根据不同的特征向用户提供推荐电影的输出结果
基于内容
对于学习过一段时间推荐系统的人来说,加权平均法可能并不陌生。它背后的理念是为每部电影给出一个 “公平 ”的评分。在本文中,我们将借助词袋模型进行加权给分。
如果你看到我们的数据集,其中有大量有价值的信息,如类型、概述等。我们将利用这些信息使推荐算法和系统更加准确。我们在词袋中提取这些信息,然后将其与加权平均值相结合,得到电影的最终相似度。

计算上面的指标
R = df['vote_average']
v = df['vote_count']
# 我们只考虑票数超过数据集中至少 80% 的影片
m = df['vote_count'].quantile(0.8)
C = df['vote_average'].mean()
df['weighted_average'] = (R*v + C*m)/(v+m)# 归一化
scaler = MinMaxScaler()
scaled = scaler.fit_transform(df[['popularity', 'weighted_average']])
weighted_df = pd.DataFrame(scaled, columns=['popularity', 'weighted_average'])
weighted_df.index = df['original_title']人们观看一部电影不仅仅是因为看到了该电影的好评分,还因为某些电影的炒作。因此,在这种情况下,考虑人气是一个明智的选择。
考虑到即使评论和评分都很差,人们也不想错过一部炒作电影,我们将平均权重取 40% ,人气权重取 60% 。你可以随意调整这个数字。接下来,我们创建一个名为 score 的新列,用于存储结果
weighted_df['score'] = weighted_df['weighted_average']*0.4 + weighted_df['popularity'].astype('float64')*0.6排序
weighted_df_sorted = weighted_df.sort_values(by='score', ascending=False)
weighted_df_sorted.head(10)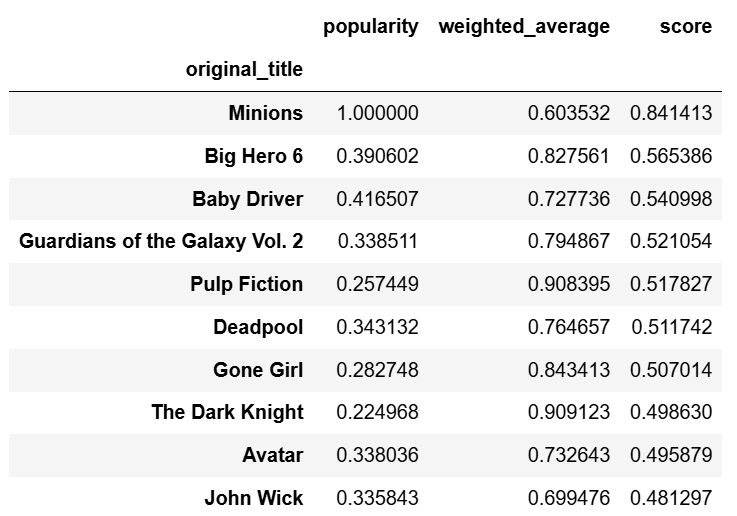
我们已经得到了推荐系统的第一个结果,接下来如前所述,我们将把这些得分与相似性得分结合起来。
content_df = df[['original_title', 'adult', 'genres', 'overview', 'production_companies', 'tagline', 'keywords', 'crew', 'characters', 'actors']].copy()自定义处理函数
def separate(text): # 逗号分隔的字符串 进行多级清洗,返回合并后的干净字符串。
clean_text = []
for t in text.split(','):
cleaned = re.sub('\(.*\)', '', t) #各种奇怪的符号
cleaned = cleaned.translate(str.maketrans('','', string.digits))
cleaned = cleaned.replace(' ', '')
cleaned = cleaned.translate(str.maketrans('','', string.punctuation)).lower()
clean_text.append(cleaned)
return ' '.join(clean_text)
def remove_punc(text): #返回无标点和数字的小写字符串
cleaned = text.translate(str.maketrans('','', string.punctuation)).lower()
clean_text = cleaned.translate(str.maketrans('','', string.digits))
return clean_text处理一下
content_df['adult'] = content_df['adult'].apply(remove_punc)
content_df['genres'] = content_df['genres'].fillna('').apply(remove_punc)
content_df['overview'] = content_df['overview'].apply(remove_punc)
