



1、当一个子类中有对象成员时,他们的构造和析构顺序是怎样的?
首先是构造函数调用顺序:
- 父类的构造函数:先调用直接父类的构造函数(如果有多层继承,则从最顶层基类开始依次向下)。
- 对象成员的构造函数:按照对象成员在子类中声明的顺序依次调用(与初始化列表中的顺序无关)。
- 子类自己的构造函数:最后调用子类的构造函数体。
再是析构函数:
- 子类自己的析构函数:先调用子类的析构函数体。
- 对象成员的析构函数:按照对象成员构造顺序的逆序依次调用。
- 父类的析构函数:最后调用父类的析构函数(如果有多层继承,则从最底层子类的直接父类开始依次向上)。
观察可以发现,析构和构造的顺序是完全相反的。
#include <iostream>
using namespace std;
// 父类
class Parent {
public:
Parent() { cout << "Parent 构造函数" << endl; }
~Parent() { cout << "Parent 析构函数" << endl; }
};
// 对象成员类A
class A {
public:
A() { cout << "A 构造函数" << endl; }
~A() { cout << "A 析构函数" << endl; }
};
// 对象成员类B
class B {
public:
B() { cout << "B 构造函数" << endl; }
~B() { cout << "B 析构函数" << endl; }
};
// 子类,继承Parent,包含A和B的对象成员
class Child : public Parent {
private:
A a; // 声明顺序:A在前
B b; // 声明顺序:B在后
public:
Child() { cout << "Child 构造函数" << endl; }
~Child() { cout << "Child 析构函数" << endl; }
};
int main() {
Child c; // 创建子类对象
return 0;
}
输出结果:
Parent 构造函数 // 1. 父类构造 A 构造函数 // 2. 对象成员A构造(按声明顺序) B 构造函数 // 3. 对象成员B构造(按声明顺序) Child 构造函数 // 4. 子类自身构造 // 析构阶段(与构造顺序相反) Child 析构函数 // 1. 子类自身析构 B 析构函数 // 2. 对象成员B析构(逆序) A 析构函数 // 3. 对象成员A析构(逆序) Parent 析构函数 // 4. 父类析构
2、继承中的同名成员是如何处理的?
同名成员当然包括成员变量和成员函数,首先是成员变量:
- 隐藏规则:子类的同名成员变量会隐藏父类的同名成员变量(而非覆盖)。
- 访问方式:
- 直接访问时,默认访问的是子类自己的成员变量。
- 若要访问父类的同名成员,需使用作用域解析符
::(父类名::成员变量)。
接下来就是成员函数:
-
区分重载与隐藏:
- 若子类与父类的同名函数参数列表不同:父类的函数会被隐藏(即使符合重载条件,也不会形成重载)。
- 若子类与父类的同名函数参数列表相同且父类函数非虚函数:父类的函数会被隐藏。
- 若子类与父类的同名函数参数列表相同且父类函数是虚函数:形成多态(覆盖 / 重写),此时父类函数被覆盖。
-
访问方式:
- 直接调用时,默认调用子类的函数。
- 若要调用父类的同名函数,需使用作用域解析符
::(父类名::函数名)。
3、什么是菱形继承?菱形继承存在哪些问题?如何解决?
 如图所示可知菱形继承就是一个派生类同时继承自两个基类,而这两个基类又共同继承自同一个基类。
如图所示可知菱形继承就是一个派生类同时继承自两个基类,而这两个基类又共同继承自同一个基类。
菱形继承会导致数据冗余和二义性问题:
-
数据冗余:
-
派生类 D 会间接包含两份基类 A 的成员(一份来自 B,一份来自 C),造成内存浪费。
-
访问二义性:
- 当访问基类 A 的成员时,编译器无法确定应该访问从 B 继承的版本还是从 C 继承的版本,导致编译错误。
而解决方法就是采用虚继承,C++ 引入虚继承机制,使得派生类在继承间接基类时,只保留一份间接基类的成员,从而解决菱形继承的问题。
4、虚继承的原理?
