







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于LDA的游戏评论情感分析与舆情评估系统
项目背景
随着网络社交媒体和游戏行业的迅速发展,玩家通过评论和反馈表达对游戏的看法和情感,这些评论不仅对游戏开发者的决策起着重要作用,也对游戏的市场表现产生直接影响。一个高效的游戏评论舆情分析能够自动识别评论中的情感倾向和舆论热点,为游戏开发者提供优化产品和服务的依据。通过对海量评论数据的分析,不仅能够及时了解玩家的需求和反馈,还能在负面舆论出现时迅速做出反应,从而维护品牌形象和用户满意度。
数据集
选择适合的社交媒体作为数据采集的目标,这些地方聚集了大量玩家对游戏的评论和反馈,能够提供丰富的情感分析素材。使用网络爬虫技术从选定平台爬取评论数据。爬虫程序需要模拟用户行为,通过发送HTTP请求获取网页内容,并使用解析库(Scrap)提取所需的评论文本、用户ID、评论时间、评分等信息。在爬取过程中,注意设置合理的请求频率以避免对服务器造成负担。爬取到的原始评论数据通常包含噪声和不必要的信息,因此需要进行清理。清理过程包括去除HTML标签、特殊字符和无关信息(如广告、系统提示等)。同时,检查数据的完整性,确保每条评论都包含必要的字段(如文本、评分等)。
设计思路
LDA是一种生成概率模型,用于发现文档集合中潜在的主题结构。其基本假设是:每篇文档可以视为多个主题的混合,而每个主题又由一组词汇构成。LDA通过对文档进行建模,推断出每个文档中各主题的分布以及每个主题中各单词的分布。具体来说,LDA使用了Dirichlet分布作为主题和词汇的先验,采用变分推断的方法进行参数估计。通过反复迭代,LDA能够自动识别文档中的主题,并为每个文档分配一个主题分布。LDA主题模型在多个领域得到了广泛应用:
- 文本挖掘:自动生成主题标签,帮助用户理解和组织文档集合。
- 信息检索:改进搜索结果,通过识别用户查询与文档主题之间的相关性,提高检索效果。
LDA还广泛应用于社交媒体分析、推荐系统、新闻分类等场景,通过主题建模帮助挖掘用户兴趣和偏好。
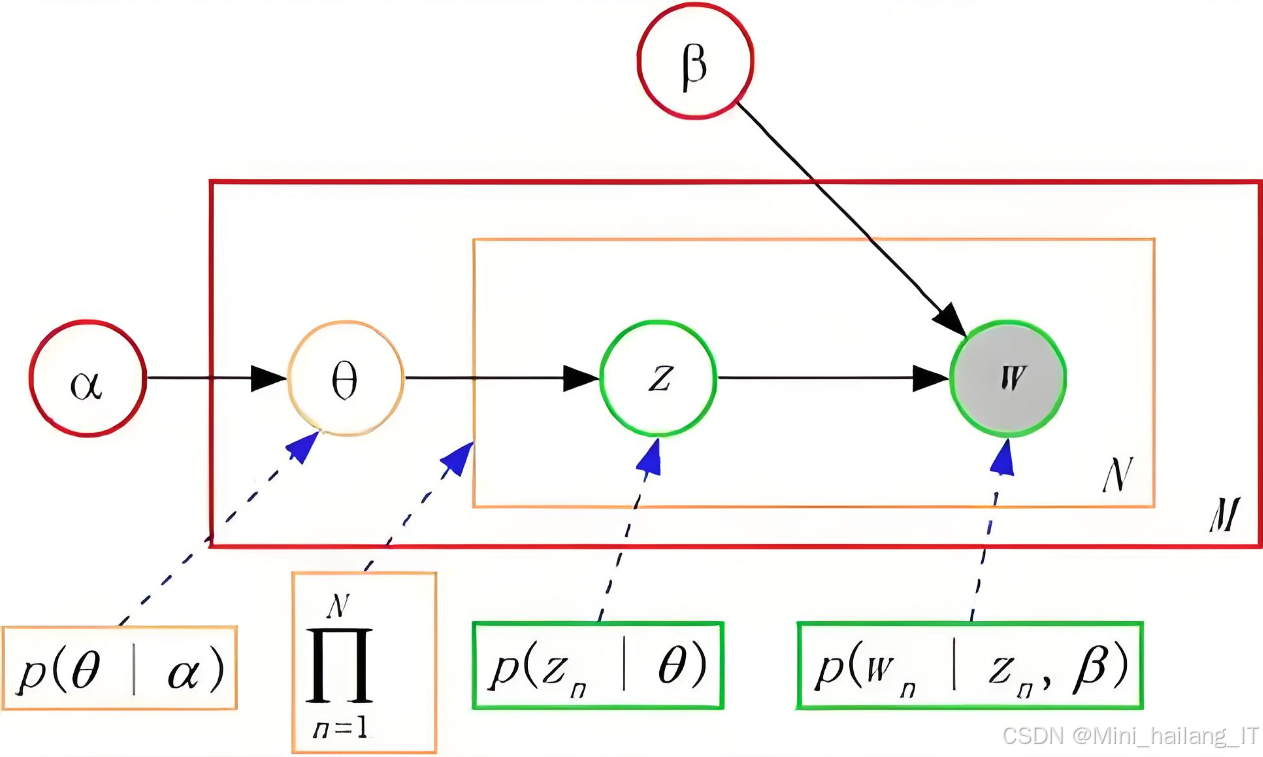
运用LDA主题模型对Steam游戏春促事件中的微博评论进行了深入分析。在确定最佳主题数K时,需要在模型的复杂性与可解释性之间找到平衡。困惑度和一致性是评估不同K值下模型性能的两个重要指标:困惑度用于衡量模型对未见数据的预测能力。选择K时,通常会寻找困惑度较低的模型,因为较低的困惑度指示模型有更好的泛化能力。对于LDA模型而言,较低的困惑度意味着模型能够较好地捕捉到数据的潜在结构。一致性评估了模型发现的主题的质量,特别是主题内词汇的语义相关性。高一致性得分表明模型生成的主题在语义上是有意义且紧密相关的,这有助于提高模型的可解释性和实用性。通过对比不同K值的困惑度和一致性得分,本研究寻求在这两个指标之间达到最佳平衡。