content_df['production_companies'] = content_df['production_companies'].fillna('').apply(separate)
content_df['tagline'] = content_df['tagline'].apply(remove_punc)
content_df['keywords'] = content_df['keywords'].fillna('').apply(separate)
content_df['crew'] = content_df['crew'].fillna('').apply(separate)
content_df['characters'] = content_df['characters'].fillna('').apply(separate)
content_df['actors'] = content_df['actors'].fillna('').apply(separate)
content_df['bag_of_words'] = ''
content_df['bag_of_words'] = content_df[content_df.columns[1:]].apply(lambda x: ' '.join(x), axis=1) # 合并
content_df.set_index('original_title', inplace=True)
content_df = content_df[['bag_of_words']]
content_df.head()
查找两部电影相似度的常用方法是余弦相似度法。当然还可以尝试多种方法,如欧几里得法和西格玛法,以了解哪种方法效果最好。
不过计算所有影片的相似度需要耗费大量资源。因此由于内存有限,我们只从 weighted_df_sorted 中提取了前 10000 部影片
content_df = weighted_df_sorted[:10000].merge(content_df, left_index=True, right_index=True, how='left')
# tfidf词向量化
tfidf = TfidfVectorizer(stop_words='english', min_df=5)
tfidf_matrix = tfidf.fit_transform(content_df['bag_of_words'])
tfidf_matrix.shape## 转为相似度矩阵
cos_sim = cosine_similarity(tfidf_matrix)
cos_sim.shapecontent_df.head()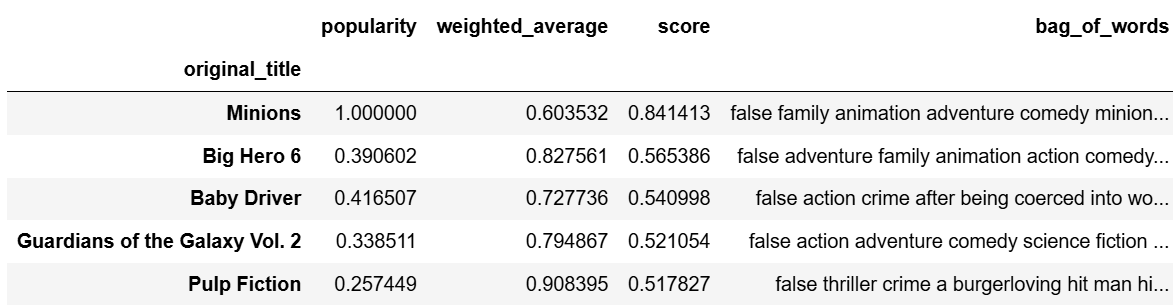
自定义预测推荐函数
#根据电影标题,结合 内容相似度 和 原始评分,计算加权综合得分,返回 Top-N 推荐电影。
def predict(title, similarity_weight=0.7, top_n=10): # 输入标题,相似度权重,推荐电影的数量
data = content_df.reset_index()
index_movie = data[data['original_title'] == title].index
similarity = cos_sim[index_movie].T
sim_df = pd.DataFrame(similarity, columns=['similarity'])
final_df = pd.concat([data, sim_df], axis=1)
#可以调整阈值
final_df['final_score'] = final_df['score']*(1-similarity_weight) + final_df['similarity']*similarity_weight
final_df_sorted = final_df.sort_values(by='final_score', ascending=False).head(top_n)
final_df_sorted.set_index('original_title', inplace=True)
return final_df_sorted[['score', 'similarity', 'final_score']]打印结果
predict('Toy Story', similarity_weight=0.7, top_n=10)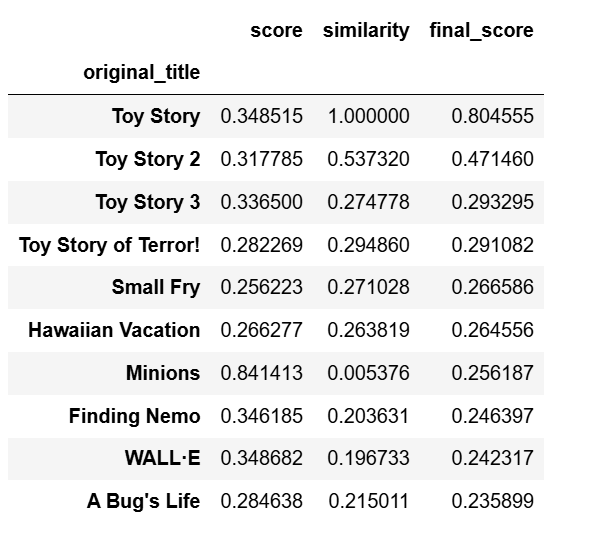
这样就基于内容可以推荐10部和这个电影类似的电影了。
# 可以储这个内容表
# content_df.to_csv('content_df.csv')深度学习
到了本文的重点模型了!
