







消息队列
使用场景
缓存/消峰:数据量过大时,消息队列缓存数据,服务端缓慢读取
解耦:数据源、目的地不同,符合接口约束即可
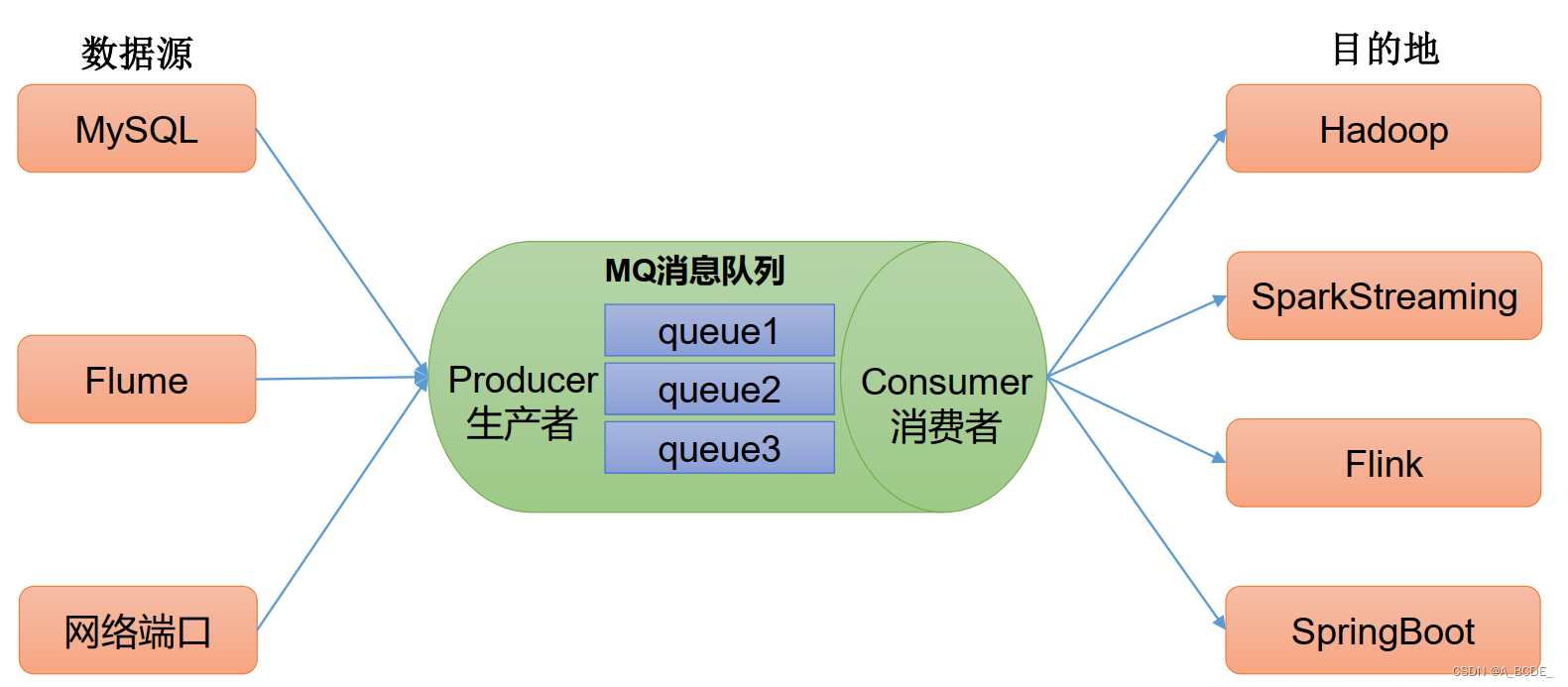
异步通信:无所谓的工作,由其他从kafka中读取完成
模式
- 点对点:一对一,消费者主动拉取数据,读取后删除
- 发布订阅模式(设计模式):多对多,消费者相互独立,消费后不删除,其他消费者可以读到数据。多个topic主题
中间件比较
-
RabbitMQ
支持很多的协议:AMQP,XMPP, SMTP, STOMP
重量级,适合企业级的开发
发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。 -
Redis
基于Key-Value对的NoSQL数据库
入队时,当数据比较小时Redis的性能要高于RabbitMQ,而如果数据大小超过了10K,Redis则慢的无法忍受;
出队时,无论数据大小,Redis都表现出非常好的性能,而RabbitMQ的出队性能则远低于Redis。 -
ZeroMQ
快,大吞吐量的需求场景。
高级/复杂的队列,技术复杂度高,开发人员需要自己组合多种技术框架
不需要安装和运行一个消息服务器或中间件
仅提供非持久性的队列,如果宕机,数据丢失。 -
ActiveMQ
类似于ZeroMQ,以代理人和点对点的技术实现队列。
类似于RabbitMQ,高效 -
Kafka/Jafka
高性能,分布式,发布/订阅消息队列系统
快速持久化,可以在O(1)的系统开销下进行消息持久化;
高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;
完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;
支持Hadoop数据并行加载,对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka通过Hadoop的并行加载机制统一了在线和离线的消息处理。