采用LDA主题模型分析Steam游戏春促事件中的微博评论,主题数选择为1-5,最终得到5个主题模型。每个主题均计算了其对应的困惑度与一致性得分,使用Gibbs抽样算法构建LDA模型的过程主要包括文本的预处理、模型训练和主题词提取。利用sklearn和gensim库实现了这一过程。通过移除特殊符号、分词及删除停用词对文本数据进行预处理。应用Gibbs抽样方法进行迭代计算,经过多次迭代优化模型参数,最终训练出了包含四个主题的LDA模型。
支持向量机是一种监督学习的分类算法,广泛应用于情感分析任务中。其基本思想是在特征空间中寻找一个最优超平面,以最大化样本之间的间隔,从而有效地将不同类别的数据分开。在情感分析的背景下,SVM可以将文本数据(如评论、反馈等)映射到高维空间,通过选择支持向量(即离决策边界最近的样本)来构建分类模型。SVM不仅适用于线性可分的情况,还通过使用核函数能够处理非线性分类问题,使其在复杂的情感分析任务中表现良好。在社交媒体评论、产品评价和用户反馈等文本数据的分析中。通过对评论进行情感倾向分类(如积极、消极、中立),能够快速了解用户对产品或服务的满意度,进而优化决策。此外,SVM还可以与其他技术结合,如特征选择和文本预处理,提升模型的准确性和效率。
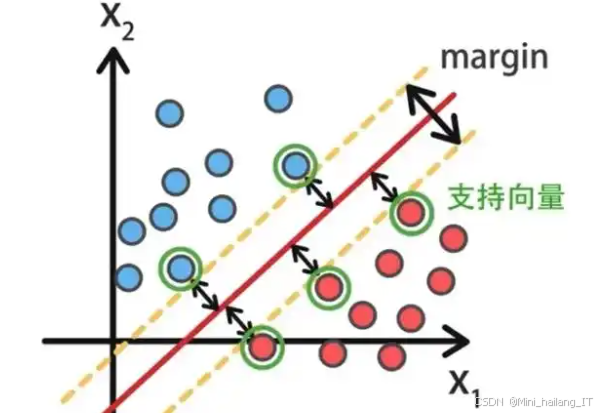
情感分析之前,首先需要从相关平台(如Steam、微博等)爬取评论数据。数据爬取后,需对原始数据进行清理,包括去除HTML标签、特殊字符以及冗余信息。接着,对文本数据进行分词处理,将长句拆分为单独的词汇。同时,移除停用词(如“的”、“是”、“在”等常见但无实际意义的词)以减少噪声,提高后续分析的效果。
import requests
from bs4 import BeautifulSoup
import jieba
# 示例:爬取某游戏的评论数据
url = '游戏评论的URL'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
comments = soup.find_all('div', class_='comment-text')
# 数据清理与分词
cleaned_comments = []
for comment in comments:
text = comment.get_text()
# 清理特殊字符
text = re.sub(r'[^\w\s]', '', text)
cleaned_comments.append(' '.join(jieba.cut(text)))
# 移除停用词
stop_words = set(open('stop_words.txt', 'r', encoding='utf-8').read().split())
