






目录
1.Git
git是一款分布式版本控制软件,他的作者是Linux创始人linus,所以它也是开源的。他的作用有两个,一是版本的管理或者控制,另外一个就是多人协作。除了git还有svn、cvs这样的版本控制软件,它们的区别在于一个是分布式一个是集中式的。
集成式的特点:所有的版本库都存在中央服务器,本地备份动作必须依赖中央服务器,如果一旦服务器挂掉,或者网络状况不好,没法提交版本。
分布式的特点:每一台客户端都有完整的版本备份,所有的版本提交不需要依赖中央服务器,只有多人协作时候,需要用服务器交换一下版本库。
git的优点就在于它的版本管理速度快,容灾行更高,可以不依赖网络,所以越来越多的公司更愿意去使用git。
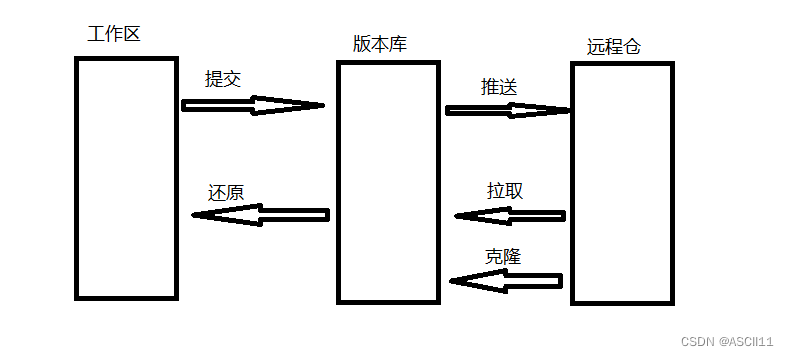
工作区:相当于工作的文件夹
版本库:Git备份的位置
远程仓:远程的服务器
GIt操作及指令
配置个人信息
git config --global user.name "name"
git config --global user.email "xxx@qq.com"中文显示
git config --global core.quotepath false查看个人配置信息
git config -l初始化仓库
git init提交工作区的内容到版本库
git add <文件名>:*代表所有的文件--- git add *
git commit -m "<提交的内容>"查看版本的记录
git log查看工作区的状态
git status丢掉工作区的内容
git checkout <文件名>版本回退
git log
git reset --hard <版本ID>版本前进
git reflog :显示引用记录,引用记录包括所有的提交信息
git reset --hard <版本ID>远程仓
远程仓使用的是中国的码云,里面有很多开源的代码,方便学习交流,项目代码可以放在上面托管。
2.共用体
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
结构体字节对齐的原则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对结构体首地址的偏移量都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节;
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
总结:首地址对齐(按最大)、总大小对齐(按最大)、成员对齐(按成员类型)
3.linux内核链表
老师发的链表非常好用,但有些具体功能实现还是不理解,现在还单纯停留在使用层面,通过不断地学习总结提高自己的能力,然后去研究研究源码。
4.三方库的移植
步骤:
- 从官方网站或者gitub等平台获取源码。
- 解压源码并进入目录。
- 在源码目录新建work目录以便后续的安装。
- 配置编译选项。 configure是一个可执行的配置脚本(用来生成Makefile) --host:指定编译器 --prefix:指定安装目录(如果不指定此选项,那么默认安装到系统路径) ./configure --prefix=$PWD/work)
- 如果是交叉编译,给ARM板用,配置选项如下 ./configure --host=arm-linux- --prefix=$PWD/work
- 编译:make
- 安装 make install,这个install它是Makefile中的一个目标,会自动把生成的内容拷贝到上面指定的文件夹中。
- 安装成功以后,work目录会有:头文件、库文件、可执行程序
5.JSON
JSON是JavaScript Object Notation的缩写,它是一种数据交换格式。JSON实际上是JavaScript的一个子集。
数据类型:
- number:和JavaScript的number完全一致;相当于C中的int类型
- boolean:就是JavaScript的true或false;相当于c++中的bool类型
- string:就是JavaScript的string;相当于c++的string类型
- null:就是JavaScript的null;相当于C的NULL类型
- array:就是JavaScript的Array表示方式;相当于C的数组
- object:就是JavaScript的{ ... }表示方式。相当于C++的类或者C的结构体
示例
{
"name": "小明",
"age": 14,
"gender": true,
"height": 1.65,
"grade": null,
"middle-school": "\"W3C\" Middle School",
"skills": [
"JavaScript",
"Java",
"Python",
"Lisp"
]
}- json以大括号起始和结尾
- 内容都是以键值对的形式存在
- 所有的键都是字符串
- 值的类型不一定,属于JavaScript 的基本数据类型
- 每个键值对以
,分割 - 最后一个键值对不加逗号
JSON基本操作
json序列化和反序列化
序列化是将信息转为json格式的字符串;反序列化就是从json字符串中取出信息;
cJson的使用
//从 给定的json字符串中得到cjson对象
extern cJSON *cJSON_Parse(const char *value);
//从cjson对象中获取有格式的json对象
extern char *cJSON_Print(cJSON *item);
//从cjson对象中获取无格式的json对象
extern char *cJSON_PrintUnformatted(cJSON *item);
//删除cjson对象,释放链表占用的内存空间
extern void cJSON_Delete(cJSON *c);
//获取cjson对象数组成员的个数
extern int cJSON_GetArraySize(cJSON *array);
//根据下标获取cjosn对象数组中的对象
