






前言
很多年以后,当你回想起2025的蛇年春节,你会想起在高铁上、在飞机场、在前往景点的路上,很多人都在谈论或使用一个叫DeepSeek的AI应用。
很多人家里的老人在这个春节第一次问孩子,啥是AI?很多人在DeepSeek的热点分析中,第一次了解了世界AI领域的竞争格局。很多人第一次体会到了基于推理的大模型带来的震撼。
别误会,今天我们可不是要强行上价值。前面这两句话,是模仿[《百年孤独》]的开头写的,估计也是很多人在这个春节的真实感受。
1月20日,国内的AI初创公司深度求索推出了大模型**DeepSeek R1,**两天就震撼了整个AI界。在之后的两周里,AI界“满城尽带DeepSeek”。英伟达、华为云、天翼云、亚马逊、微软Azure,还有阿里云、百度智能云、腾讯云、京东云,等等,都宣布接入DeepSeek R1。
那么,**DeepSeek带来的震撼到底是什么?**它后续的影响有哪些?以及那些被DeepSeek热度掩盖的,同样至关重要的事情又是什么?
你是否还在为**「DeepSeek高阶应用」挠破头?🤯 想一键收割全网稀缺的大模型实战干货**?💡
🎯 本期**「DeepSeek高能拆解」直击核心——
✅ 从底层原理到行业顶配实战**,手撕技术黑箱!
✅ 100+前沿案例+代码级解析,小白也能秒变大神!