官方文档: https://www.tensorflow.org/recommenders
Tensorflow 自带一个名为 TensorFlow Recommenders (TFRS) 的库,用于构建推荐系统。该库基于 Keras 构建,其学习难度较为容易,同时还能灵活地构建复杂的模型。
本文我们采用多目标方法(双损失函数),同时应用隐式信号(喜欢观看的电影排名)和显式信号(评分)。最后可以根据历史数据预测用户应该观看哪些与给定评分相对应的电影 。
我们首先读取评分数据
# 评分数据
ratings_df = pd.read_csv('./movies_data/ratings_small.csv')
#时间转化
ratings_df['date'] = ratings_df['timestamp'].apply(lambda x: datetime.fromtimestamp(x))
ratings_df.drop('timestamp', axis=1, inplace=True)
# 合并
ratings_df = ratings_df.merge(df[['id', 'original_title', 'genres', 'overview']], left_on='movieId',right_on='id', how='left')
ratings_df = ratings_df[~ratings_df['id'].isna()]
ratings_df.drop('id', axis=1, inplace=True)
ratings_df.reset_index(drop=True, inplace=True)
ratings_df.head() 
取出电影的ID和标题
# 电影ID和标题
movies_df = df[['id', 'original_title']].copy()
movies_df.rename(columns={'id':'movieId'}, inplace=True)
movies_df.head()
构建tf数据:
ratings_df['userId'] = ratings_df['userId'].astype('str')
# 转为tf数据
ratings = tf.data.Dataset.from_tensor_slices(dict(ratings_df[['userId', 'original_title', 'rating']]))
movies = tf.data.Dataset.from_tensor_slices(dict(movies_df[['original_title']]))
ratings = ratings.map(lambda x: {
"original_title": x["original_title"],
"userId": x["userId"],
"rating": float(x["rating"])
})
movies = movies.map(lambda x: x["original_title"])# 划分数据
print('Total Data: {}'.format(len(ratings)))
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = ratings.take(35_000) #训练集3.5w
test = ratings.skip(35_000).take(8_188) #测试集剩下的 8188条## 获取唯一取值列表,因为模型需要嵌入电影和用户的唯一取值的列表。
movie_titles = movies.batch(1_000) # 每次批量加载1,000个电影标题
user_ids = ratings.batch(1_000).map(lambda x: x["userId"])
unique_movie_titles = np.unique(np.concatenate(list(movie_titles)))
unique_user_ids = np.unique(np.concatenate(list(user_ids)))
print('Unique Movies: {}'.format(len(unique_movie_titles))) #查看唯一数量
print('Unique users: {}'.format(len(unique_user_ids))) 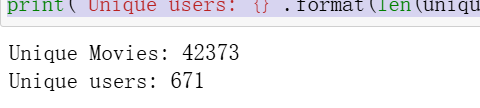
