









1. 哈希的概念
在进行顺序查找或者二叉搜索树查找时,元素存储的位置和元素各个关键码之间没有对应关系,所以在查找一个元素时必须通过关键码的比较才能判断该关键码所存放的位置,搜索的效率取决与在搜索过程中元素比较的次数。
因此,这个时候就想有这么一种理想的查找算法,可以不经过任何比较,直接从存储元素的表中得到想要查找的数据。
为此,我们构造一种结构,通过某种函数使元素的存储位置和存储的值(关键码)之间存在一一映射的关系,那么我们就可以在查找元素时通过他们之间的关系来直接找到对应的元素。
当向该结构中插入元素时,由给定的函数(哈希函数)计算出该值因该在的位置,然后将元素插入到对应的位置
当我们要在该结构中搜索元素时,通过给定的函数,计算出它应该在的位置,然后直接返回对应位置的元素值。
以上所说的就是哈希(hash)(有叫散列),上面所提到的函数,就是哈希函数(又叫散列函数),通过哈希函数算出来的元素应该存放是位置又叫哈希地址,上面所说的构造出来的用来存放元素的结构,就叫哈希表(又叫散列表)
举个栗子:

但是这个时候就会有一个问题:如果这个时候我还想插入一个12会出现什么问题呢???
2. 哈希冲突
当有两个元素 x 和 y ,x != y,但是有Hash(x) = Hash(y),也就是说对于两个值不相同的元素但是通过hash函数算出来的哈希地址相同,这种现象称为哈希冲突或者哈希碰撞;把具有不同的关键值而具有相同的哈希地址的两个元素称为“同义词”;
那么定发生哈希冲突的时候该如何处理呢???首先我们可以想到的就是哈希函数,因为哈希地址是有哈希函数计算出来的,因此我们先来看看哈希函数...
3. 哈希函数
引起哈希冲突的一个可能的原因就是哈希函数设计的不够合理
3.1 哈希函数的设计原则:
- 哈希函数的定义域必须包括需要存储的 全部关键码,如果哈希表允许有m个哈希地址时,其哈希函数的值域必须在0到m-1之间
- 哈希函数计算出来的值能均匀分布在整个空间中
- 哈希函数应该比较简单
3.2 常见的哈希函数:
-
直接定制法
- 取关键值的某个线性函数为散列地址 : Hash(key) = A * key + B;
- 优点:简单,均匀
- 缺点:需要事先知道关键值的分布情况
- 适合查找比较小且连续的情况(如编程题:找到字符串中第一个只出现一次的字符)
-
除留余数法
- 设哈希表中允许的地址数为m个,取最接近或者等于m的一个质数作为除数,按照哈希函数:Hash(key) = key % p 计算出关键码对应的哈希地址(其中p为等于或者接近m的质数)
-
平方取中法
- 假设关键字为123,它的平方为15129 ;可以取它的中间三位数521作为哈希地址
- 再如关键字为666,它的平方为443556; 可以取它的平方中间的435或者355作为哈希地址
- 适用:适合不知道关键字的分布,而位数又不是很大的情况
-
折叠法
- 折叠法是将关键字从左到右分割成长度相等的几部分(最后一部分可以短些),然后将这几部分叠加求和,根据散列表的长度取后几位作为哈希地址。
- 适用:适合事先不知道关键字序列,且关键字位数比较多的情况。
-
随机数法
- 选择一个随机函数,取关键字的随机函数值作为哈希地址,
- 通常用于关键字长度不等的情况
-
数学分析法
- 设有d个n位数,每一位可能有r中不同的符号,这r中符号在每个位上出现的频率不一定相同,每种符号出现的可能性均等,在某些位上出现的可能性不均等,只有某几种符号经常出现,此时可以根据散列表的大小,选择其中符号分布均匀的几位作为散列地址。
- 例如:手机号前面的大多数都是一样的,可以利用后几位作为判断散列地址的条件,如果这样还容易出现哈希冲突,可以将提取出来的数字在进行逆序,循环左移,循环右移,高两位和低两位求和等方法优化。
注意:哈希函数设计的越精妙,出现哈希冲突的可能性越低,但是不可能完全避免哈希冲突。那么当我们遇到哈希冲突时,又该如何解决呢???
4. 处理哈希冲突
-
闭散列
闭散列:也叫开放地址法,当发生哈希冲突时,如果表还没有被填满,就将当前这个值放入”下一个空位置“中去。
那么问题又来了,怎么找下一个空位置呢?主要有两种方法:线性探测 和 二次探测
线性探测:当发生哈希冲突的时候,从发生冲突的位置开始一次向后探测
插入元素:如果插入位置没有值,就将其直接插入;如果有值,比较要插入的值和当前值是否相同,相同则不用再次插入,不同就依次向后探测,直到有空的位置,将值插入;
查找元素:通过哈希函数算出哈西地址,比较该处的值和要找的值是否相同,相同就直接返回该值,不相同就依次向后找,直到找到该值或者找遍哈希表找不到该值。