轻量级,性能好,工作良好的分布式系统。
采用零拷贝技术
kafka
Kafka:数据管道、流分析、数据集成和关键任务应用。存储、计算、分析、集成
基础架构
- Broker: 一台 Kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个broker 可以容纳多个 topic。一个大的 topic 可以分布到多个 broker(即服务器)上。扩展性↑
- Topic: 可以理解为一个队列, 生产者和消费者面向的都是一个 topic。逻辑概念
- partition(分区):有序队列。海量数据,为提高吞吐量****分区,一个topic分为多个partition。一个分区的数据只能由一个消费者来消费。物理概念
- Replica( 副本):为提高可用性,为每个partition增加若干副本,partition为leader,副本为follower,生产和消费只针对leader,Follower 找 Leader 进行同步数据。leader挂掉后ISR中follower推举产生新的leader。
默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。 - zk:分区信息, leader和follower信息由zk存储,新版本可以不使用zk存储
- Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- ISR队列:和Leader保持同步的follower,follower一段时间内(replica.lag.time.max.ms,默认30s)未与leader同步数据或通信则认为follower挂掉,踢出ISR队列。
OSR: Follower 与 Leader 副本同步时,延迟过多的副本。
AR:Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。AR = ISR + OSR
生产端
发送原理
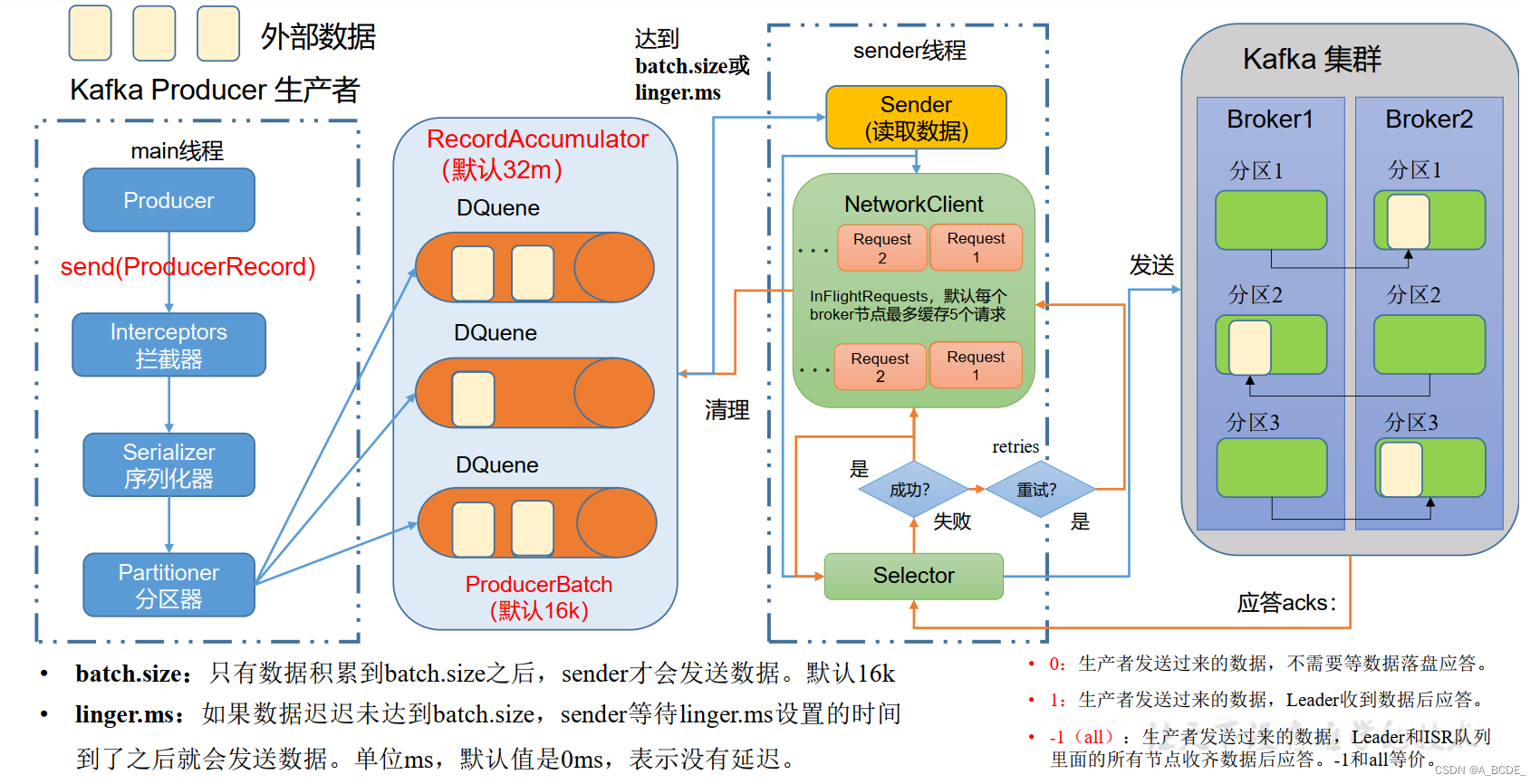