虚继承通过引入 虚基类指针(virtual base pointer) 和 虚基类表(virtual base table) 实现,具体机制如下:
-
单一实例保证
-
当使用
virtual关键字声明继承(如class B : virtual public A)时,派生类(B、C)不会直接包含基类(A)的成员,而是在最终派生类(D)中只保留一份基类(A)的实例。 -
虚基类指针(vbptr)
-
中间派生类(B、C)会生成一个隐藏的指针成员(vbptr),指向虚基类表。
-
虚基类表(vbtable)
- 虚基类表是一个存储偏移量的数组,记录了从当前类(B 或 C)的内存地址到共享基类(A)实例的偏移量。通过这个偏移量,中间类(B、C)可以找到唯一的基类(A)实例。
可以使用VS开发命令工具查看虚基类指针(vbptr)和虚基类表(vbtable)
示例:cl /dl reportSingleClassLayoutMule MainTest. cpp
reportSingleClassLayout是展示单个类 Mule就是要查看的类,MainTest. cpp就是类所在的cpp文件。
5、c++如何实现动态绑定?
要实现动态绑定,必须同时满足以下条件:
- 继承关系:存在基类和派生类的继承结构;
- 虚函数重写:派生类重写(覆盖)基类中的虚函数(函数名、参数列表、返回值必须完全一致,协变返回值除外);
- 基类指针 / 引用:通过基类指针或引用调用虚函数。
当通过基类指针 / 引用调用虚函数时:
- 编译器通过基类指针 / 引用找到对象的 vptr;
- 通过 vptr 访问该对象所属类的 vtable;
- 在 vtable 中找到对应虚函数的地址并调用。
这个过程在运行时完成,因此能根据对象的实际类型(而非指针 / 引用的静态类型)调用正确的函数版本。
6、虚函数的原理?
- 动态绑定的条件:必须通过基类指针 / 引用调用虚函数,且派生类需重写该虚函数。
- 内存开销:每个对象增加一个 vptr 的内存开销(通常为 4/8 字节),每个类增加一个 vtable 的全局内存开销(与虚函数数量成正比)。
- 构造函数不能是虚函数:因为对象创建时 vptr 尚未初始化完成,无法指向正确的 vtable。
- 析构函数建议设为虚函数:确保通过基类指针删除派生类对象时,能正确调用派生类的析构函数(避免内存泄漏)。
虚函数的核心原理是通过 vtable 存储虚函数地址和 vptr 定位 vtable,使得程序在运行时能根据对象的实际类型动态选择函数版本,从而实现多态。这一机制由编译器自动实现,开发者只需通过 virtual 关键字声明虚函数即可使用。
7、什么是抽象基类?抽象基类的特点?
抽象基类(Abstract Base Class,简称 ABC) 是一种特殊的类,它不能被实例化,主要用于定义派生类的接口规范。抽象基类的核心作用是为继承体系提供统一的接口标准,强制派生类实现特定的功能。
1.不能实例化对象
class Shape { // 抽象基类
public:
virtual void draw() = 0; // 纯虚函数
};
// Shape s; // 编译错误:不能实例化抽象基类
2.包含纯虚函数
3.可包含非纯虚函数和成员变量
4.派生类必须实现所有纯虚函数
抽象基类是 C++ 中实现接口抽象的核心机制,其核心特点是:
- 包含至少一个纯虚函数;
- 不能实例化对象;
- 强制派生类实现接口;
- 支持多态和统一接口操作。
8、虚析构函数和纯虚析构函数的区别?
虚析构函数:在析构函数前加 virtual 关键字,有具体实现。
-
格式:
virtual ~类名() { ... } -
纯虚析构函数:在虚析构函数后加
= 0,但必须提供实现(与普通纯虚函数不同)。 - 格式:
virtual ~类名() = 0;(声明),且需在类外定义实现。
结论:
-
虚析构函数的核心作用是:当通过基类指针删除派生类对象时,确保派生类的析构函数被调用(避免内存泄漏),同时基类本身可实例化。
-
纯虚析构函数的核心作用是:在实现虚析构函数功能的同时,强制基类成为抽象类(无法实例化),适用于需要基类作为接口规范且不能被实例化的场景。
-
两者都必须有实现(纯虚析构函数的实现需在类外),否则会导致链接错误。
-
实际开发中,若基类可能被多态使用,建议将析构函数声明为虚函数;若基类需作为抽象接口(不能实例化),则使用纯虚析构函数(通常结合其他纯虚函数)。
9、说一下模板是如何编译的?