定义模型,这模型有两个功能,推荐和预测评分,所以也是双损失函数。具体逻辑看注释:
class MovieModel(tfrs.models.Model):
def __init__(self, rating_weight: float, retrieval_weight: float) -> None:
# 我们在构造函数中获取损失权重:这样我们就可以实例化。
# 多个具有不同损失权重的模型对象—— rating_weight:评分预测任务的损失权重。 retrieval_weight:检索任务的损失权重。
super().__init__()
embedding_dimension = 64 # 嵌入层输出维度
# 用户电影模型
self.movie_model: tf.keras.layers.Layer = tf.keras.Sequential([ # 电影名称转为向量
tf.keras.layers.StringLookup( vocabulary=unique_movie_titles, mask_token=None), #StringLookup:将电影标题/用户ID转换为整数索引(类似 LabelEncoder
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, embedding_dimension)
])
self.user_model: tf.keras.layers.Layer = tf.keras.Sequential([ #用户ID转为向量
tf.keras.layers.StringLookup( vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, embedding_dimension)
])
# 一个小型模型,用于接收用户和电影嵌入信息并预测评分。
# 只要输出一个标量作为我们的预测值。
self.rating_model = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dense(1), # # 输出单个评分值
])
# 目标 (损失函数)
self.rating_task: tf.keras.layers.Layer = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(), metrics=[tf.keras.metrics.RootMeanSquaredError()], ) # 评分任务 MSE损失
self.retrieval_task: tf.keras.layers.Layer = tfrs.tasks.Retrieval( metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.movie_model) ) #检索任务(推荐) Top-K 命中率衡量推荐质量损失
)
# 损失权重
self.rating_weight = rating_weight
self.retrieval_weight = retrieval_weight
def call(self, features: Dict[Text, tf.Tensor]) -> tf.Tensor:
# # 我们挑选出用户特征,并将其传入用户模型。
user_embeddings = self.user_model(features["userId"])
#并挑选出电影特征,将其传入电影模型。
movie_embeddings = self.movie_model(features["original_title"])
return ( user_embeddings, movie_embeddings, #返回 用户嵌入和电影嵌入
self.rating_model( tf.concat([user_embeddings, movie_embeddings], axis=1) ), ) # 返回评分的预测结果
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
ratings = features.pop("rating")
user_embeddings, movie_embeddings, rating_predictions = self(features) # 前向传播