filtered_comments = [' '.join([word for word in comment.split() if word not in stop_words]) for comment in cleaned_comments]利用LDA主题模型从清理后的评论中提取主要主题。LDA模型能够识别出文本中的潜在主题并为每个主题分配一组关键词。通过设置主题数量K,并调整模型参数,可以得到具有代表性的主题分布。通过词云图和共词矩阵进行社会网络分析,以揭示关键词汇及其网络中心性。词云图能够清晰地展现高频词,直观反映评论的主要关注点。共词矩阵则能够分析关键词之间的共现关系,构建关键词网络,帮助理解评论中主题的关联性。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
# 生成词云
wordcloud = WordCloud(font_path='simhei.ttf', width=800, height=400, background_color='white').generate(' '.join(filtered_comments))
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 共词矩阵构建
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(filtered_comments)
co_occurrence_matrix = (X.T @ X).toarray()
# 可视化共词矩阵
import seaborn as sns
sns.heatmap(co_occurrence_matrix, cmap='Blues', xticklabels=vectorizer.get_feature_names_out(), yticklabels=vectorizer.get_feature_names_out())
plt.show()使用百度智能云情感分析工具和支持向量机(SVM)方法构建情感分类模型。首先,利用已有的情感标签数据训练SVM模型,分类评论为积极、消极或中立。然后,对模型进行评估,包括准确率、召回率和F1分数等指标,以确保模型的可靠性和有效性。
from sklearn import svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 假设已经有标注好的情感数据
X_train, X_test, y_train, y_test = train_test_split(corpus_features, labels, test_size=0.2, random_state=42)
# 构建并训练SVM模型
svm_model = svm.SVC(kernel='linear')
svm_model.fit(X_train, y_train)
# 模型评估
y_pred = svm_model.predict(X_test)
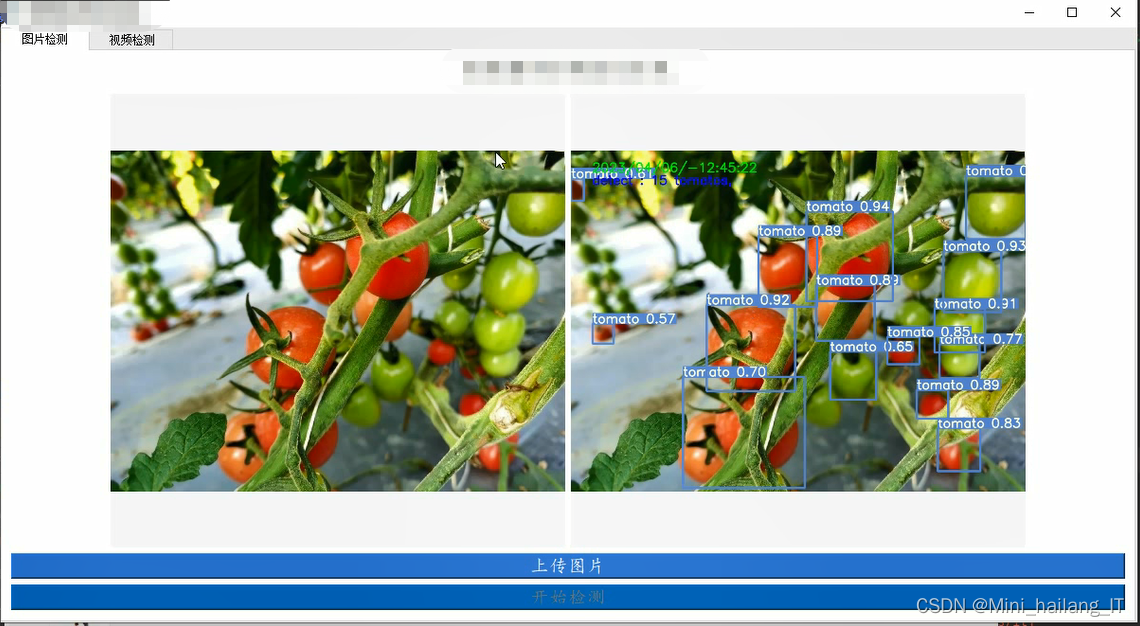
print(classification_report(y_test, y_pred))海浪学长项目示例:





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









