






打印出了所有图片的属性,包括class(元素类名)、src(链接地址)、长宽高等。
其中有百度首页logo的图片,该图片的class(元素类名)是index-logo-src。
[<img class="index-logo-src" height="129" hidefocus="true" src="//www.baidu.com/img/bd_logo1.png" usemap="#mp" width="270"/>, <img alt="到百度首页" class="index-logo-src" src="//www.baidu.com/img/baidu_jgylogo3.gif" title="到百度首页"/>]可以看到图片的链接地址在src这个属性里,我们要获取图片链接地址:
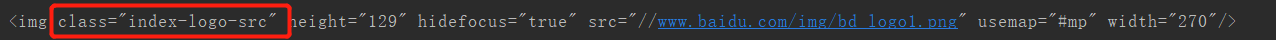
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 打印链接
print(logo_url)获取地址后,就可以用urllib.urlretrieve函数下载logo图片了
# 导入urlopen
from urllib.request import urlopen
# 导入BeautifulSoup
from bs4 import BeautifulSoup as bf
# 导入urlretrieve函数,用于下载图片
from urllib.request import urlretrieve
# 请求获取HTML
html = urlopen("https://www.baidu.com/")
# 用BeautifulSoup解析html
obj = bf(html.read(),'html.parser')
# 从标签head、title里提取标题
title = obj.head.title
# 只提取logo图片的信息
logo_pic_info = obj.find_all('img',class_="index-logo-src")
# 提取logo图片的链接
logo_url = "https:"+logo_pic_info[0]['src']
# 使用urlretrieve下载图片
urlretrieve(logo_url, 'logo.png')














 59万+
59万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