# 每轮训练计算损失
rating_loss = self.rating_task( labels=ratings, predictions=rating_predictions, ) # 评分损失
retrieval_loss = self.retrieval_task(user_embeddings, movie_embeddings) # 推荐检索 损失
# 按照权重 合并
return (self.rating_weight * rating_loss + self.retrieval_weight * retrieval_loss)模型的工作流程示例:
-
训练时:
- 输入:{"userId": "123", "original_title": "Inception", "rating": 4.5}
-
模型:
- 生成用户和电影的嵌入。
- 预测评分(如 4.2)。
- 计算评分误差(MSE)和检索质量(Top-K)。
- 输出:加权总损失。
-
推荐时:
- 用 user_model 生成用户嵌入。
- 计算与所有电影嵌入的相似度,返回 Top-K 电影。
为什么这样设计
- 联合学习:通过共享用户/电影嵌入,评分预测和检索任务互相增强。(双损失函数)
- 灵活性:通过调整权重,可以侧重评分准确性或推荐多样性。
- 端到端:直接从原始用户ID和电影标题 输入模型学习,无需手动特征工程。
模型训练
开始模型训练!
## 模型训练
model = MovieModel(rating_weight=1.0, retrieval_weight=1.0) #两个权重均为1.0,表示两个任务对总损失的贡献相同)
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1)) #Adagrad 优化器,学习率为 0.1。Adagrad 适合稀疏数据(如推荐系统中的用户-电影交互数据)。
cached_train = train.shuffle(100_000).batch(1_000).cache() #一批1000个样本,3.5w样本要35批才算训练完一轮。
cached_test = test.batch(1_000).cache() #批量大小影响训练速度和内存占用
model.fit(cached_train, epochs=5) # 训练5轮就行,免得过拟合
这个损失函数不同于回归和分类问题的损失,是推荐系统独有的损失,检索匹配的损失函数,可以好好研究一下。这个模型是双损失函数。
测试集评估
metrics = model.evaluate(cached_test, return_dict=True) # 评估
print(f"\nRetrieval top-100 accuracy: {metrics['factorized_top_k/top_100_categorical_accuracy']:.3f}")
print(f"Ranking RMSE: {metrics['root_mean_squared_error']:.3f}")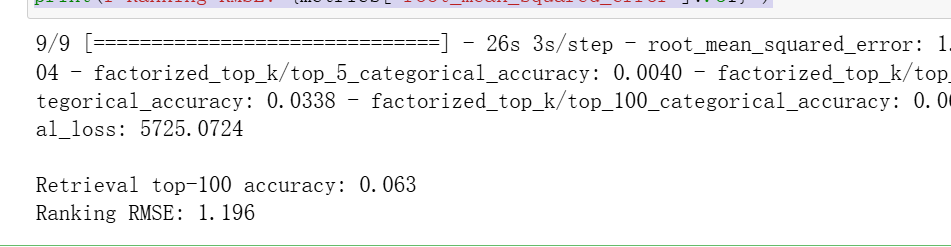
可以看到整体损失5725,和训练集第五轮5815差不多,没有过拟合。
# model.save_weights('tfrs.h5') # 可以保存这个模型文件构建预函数
def predict_movie(user, top_n=3): #据用户的ID,返回该用户可能喜欢的Top-N部电影。
# 创建暴力检索器(BruteForce),基于用户的嵌入模型
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model) #BruteForce:暴力搜索所有候选电影,计算用户与每部电影的相似度。
# 构建候选电影索引(电影标题 + 电影嵌入向量)
index.index_from_dataset(
tf.data.Dataset.zip((movies.batch(100), movies.batch(100).map(model.movie_model))) #建立电影标题和嵌入向量的映射关系
)
# 获取推荐结果
_, titles = index(tf.constant([str(user)])) # 输入用户ID
print('Top {} 电影推荐给 用户{} 如下:\n'.format(top_n, user))
for i, title in enumerate(titles[0, :top_n].numpy()):
