






上一篇博客中介绍了爬虫前需要做的一些准备工作,今天我们就来进行一次实战演练----爬取链家二手房的房源信息。
1、获取请求头
首先我们来获取网站的请求头,不知道如何获取请求头的小伙伴请参考上一篇博客。下面就是我们获得的该网站的请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie': 'TY_SESSION_ID=68ea2c4e-5277-4dab-b8f6-2bdde5e61c57; lianjia_uuid=840489de-2c37-40de-9c15-522d4f0a4b7d; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1568118418; select_city=430100; digv_extends=%7B%22utmTrackId%22%3A%2221583074%22%7D; all-lj=3d8def84426f51ac8062bdea518a8717; lianjia_ssid=1c49f18b-d180-45d1-8317-d59aa8e69c1d; _qzjc=1; _jzqa=1.3637271738872210000.1568118544.1568118544.1568118544.1; _jzqc=1; _jzqy=1.1568118544.1568118544.1.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.-; _jzqckmp=1; UM_distinctid=16d1b26177746b-06b9b5b00fc26-e343166-144000-16d1b26177891e; CNZZDATA1255849590=1544917587-1568118208-https%253A%252F%252Fsp0.baidu.com%252F%7C1568118208; CNZZDATA1254525948=1761745203-1568117644-https%253A%252F%252Fsp0.baidu.com%252F%7C1568117644; CNZZDATA1255633284=1446432833-1568115241-https%253A%252F%252Fsp0.baidu.com%252F%7C1568115241; _smt_uid=5d779710.58312570; CNZZDATA1255604082=118953400-1568116187-https%253A%252F%252Fsp0.baidu.com%252F%7C1568116187; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216d1b261a3b5a4-0f07778157987f-e343166-1327104-16d1b261a3c575%22%2C%22%24device_id%22%3A%2216d1b261a3b5a4-0f07778157987f-e343166-1327104-16d1b261a3c575%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E4%BB%98%E8%B4%B9%E5%B9%BF%E5%91%8A%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fsp0.baidu.com%2F9q9JcDHa2gU2pMbgoY3K%2Fadrc.php%3Ft%3D06KL00c00fZg9KY0FN9B0nVfAs02-LII00000Fo-c-C00000LEiQaL.THLKVQ1i0A3qnjcsnjn1rHKxn-qCmyqxTAT0T1d-mhFhnHf3uW0snj0srH990ZRqf1cLwbnkwRR1PRckfRczPRNAP1T%22%2C%22%24latest_referrer_host%22%3A%22sp0.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E9%93%BE%E5%AE%B6%22%2C%22%24latest_utm_source%22%3A%22baidu%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22sousuo%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; _ga=GA1.2.144608934.1568118547; _gid=GA1.2.694153477.1568118547; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1568118582; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiOGQ5NGM2ZGMwNWIwMWZjYTRmOWJiNTI5MTdmNjE4ODRmNWY2ZDZlOTE3MzhhNWRkYjZiMTcxNDJmZDc4N2Q1ZmNiMTA2NGFhOWMzMDk1MjZkODFhZTQyYWJhM2NiMzBkZDhhMmQ4MmNkODAwYTJhMDU1ODM2ODNlMmRlYTliYmMzYTVkYmExNjZjNjhmMGJmZjVmNTY3OTE3MDE2NzAwMWZjZmQzZTdmYmZlOGIwZTc1NDE4NDgyZmVmZWUwNzQwMDY2OTczYTdhYzQzZTExNWNkZmYxZjExYTc5MmQzMzM1MTkxOTQzMTk4N2RlY2ZhNTI0ZWI3MjhiMDg5YzU3NmYwMmNkYjZmMDFmNmViOTdmNTExYzZmOTliNzA0MDVkNDVkMTYzY2E5Y2Y2MzUwNDVkYjQ3MzliZTFmNzBjMGNkYjUzYzU3YjM1ZGYxMzQ4ODljZWMzNzg3ZjAxMzczZFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCI2M2JkMTI2Y1wifSIsInIiOiJodHRwczovL2NzLmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvIiwib3MiOiJ3ZWIiLCJ2IjoiMC4xIn0=; _qzja=1.892590918.1568118543804.1568118543804.1568118543804.1568118574079.1568118581879.0.0.0.4.1; _qzjb=1.1568118543804.4.0.0.0; _qzjto=4.1.0; _jzqb=1.4.10.1568118544.1'
}
2、分析页面结构
分析网页URL
首先,我们来分析如何获取待爬取网页的 URL,一般有下面两种情况:第一种就是网页的 URL 满足某种规律,我们只要发现这种规律,就可以自己构造待爬取网页的 URL 了。如果网页的 URL 没有规律可言,那么我们只能从网页的内容中提取出待爬取网页的 URL ,以便下一次的爬取。
下面我们对链家二手房的网页进行分析,我们发现首页的网址是 https://cs.lianjia.com/ershoufang/pg1/,我们在看看第二页的网址, https://cs.lianjia.com/ershoufang/pg2/,以防万一我们再看一下第三页的网址
https://cs.lianjia.com/ershoufang/pg3/。现在我们可以发现这些页面的网址只有数字部分不同,其他部分一模一样,显然数字部分表示的是当前页码。由此我们就可以构建待爬取网页的 URL 了。比如:我们要爬取前10页的内容,可如下构建
pre_url = 'https://cs.lianjia.com/ershoufang/pg'
for i in range(1, 3):
spider(pre_url + str(i) + '/')
其中,spider是定义的抓取网页内容函数。
分析网页内容
要获取所有的二手房源信息,我们首先需要将构成每个二手房的代码片段选择出来,我们可以使用 Chrome 浏览器,导出所选择元素的 XPath 路径,具体看参考Chrome浏览器获取XPATH的方法----通过开发者工具获取。之后就可以对数组中的每个二手房信息进行再次筛选。获取页面所有二手房源的代码片段可参考如下代码:
house_list = selector.xpath('//*[@id="content"]/div[1]/ul/li')
现在我们就得到了当前页面下所有的二手房代码片段,接下来分析如何提取每一个二手房的相关信息。下面提取 标题 为例,我们要怎样才能获取到 揽江苑两房 南北通透 两梯两户 中间楼层 省个税 这个标题呢?
首先,我们先导出该元素的 XPath 路径,//*[@id="content"]/div[1]/ul/li[1]/div[1]/div[1]/a,但是我们是不是就是要使用这个路径呢?答案是 否定的。这里就会有小伙伴好奇为什么不能使用该路径啊,一脸懵逼!!!还记得我们之前是提取的每一套房源代码片段吗?此时的 html 代码片段是已经被我们截取过后的,也就是在其里面找不到//*[@id="content"]/div[1]/ul/li[1]/这些路径了,因此我们此时需要使用相对路径,只需要将这两个路径作比较,去掉前面相同的部分就好了。获取其他元素的步骤类似,关键代码如下:
for house in house_list:
title = house.xpath('div[1]/div[1]/a/text()')[0]
layout = house.xpath('div[1]/div[2]/div/text()')[0]
location = house.xpath('div[1]/div[3]/div/text()')[0]