C++ 模板的编译核心是 “先检查语法,再按需实例化”,通过两次编译阶段实现对泛型代码的支持。其特殊之处在于:
- 模板定义需可见才能实例化(通常放在头文件);
- 仅在实例化时才检查与具体类型相关的代码合法性;
- 实例化过程由编译器自动完成(或显式声明)。
10、类模板的源文件和头文件如果分离?有没有什么问题?如何解决?
- 问题本质:模板实例化需要完整定义,分离存放会导致定义不可见,引发链接错误。
- 推荐方案:
- 简单场景:将声明和定义放在同一头文件(.h 或 .hpp);
- 逻辑分离:使用 .tpp 实现文件,在头文件中包含;
- 固定类型:显式实例化已知类型(如标准库中的部分容器)。
实际开发中,大多数开源库(如 STL)采用方案 1 或 2,因为模板的灵活性依赖于支持任意类型,显式实例化会限制其通用性。
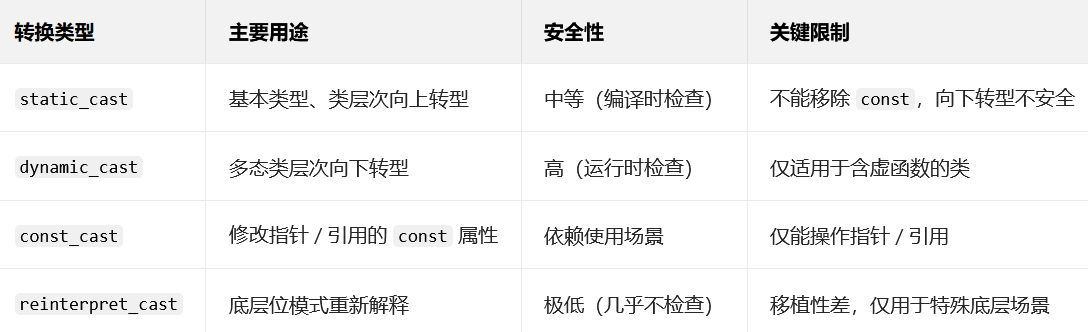
11、C++的4种类型转换?
12、为什么要使用c++异常?
C++ 异常的核心价值在于:提供了一种清晰、安全、可扩展的错误处理模式,尤其适合复杂系统开发。它解决了传统错误码方式的代码混乱、易忽略、传递繁琐等问题,同时与 RAII 结合能有效保证资源安全。
当然,异常也有轻微的性能开销(主要在抛出时),但现代编译器优化已使其在正常路径(无异常)下的开销可忽略不计。在注重可靠性和代码可维护性的场景中,异常是更优的选择。
也可以通过继承的方式,自己来写异常,但也需要注意:
-
继承体系:
- 通常从
std::exception派生(便于与标准库异常处理兼容) - 设计基础异常类(如
BaseException),再派生出具体类型(如FileException) - 形成异常层级,方便按类型捕获
- 通常从
-
核心成员:
- 必须重写
what()方法(返回错误描述字符串) - 可添加错误码(
code_)用于更精细的错误分类 - 根据业务需求添加额外信息(如文件名、IP 地址等)
- 必须重写
-
使用原则:
- 异常类应轻量(避免复杂构造 / 析构)
- 确保异常对象可安全复制(因为异常传递可能涉及复制)
- 用
noexcept修饰不抛出异常的方法(如what()、getCode())
-
捕获方式:
- 按从具体到抽象的顺序捕获(先子类后父类)
- 最后用
catch(...)捕获未知异常,避免程序崩溃
13、stl的组件有哪些?分别有什么作用?
- 容器提供数据存储结构;
- 算法提供操作数据的方法;
- 迭代器连接容器和算法;
- 函数对象定制算法行为;
- 适配器转换接口以适配新需求;
- 分配器管理底层内存。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