01
**DeepSeek到底厉害在哪?****
要回答上述问题,今天我们就建立一个尽可能全面的视角。
过去几天,得到App几位关注AI领域的老师,[《精英日课》]的主理人万维钢老师、[《科技参考》]的主理人卓克老师,以及[《AI学习圈》]的主理人,得到联合创始人快刀青衣老师,都做了深入的分析。
同时,我们得到自己早在去年5月就开始使用DeepSeek,从得到App内的学习助手,再到我们的新产品Get笔记,DeepSeek每个版本的更新,快刀青衣老师都要带着技术团队做评测。
接下来,我们就结合几位老师的观察,以及我们自己过去9个月积累的使用体验,来说说关于DeepSeek人们最关心的几个问题。
首先,DeepSeek到底厉害在哪?可以用三个词概括,性能、开源、成本。
第一,性能。
从性能上看,媒体和专业机构的测评用词是,DeepSeek R1的实际性能对标GPT-o1,有些能力甚至超过o1。
比如昨天我们讲到电影产业,我分别问了几个大模型关于电影产业的问题,其中DeepSeek在深度思考模式下的回答确实是最好的,而且在一些逻辑细节上要远超其他产品。而且在回答之前,它还会逐字分析你提出的问题,确保准确理解,再给出回答。
第二,开源。
整个模型不仅开源,而且开发团队还把研发过程写成论文,公开发布。
据说在过去两周里,全世界的AI实验室都在研读这篇论文。从16个月之前,DeepSeek就在开源社区(GitHub)持续提交自己的每一个版本,而且全部都是MIT协议,这是开源社区中对使用者要求最低的协议。你只要声明版权,就可以随意使用,可以用于学术,也可以用于商业,即使拿走之后自己改造,改造过的版本不再开源也行。
而在此之前,性能好的模型很贵,而开源不要钱的模型性能又不太行。**DeepSeek是第一个开源,且性能对标o1的大模型。**而且这是一个中国AI初创公司做的。之前一直号称非营利,把开放共享挂在嘴边的OpenAI,从来都没有做到这种程度的开源。
英伟达资深研究员Jim Fan对DeepSeek的评价是,我们生活的这个时间线上,是一家非美国公司,在延续OpenAI最初的、真正开放的前沿研究,赋能所有人。这最有趣的结局居然成真了。
Meta的首席人工智能科学家杨立昆说,这不是两个国家之间谁超越谁的问题,而是开源模型超越了专有模型,这是开源世界的胜利。
之前市面上还有人质疑,说DeepSeek R1是抄袭GPT,是从GPT蒸馏出来的。所谓蒸馏,就相当于压缩。比如张三是开快餐店的,但又不会炒菜,他就从李四开的大饭店里买回菜,然后分装成盒饭再去卖,这就属于张三蒸馏了李四。
但对于这个质疑,开源社区(GitHub)上的所有开发者早就有共识,DeepSeek不是抄袭,不是蒸馏。毕竟,人家之前的每一步都已经公开。而且所有的功能和自己公布的代码全都能对得上。现在已经有几十家规模不同的公司,用DeepSeek公开的信息,复现了R1大模型。
当然,假如仅仅是开源和性能,还不足以引起那么大的讨论。还有第三个关键因素,这就是R1的成本。
很多人说DeepSeek摆脱了对GPU的依赖,英伟达的股价都被DeepSeek搞垮了。这个说法其实不是很准确,咱们后面展开说。但回到成本,DeepSeek确实把成本打下来了。
从参数上看,R1是一个比较小的大模型,总共有6710亿个参数,而且一次推理调用的参数只有370亿个。什么概念?GPT-4的参数有1.76万亿个。
至于DeepSeek的具体成本,他们自己并没有公开过。目前市面上对R1成本最详细的分析,来自研究机构SemiAnalysis出具的报告。
根据SemiAnalysis的研究,DeepSeek一共有6万张计算卡,其中A100、H800、H100各一万张,H20三万张。其中相对最先进的,是H100。
假如以这个H100为基准,假设H100的算力是100,那么A100的算力大概是50,H800的算力是60,H20的算力是15,后面这些算力较低的计算卡,都是美国芯片禁令的结果,在这里就不多说了。
而这些计算卡的算力加起来,大概是255万。这个配置要远低于同规格的其它大模型。
从资金上看,外界盛传R1的成本只有600万美元,这其实不太准确。600万美元只是模型的预训练费用。确切说,是DeepSeek R1的上一版,DeepSeekV3的预训练费用,这笔钱是600万美元。
但是,DeepSeek并不是租用算力做的模型,而是自己买计算卡,自己搭建服务器。目前DeepSeek大概有150名员工,还会定期从北大、浙大招募人才,有潜力的候选人年薪能达到900多万元。而且DeepSeek背后的投资方,幻方量化早就意识到AI在金融之外的潜力,在2021年就买入了10000块A100计算卡。
2023年5月,DeepSeek从幻方拆分出来,全面专注于AI业务。这期间,前前后后购买GPU的总花费是7亿美元,搭建服务器等各类系统的费用大概9亿美元,再加上期间的运营成本等等。根据SemiAnalysis的估算,总费用应该在26亿美元。