value = house.xpath('div[1]/div[6]/div[1]/span/text()')[0]

此时我们就可以爬取当前页面了,进而获取我们想要的数据。别急!!!点击标题之后,我们会进入当前房屋的详情页,在该页面中,展示了更多有关房屋的数据,如果我们想抓取这个页面的数据怎么办???是不是手足无措了,天啊,这怎么办。。。。其实很简单的,下面我们来进行一个简单的分析:
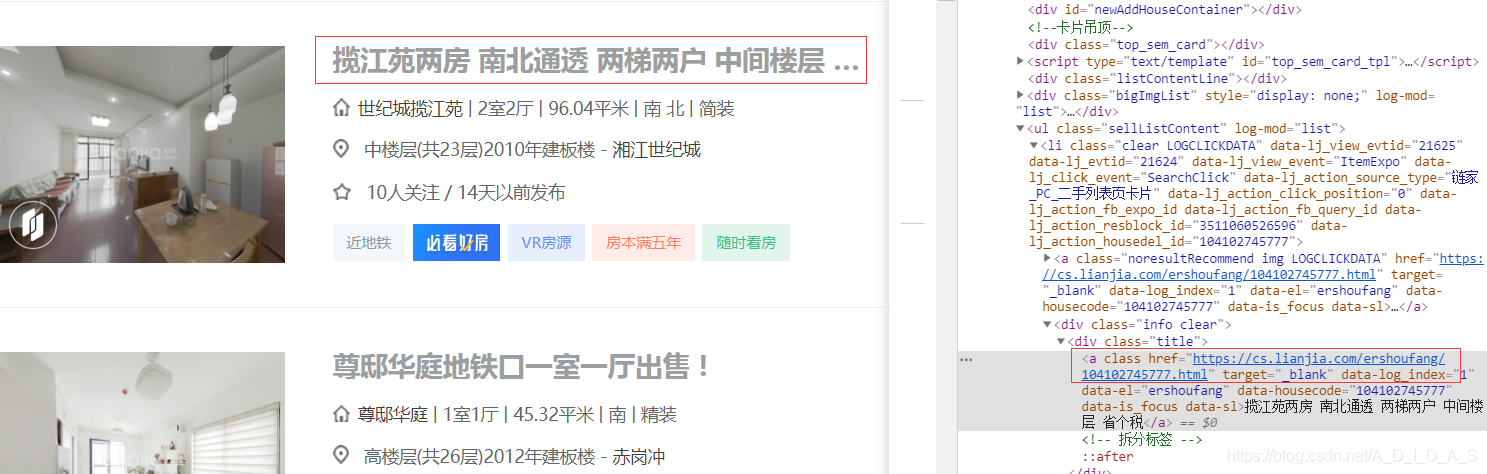
如果要爬取房屋详情页的内容,我们首先需要获取该页面的 URL ,然后下载该 URL 对应的网页,进而筛选出我们所需要的信息。下面图中圈起来的部分就是该房屋的详情页面的 URL ,使用如下代码将该其提取出来
house_detail_url = house.xpath('div[1]/div[1]/a/@href')[0]
接着下载该页面,使用相同的方法筛选我们所需要的数据即可。
现在我们已经可以得到房屋的数据了,但是让我们对着一堆冷冰冰的数据来决定买不买房是不是有点过分了,我们可是视觉动物哈哈,如果能够亲眼目睹房屋那是再好不过了,哪怕一种照片也是可以的呢。既然如此,我们接下来就爬取一下房屋的图片,以便使其更有参考价值。
要爬取图片,首先我们需要获取该图片的 URL ,然后访问对应的 URL ,下载图片即可。
# 获取图片 URL
image_url = house.xpath('a/img[2]/@data-original')[0]
# 在当前目录下创建一个文件夹,用来存放图片
def download_img(image_url, image_name):
img = requests.get(image_url, headers=headers)
with open('./lianjia_house_image/{}.jpg'.format(image_name), 'wb') as f:
好了,到此为止,我们对链家二手房的信息爬取已经告一段落了,小伙伴们可以按照这个思路自己动手来实践操作一下,可能你会遇到一些意想不到的 bug 哟[偷笑]!!!下面给出小编的源代码,有问题欢迎一起交流。
# -*- coding: utf-8 -*-
# # @Author: lemon
# # @Date: 2019-09-08 23:36
# # @Last Modified by: lemon
# # @Last Modified time: 2019-09-08 23:58
# # @function: 链家二手房 爬虫实例
from lxml import etree
import pandas as pd
import requests
import time
# 定义爬虫头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie': 'TY_SESSION_ID=68ea2c4e-5277-4dab-b8f6-2bdde5e61c57; lianjia_uuid=840489de-2c37-40de-9c15-522d4f0a4b7d; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1568118418; select_city=430100; digv_extends=%7B%22utmTrackId%22%3A%2221583074%22%7D; all-lj=3d8def84426f51ac8062bdea518a8717; lianjia_ssid=1c49f18b-d180-45d1-8317-d59aa8e69c1d; _qzjc=1; _jzqa=1.3637271738872210000.1568118544.1568118544.1568118544.1; _jzqc=1; _jzqy=1.1568118544.1568118544.1.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.-; _jzqckmp=1; UM_distinctid=16d1b26177746b-06b9b5b00fc26-e343166-144000-16d1b26177891e; CNZZDATA1255849590=1544917587-1568118208-https%253A%252F%252Fsp0.baidu.com%252F%7C1568118208; CNZZDATA1254525948=1761745203-1568117644-https%253A%252F%252Fsp0.baidu.com%252F%7C1568117644; CNZZDATA1255633284=1446432833-1568115241-https%253A%252F%252Fsp0.baidu.com%252F%7C1568115241; _smt_uid=5d779710.58312570; CNZZDATA1255604082=118953400-1568116187-https%253A%252