print('{}. {}'.format(i+1, title.decode("utf-8")))
def predict_rating(user, movie): #预测用户对某电影的评分
trained_movie_embeddings, trained_user_embeddings, predicted_rating = model({
"userId": np.array([str(user)]),
"original_title": np.array([movie]) #调用模型,输入用户ID和电影标题
})
print("预测 用户{} 对于《{}》的评分: {}".format(user,movie, predicted_rating.numpy()[0][0])) #返回评分预测测试看看,先来个推荐,给123这个id用户推荐7个电影:
predict_movie(123, 7)
预测 用户123 对于《Father of the Bride Part II》的评分
predict_rating(123,'Father of the Bride Part II')
为什么会这样预测呢,让我们从 User 123 的历史数据中寻找规律
ratings_df[ratings_df['userId'] == '123']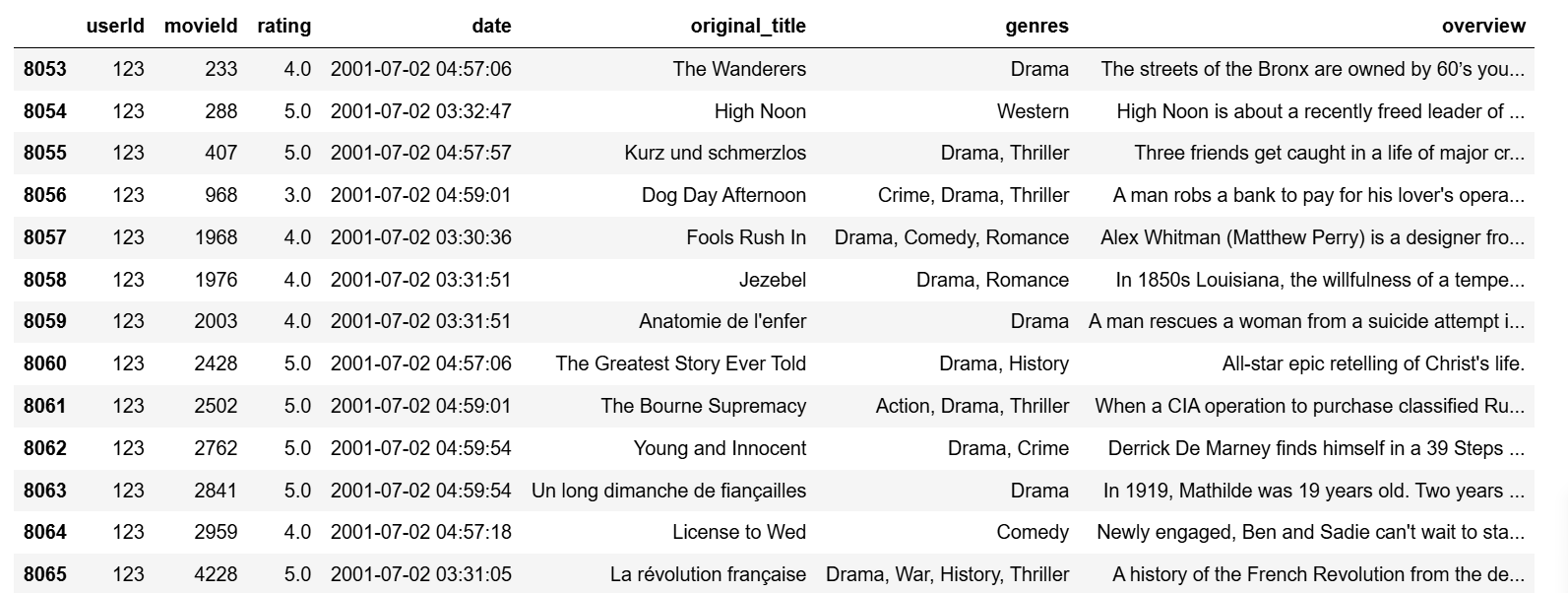
一目了然,我们可以看出用户 123 是否大部分时间都喜欢看剧情片(Drama)。ta对该类型电影的评分也很高。在我们的推荐中,我们会再给ta推荐 5 部剧情类电影,希望ta能喜欢这些和之前观看过的电影类似的电影
# 获取预测影片的元数据
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model)
#索引
index.index_from_dataset( tf.data.Dataset.zip((movies.batch(100), movies.batch(100).map(model.movie_model))) )
#获取推荐
_, titles = index(tf.constant(['123']))
pred_movies = pd.DataFrame({'original_title': [i.decode('utf-8') for i in titles[0,:5].numpy()]}) #预测推荐的前五个电影
pred_df = pred_movies.merge(ratings_df[['original_title', 'genres', 'overview']], on='original_title', how='left')
pred_df = pred_df[~pred_df['original_title'].duplicated()]
pred_df.reset_index(drop=True, inplace=True)
pred_df.index = np.arange(1, len(pred_df)+1)
# 推荐的电影
pred_df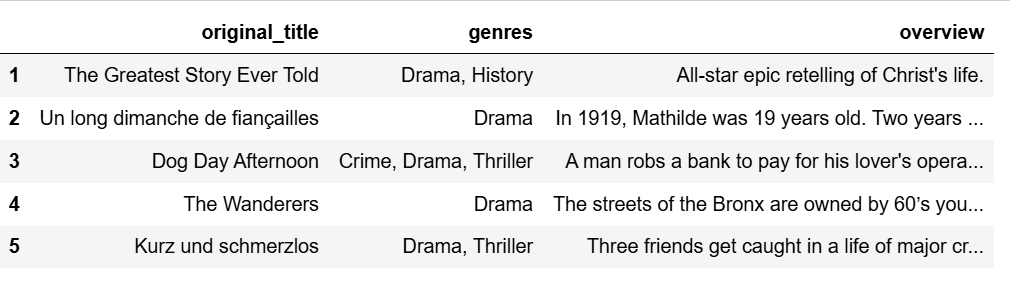
predict_rating(123,"The Wearing of the Grin") 预测 用户123 对于《The Wearing of the Grin》的评分: 2.5320346355438232。
在我们的数据集中,我们没有发现 123用户 观看过任何动画电影。所以像《古堡小精灵》的预测评分很低,也不足为奇。
(有杠精非要说2.532也不低呀.....你看看这个用户给电影打分就没低于3分的)
结论
本文主要是对这个电影数据集做了一点清洗和可视化,然后使用基于加权内容相似度的方法预测相似的电影,然后使用神经网络的方法对不同用户推荐不同的电影,预测不同用户对于不同电影的评分。是一个简单的推荐系统的数据案例。
TensorFlow Recommenders这个库最大的优势是可以直接从文本中,用户ID,电影文本中去训练,还是很方便的。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)


















 1587
1587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