- 序列化器:客户指定,java自带的过重
- 分区器:分区器在内存中,大小32m,实际上为一个缓存队列,包含多个双端队列。
一个分区一个队列,将数据发送到对应分区的队列中(一个数据可发往多个队列)。
分区器中还包含一个内存池,每一批次数据从内存池取内存插入队列,发送成功后删除数据,内存释放回内存池 - sender:从分区器中读取数据发到kafka,队列中累积batch.size数据为一组读取发送。如果未达到batch.size,在达到linger.ms时间也读取发送。
每个分区一个队列,读取对应分区队列的数据发送到对应分区(leader和follower)。如果分区未应答,可继续发送,最多可发送五组数据,如果仍未应答则不再发送。分区应答,回复成功,则清除sender发送的数据以及分区器队列中的数据,失败则重试(次数不限)。
batch.size:数据积累到batch.size之后,sender才会发送数据。默认16k
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间,到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。
- 同步发送:等上一批数据已发送到kafka集群中再继续发送。可靠可重试
- 异步发送:将外部数据发送到分区器中,无需等待ack。效率高,可以异步知道消息发送结果,缺点是无法重试
异步发送
// 1.创建kafka生产者的配置对象
Properties properties = new Properties();
// 2.给kafka配置对象添加配置信息
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// key,value序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2376
2376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