F%252Fsp0.baidu.com%252F%7C1568116187; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216d1b261a3b5a4-0f07778157987f-e343166-1327104-16d1b261a3c575%22%2C%22%24device_id%22%3A%2216d1b261a3b5a4-0f07778157987f-e343166-1327104-16d1b261a3c575%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E4%BB%98%E8%B4%B9%E5%B9%BF%E5%91%8A%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fsp0.baidu.com%2F9q9JcDHa2gU2pMbgoY3K%2Fadrc.php%3Ft%3D06KL00c00fZg9KY0FN9B0nVfAs02-LII00000Fo-c-C00000LEiQaL.THLKVQ1i0A3qnjcsnjn1rHKxn-qCmyqxTAT0T1d-mhFhnHf3uW0snj0srH990ZRqf1cLwbnkwRR1PRckfRczPRNAP1T%22%2C%22%24latest_referrer_host%22%3A%22sp0.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E9%93%BE%E5%AE%B6%22%2C%22%24latest_utm_source%22%3A%22baidu%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22sousuo%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; _ga=GA1.2.144608934.1568118547; _gid=GA1.2.694153477.1568118547; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1568118582; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiOGQ5NGM2ZGMwNWIwMWZjYTRmOWJiNTI5MTdmNjE4ODRmNWY2ZDZlOTE3MzhhNWRkYjZiMTcxNDJmZDc4N2Q1ZmNiMTA2NGFhOWMzMDk1MjZkODFhZTQyYWJhM2NiMzBkZDhhMmQ4MmNkODAwYTJhMDU1ODM2ODNlMmRlYTliYmMzYTVkYmExNjZjNjhmMGJmZjVmNTY3OTE3MDE2NzAwMWZjZmQzZTdmYmZlOGIwZTc1NDE4NDgyZmVmZWUwNzQwMDY2OTczYTdhYzQzZTExNWNkZmYxZjExYTc5MmQzMzM1MTkxOTQzMTk4N2RlY2ZhNTI0ZWI3MjhiMDg5YzU3NmYwMmNkYjZmMDFmNmViOTdmNTExYzZmOTliNzA0MDVkNDVkMTYzY2E5Y2Y2MzUwNDVkYjQ3MzliZTFmNzBjMGNkYjUzYzU3YjM1ZGYxMzQ4ODljZWMzNzg3ZjAxMzczZFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCI2M2JkMTI2Y1wifSIsInIiOiJodHRwczovL2NzLmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvIiwib3MiOiJ3ZWIiLCJ2IjoiMC4xIn0=; _qzja=1.892590918.1568118543804.1568118543804.1568118543804.1568118574079.1568118581879.0.0.0.4.1; _qzjb=1.1568118543804.4.0.0.0; _qzjto=4.1.0; _jzqb=1.4.10.1568118544.1'
}
pre_url = 'https://cs.lianjia.com/ershoufang/pg'
# 爬取链家二手房信息
def spider(list_url):
# 存储 DataFrame 中用到的数据
data = {
'title': [],
'layout': [],
'location': [],
'value': [],
'house_years': [],
'mortgage_info': []
}
selector = download(list_url)
house_list = selector.xpath('//*[@id="content"]/div[1]/ul/li')