当然,这26亿美元买入的硬件后续还会持续使用,它并不是针对R1的成本,而是这家公司多年之后的总成本。
换句话说,R1确实很厉害,但外界传闻的,一个金融公司,本来没想专门做AI,只是顺手不小心做出了个R1,这个说法多少有点夸张了。这背后哪有什么网络爽文式的故事?这是一家公司几年持续的大规模投入,一群顶尖人才持续研发的结果。
而回到R1,仅仅是这600万美元的训练成本,也已经比市面上的同类模型低了一个数量级。比如,Meta去年7月发布的Llama 3.1大模型,训练费用是6000万美元,这在当年已经算是很便宜的大模型了,但它的训练成本依然是R1的10倍。
关于R1的性价比,再说个更直观的例子,就是我们得到研发的新产品Get笔记。这个产品是去年6月推出的。
其中有一个环节是润色,假如使用GPT-4o,那么每天在润色环节上的花费大概是2000美元,而假如用当时DeepSeek的V2,也就是R1的前一个版本V3的再前一个版本,那么每天的花费能降低到120美元。一年算下来,能节省450万人民币。也许对于很多产品来说,因为更换这个模型,公司就能从亏损企业变成盈利企业。
前面说了这么多,细节和数字你可以不用记。我们只需要记住一件事,DeepSeek是目前世界上的大模型里,性价比最高,而且是唯一一个能够对标o1的完全开源的大模型。而它的创作者是一家名叫深度求索的中国AI公司。
02
*AI领域的竞争格局走向何方?*
那么,R1是怎么做到的呢?
DeepSeek公开的论文中给出的答案是,没有人为干预的强化学习。也就是,工程师并不告诉模型应该如何推理,而是只要模型做对了,就让它获得奖励,然后在这个反馈机制里一步步摸索,就好像AI在自己引导自己,自己调整自己一样。
对于很多外行人来说,人们更关心的,是这个技术的后续影响。
第一,R1节省了大量的显卡和算力,是不是意味着英伟达以后要不行了?
大概率上不会。**R1确实在很大程度上打消了科技公司对算力的迷信。**不需要几十万张算力卡,也能做出厉害的大模型。目前包括OpenAI在内的几个科技巨头,都在用R1的核心技术微调自己的模型,大家都想把算力的消耗降下来。
但是,这也许并不意味着英伟达就不行了。英伟达的股价确实出现了暴跌,在1月27日跌去了5900亿美元,创下了美股历史上单日最大市值下跌纪录。但问题是,英伟达的股价之前在AI概念的追捧下也许就已经严重虚高,这时稍微有点风吹草动,哪怕是黄仁勋得流感,都可能被庄家利用,当成暴跌的信号。
事实上,抛开股价不谈,英伟达的核心产品,H100算力卡的价格在R1推出后,是在持续上涨的,而之前H100的价格一度低迷。
为什么上涨?因为需求变多了。
为什么需求变多?因为**R1的推出等于是告诉所有人,不需要那么多算力卡也能训练大模型。**这就好比淘金,你突然告诉所有人,挖金子的难度和成本其实没有那么高,这个信号放出去,你觉得买铲子的人会变多还是变少?
出海的成本越低,大航海时代来得越猛。
第二,DeepSeek R1自己面对的挑战是什么?
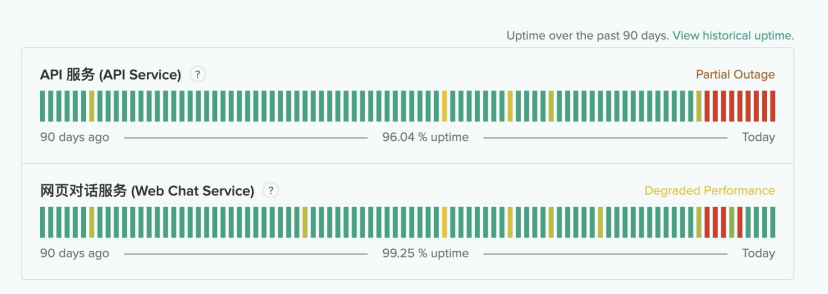
根据快刀青衣老师的观察,R1目前要解决的挑战之一,是技术工程化的问题。说白了,就是让这个技术在面对全世界的需求时,依然表现得足够稳。现在R1的接口服务还不够稳定,假如访问的用户太多,可能就会出现卡顿和超时。
下面这张图,是DeepSeek R1过去90天的运行情况。你可以明显看到,过去10天随着访问量增加,R1的API接口服务受到了巨大的冲击。
API服务,你大概可以理解成更专业的需求,要么来自公司机构,要么是对AI使用相对深度的个人。而相应的,网页对话服务的情况相对稳定,也许是DeepSeek把更多的精力用来保证C端普通用户的体验。
注意,在这里,再强调一句,尽管R1面对一些挑战,但借用万维钢老师的话说,它依然是独树一帜的重量级存在。
第三,关于AI领域之后的竞争格局。
就在前几天,OpenAI毫无预兆地发布了Deep Research功能,也许等DeepSeek的热度褪去一些,你就能看到很多关于它的报道。在搜索研究方面,Deep Research展现出了巨大的优势,它甚至能在整合信息的基础上,生成自己的研究思路。
你可以把这个产品当成一个信号,依然不能低估算力的价值,也不能低估竞争者的野心。
在这个过程中,先发优势是真的,但后来居上的颠覆式创新也一直在发生。
好啦,以上就是本期**「DeepSeek高能玩法」的全部内容!想获取更多DeepSeek和大模型的独家深度资料?🔥 快关注 我**,一键解锁前沿技术解析、实战案例和进阶秘籍📚!
 免费领!全网最全DeepSeek学习资料合集!速戳→
免费领!全网最全DeepSeek学习资料合集!速戳→