二次探测:当遇到哈希冲突的时候,让当前位置朝左右两边探测,找空位置;朝左右两边探测的方法为:
左边:![]() 右边:
右边:![]() (i = 1, 2, 3,……)
(i = 1, 2, 3,……)
也就是说每次探测的时候从用哈希函数计算出来的位置开始,左边和它距离为i平方的位置,右边和它距离为i平方的位置(i从1递增)
比如:
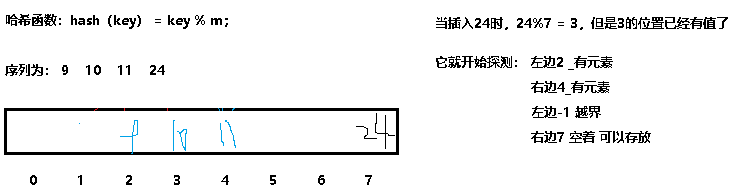
这时候还需要知道一个概念:哈希因子
从上面的存储过程可以看出来,当哈希表元素比较少的时候,还想碰撞几率很小,但是一旦当哈希表快满了,就会出现问题。比如:如果我们用线性探测,如果还剩下一个位置为空,我们可能会将整个哈希表走一遍才能存下最后一个元素;同样,如果使用二次探测来插入元素,本来这个表还剩下几个空间,但是我们跳着跳着就把剩下的空间都错过了,导致元素插入失败。因此使用哈希表的时候,一般不会让表存满了,这时候定义一个数叫做哈希因子α,哈希因子是一个大于0小于1的数;当 哈希表中的元素个数 = 哈希表的大小 * 哈希因子 的时候就相当于‘哈希表存满了’,此时就不应该在想哈希表中插入元素。我们可以理解为到这个时候,如果我们在想其中插入元素,就会使哈希冲突产生的可能性增大。如果这个时候非要向其中插入元素,但是有不想影响哈希表的效率,可以先扩容,然后在将之前的元素在新扩容的空间中再次哈希(因为哈希表中元素的存储和哈希表的下标有关,因此扩容时必须还要使用哈希算法将之前的元素重新插入)存入,在插入新的元素。
散列表的哈希因子 = 已经存入的元素个数 / 哈希表的总大小
哈希因子的大小一般在0.8以下;像Java集合框架中的哈希因子为0.75,一旦元素个数超了就会resize(扩容);
对于开放地址发而言,哈希因子一般在0.7 ~0,8以下,研究发现:如果超过0.8,查表时不命中率按照指数曲线上升;
对于二次探测而言,经过研究表明:当表的长度为质数且哈希因子不超过0.5时,新的元素一定可以插入,而且任何一个位置都不会被探测两次,因此当表中超过一半的空位置,就不存在装满的问题;在搜索时可以不用装满问题,但是在插入时如果哈希因子超过0.5,一定要考虑扩容问题;
-
开散列
开散列法又叫链地址法。所谓的链地址法就是先通过哈希函数计算出各个关键码所对应的地址,将所有地址相同的元素用链表连起来,哈希表中对应的位置只需要存放该链表的头结点地址。
在查找元素的时候,只需要计算出对应的哈希地址,然后遍历链表即可,具体如下图(随便举的几个例子):

使用链地址法看起来好像是多了些指针,占了大量空间,闭散列必须保持大量的空闲空间来保证搜索的效率,比如哈希因子小于0.7之类的限制条件,而表项所需要的空间比指针的空间大得多,因此链地址法和闭散列相比,更加节省空间。















 3041
3041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