for house in house_list:
title = house.xpath('div[1]/div[1]/a/text()')[0]
layout = house.xpath('div[1]/div[2]/div/text()')[0]
location = house.xpath('div[1]/div[3]/div/text()')[0]
value = house.xpath('div[1]/div[6]/div[1]/span/text()')[0]
image_url = house.xpath('a/img[2]/@data-original')
if len(image_url) > 0:
download_img(image_url[0], title)
else:
print(f'{title} 图片不存在...')
print(title)
# 构造详情页 URL
house_detail_url = house.xpath('div[1]/div[1]/a/@href')[0]
sel = download(house_detail_url) # 下载详情页
time.sleep(1)
house_years = sel.xpath('//*[@id="introduction"]/div/div/div[2]/div[2]/ul/li[5]/span[2]/text()')[0]
mortgage_info = sel.xpath('//*[@id="introduction"]/div/div/div[2]/div[2]/ul/li[7]/span[2]/text()')[0].strip() # 去除首尾空格
data['title'].append(title)
data['layout'].append(layout)
data['location'].append(location)
data['value'].append(value)
data['house_years'].append(house_years)
data['mortgage_info'].append(mortgage_info)
writer_to_excel(data)
# 下载页面, 并返回页面信息提取器
def download(url):
html = requests.get(url, headers=headers)
time.sleep(2)
return etree.HTML(html.text)
def download_img(image_url, image_name):
img = requests.get(image_url, headers=headers)
with open('./lianjia_house_image/{}.jpg'.format(image_name), 'wb') as f:
f.write(img.content)
# 将爬取道德数据写入 DataFrame
def writer_to_excel(data):
frame = pd.DataFrame(data)
frame.to_excel('链家二手房数据.xlsx')
# 爬取百度首页 (新闻字体 以及 新闻url)
def grab_baidu():
url = 'https://www.baidu.com/'
response = requests.get(url)
print(response.text)
response.encoding = 'utf-8'
selector = etree.HTML(response.text)
news_text = selector.xpath('//*[@class="mnav"][1]/text()')[0]
news_url = selector.xpath('//*[@class="mnav"][1]/@href')[0]
print(news_text, news_url)
if __name__ == '__main__':
for i in range(1, 3):
print(f'正在爬取 page {i} 页房源信息...')
spider(pre_url + str(i) + '/')
大家跑过程序之后,会发现尤其是在下载图片之后,爬取速度变得非常慢,那么如何加快爬取速度呢?这个时候有些小伙伴可能就会发现,我们的代码中使用了 time.sleep()函数,这个方法不就人为的降低了爬取速度了嘛,把它去掉不就好了。没错,该方法确实降低了爬取速度,但是它是必要的,是不能去掉的。为什么呢?原因有以下两点:
- 在爬取一个网站的时候,应该尽量克制爬取速度,一方面是防止被服务器发现
- 另一方面,爬取行为不可以占用太多服务器资源而影响网站正常用户的访问。
那么我们该如何加快速度呢???下一节我们将讲解如何使用多线程来加快爬取速度,这将会大大提高工作效率。
















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