你是否曾在深夜对着电脑屏幕,为找一份靠谱的 DeepSeek 学习资料翻遍全网?从论坛帖子到公众号文章,收藏夹里攒了上百个链接,真正能用的却没几个;想跟着教程实操,不是内容太浅像 “隔靴搔痒”,就是太深奥看不懂,最后只能对着满屏代码叹气…
针对学习者面临的资料碎片化难题,我们精心整理39份PDF「DeepSeek 学习资料合集」,帮助大家轻松高效地掌握实用的AI应用技巧(附带实操案例),全都给你整理得明明白白~

你想要的AI资料包,都帮你整理好了!
添加【Ai学习官】免费领取

部分资料抢先看!
一、新手入门:3 天搭起 AI 应用框架
01.【104页超详细】DeepSeek从入门到精通.pdf
全面解析DeepSeek,包含提示语设计、多场景应用技巧(如文本生成、代码开发、营销策划等)等实用技巧,适用于不同背景人群。

02.Deepseek喂饭级指令.pdf
AI 学习者的实操指南,提供 6 大分类 30 + 场景的 “傻瓜式” 指令模板,含明确输入输出格式与示例。适合快速落地解决实际问题的新手。

二、进阶提效:从 “会用” 到 “精通” 的关键
03.小白入门DeepSeek必备的50个高阶提示词.pdf
场景覆盖更细分多元,含职场、副业、生活等 50 个场景,且聚焦 “高阶”:有提示词优化、多 AI 联合作战等进阶技巧,新增变现策略(如知识付费、私域 SOP)与趣味玩法(AI 算命、元宇宙营销)。更重实战与技能提升,兼顾新手入门与进阶需求。

04.清华大学第二弹:DeepSeek 赋能职场.pdf
职场人的提效秘籍,系统对比 DeepSeek 不同模型(V3/R1)特性,提供 RTGO、CAP 等专业提示语框架,涵盖可视化图表、PPT、海报等多职场场景实操案例。适用于数据处理、内容生成等职场任务,兼具理论深度与实操指导。


三、实战案例:学生 / 职场人 / 创业者都能用
05.清华大学第三弹:普通人如何抓住DeepSeek红利.pdf
通过 “理论 + 实战 + 案例” 三位一体的体系,包含代码生成、创意写作、多轮对话优化技巧、项目书撰写、社交困境处理等60 + 真实场景解决方案:如课堂知识查漏补缺、编程入门代码调试、1 小时生成万字项目方案、新员工入职培训 SOP等等,帮助学习者突破 “工具使用” 与 “任务落地” 的双重瓶颈。
最后说句真心话:
AI 不是少数人的专利,普通人也能通过系统学习掌握这门技术,让它成为提升效率、创造价值的利器。这份资料合集,就是我们为你搭建的 “AI 学习阶梯”,从基础到进阶,从理论到实战,一步步带你走进 DeepSeek 的世界。现在扫码,免费领取资料,开启你的 AI 进阶之旅吧!说不定下一个用 AI 搞定复杂项目、实现效率翻倍的,就是你!
独家整理!超全AI学习资料
不用费力寻找,pdf全套分享


资料持续更新,添加
【Ai学习官】免费领取!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