extern cJSON *cJSON_GetArrayItem(cJSON *array,int item);
//根据键获取对应的值(cjson对象)
extern cJSON *cJSON_GetObjectItem(cJSON *object,const char *string);
//获取错误字符串
extern const char *cJSON_GetErrorPtr(void);在解析json时,有类似分层的思想,就像我们剥洋葱,每个大括号就代表着一层,每一层都对应着对象,再去访问对象中的数据或者再去剥洋葱那样剥去一层。
反序列化:
#include <stdio.h>
#include <stdlib.h>
#include "list.h"
#include "cJSON.h"
#define SIZE_T 512
#define BOOL int
union val_t {
int val_int;
BOOL val_bool;
float val_float;
};
struct data
{
int key;
int type;
union val_t val;
struct list_head list;
};
int main(int argc, char const *argv[])
{
//**********解析json*********
struct data *node = NULL;
struct list_head head;
FILE *fp = fopen("./json.txt", "r");
char *buf[SIZE_T] = {0};
int ret = fread(buf, sizeof(buf), 1, fp);
if (ret < 0)
{
printf("fread err\n");
return -1;
}
// printf("%s\n", jsonStr);
cJSON *root = NULL;
cJSON *item = NULL;
cJSON *arr = NULL;
root = cJSON_Parse(jsonStr);
if (root == NULL)
{
printf("error before: [%s]\n", cJSON_GetErrorPtr());
return -1;
}
INIT_LIST_HEAD(&head);
item = cJSON_GetObjectItem(root, "ver");
printf("%s\n", cJSON_Print(item));
item = cJSON_GetObjectItem(root, "cloud");
cJSON *passwd = cJSON_GetObjectItem(item, "password");
printf("%s\n", cJSON_Print(passwd));
cJSON *mpasswd = cJSON_GetObjectItem(item, "mpassword");
printf("%s\n", cJSON_Print(mpasswd));
item = cJSON_GetObjectItem(root, "data");
int num, i;
num = cJSON_GetArraySize(item);
for (i = 0; i < num; i++)
{
arr = cJSON_GetArrayItem(item, i);
node = (struct data *)malloc(sizeof(struct data));
cJSON *key = cJSON_GetObjectItem(arr, "key");
node->key = key->valueint;
cJSON *type = cJSON_GetObjectItem(arr, "type");
node->type = type->valueint;
printf("%d\n", type->valueint);
cJSON *val = cJSON_GetObjectItem(arr, "val");
switch (node->type)
{
case 1:
node->val.val_bool = atoi(val->valuestring);
printf("%d\n", node->val.val_bool);
break;
case 2:
node->val.val_int = atoi(val->valuestring);
printf("%d\n", node->val.val_int);
break;
case 3:
node->val.val_float = atof(val->valuestring);
printf("%f\n", node->val.val_float);
break;
}
list_add(&node->list, &head);
}
struct list_head *pos;
struct data *tmp;
list_for_each(pos, &head)
{
tmp = list_entry(pos, struct data, list);
switch (tmp->type)
{
case 1:
printf("key = %d, type = %d, val = %d\n", tmp->key, tmp->type, tmp->val.val_bool);
break;
case 2:
printf("key = %d, type = %d, val = %d\n", tmp->key, tmp->type, tmp->val.val_int);
break;
case 3:
printf("key = %d, type = %d, val = %f\n", tmp->key, tmp->type, tmp->val.val_float);
break;
}
}
fclose(fp);
free(jsonStr);
cJSON_Delete(root);
return 0;
}















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









