









文章目录
写在前面
我们都知道,volatile解决了变量的可见性,保证了有序性,禁止了指令重排序。
那么,它是怎么做到的呢?
什么是内存的可见性?CPU对指令为什么会重排序?
今天全给你讲明白!
(不熟悉volatile的同学们,请看这个:volatile超详细讲解)
线程的执行过程
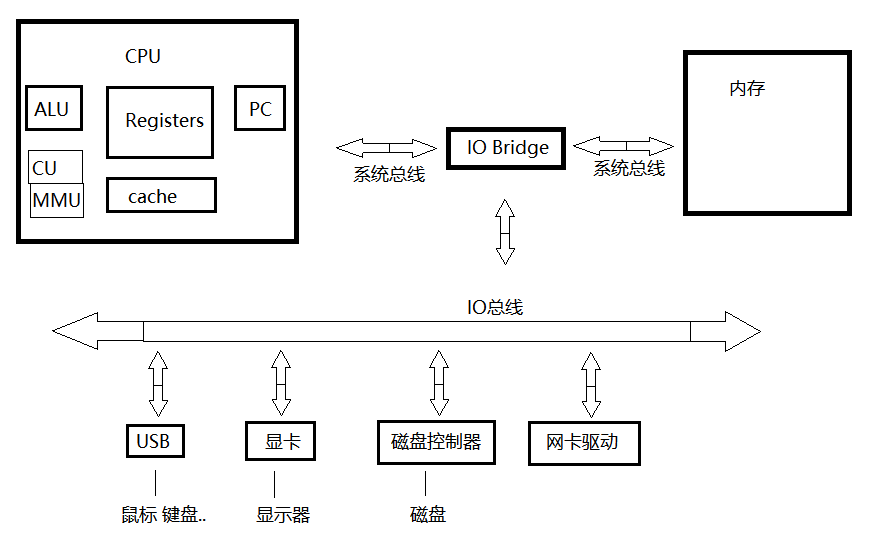
一个java进程执行的过程:打开进程(java程序) -> 将进程需要执行的main程序加载到内存中 -> 将指令加载到PC寄存器,将数据加载到Registers,ALU计算组做计算 ->计算完毕将结果写回内存。
以上是单线程执行的 过程,那么多线程执行过程呢?
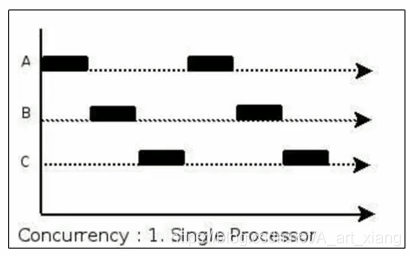
并行(Concurrent)
1.在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理器上运行。
2.并发不是真正意义上的“同时进行”,只是CPU把一个时间段划分成几个时间片段(时间区间),然后在这几个时间区间之间来回切换,由于CPU 处理的速度非常快,只要时间间隔处理得当,即可让用户感觉是多个应用程序同时在进行。
并发(Parallel)
1.当系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,我们称之为并行(Parallel)。
2.其实决定并行的因素不是CPU的数量,而是CPU的核心数量,比如一个CPU多个核也可以并行。
3.适合科学计算,后台处理等弱交互场景。

线程切换
操作系统使用线程调度器来决定cpu执行哪个线程、执行多长时间(线程调度器有许多算法,最新的linux算法是CFS算法)。
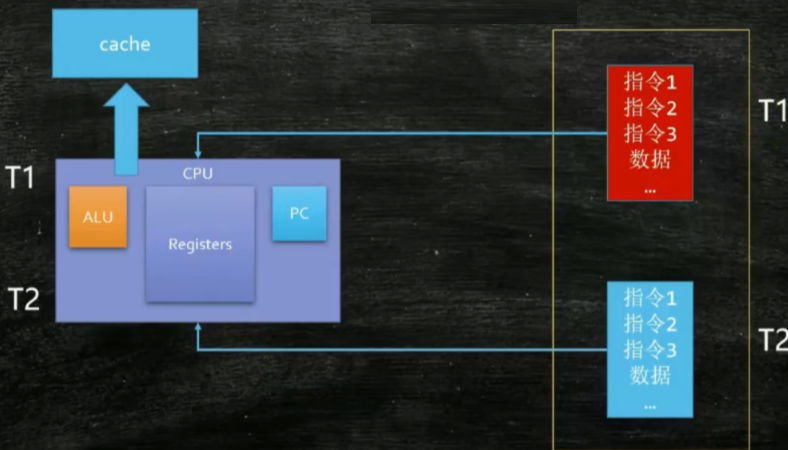
当单CPU做线程切换时,记录上一个线程的数据放入cache缓存,记录指令执行到的位置,开始执行下一个线程。恢复上一个线程时,需要将上一个线程的信息重新读取回来,继续执行,所以CPU切换线程时是需要消耗一定的时间的。
当多CPU执行多个线程时,就不需要线程切换,可以同时执行多个线程。
一颗CPU可以有好几个核;
4核8线程的意思就是,一核CPU可以同时执行2个线程——线程撕裂者,一个ALU对应多个寄存器组(PC+Registers),同一个核的线程切换时不需要从内存中交换资源了,速度大概可以提高100倍(从内存中读取数据比从CPU缓存中读取数据快100倍)。
单核CPU设定多线程是否有意义
是有意义的,CPU执行线程的时候并不是一直在占用CPU的资源,而是有可能在执行的过程中去进行IO(读取硬盘、数据库等等),在这个读取等待的过程中,可以切换CPU时间片来执行另一个线程,深入利用CPU的性能。
工作线程数(线程池中线程数量)设多少合适
1.CPU密集型
// 获取CPU核心数
System.out.println(Runtime.getRuntime().availableProcessors());
CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。
CPU密集任务只有在真正的多核CPU上才可能得到加速(通过多线程)。
而在单核CPU上,无论你开几个模拟的多线程该任务都不可能得到加速,因为CPU总的运算能力就那些
CPU密集型任务配置尽可能少的线程数量:一般公式:CPU核数+1个线程的线程池。
2.IO密集型(分两种情况)
①由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如CPU核数*2。
②IO密集型,即该任务需要大量的IO,即大量的阻塞。
在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。
所以在IO密集型任务中使用多线程可以大大的加速程序运行,即使在单核CPU上,这种加速主要就是利用了被浪费掉的阻塞时间。
IO密集型时,大部分线程都阻塞,故需要多配制线程数:
参考公式:CPU核数/1-阻塞系数(阻塞系数在0.8~0.9之间)
比如8核CPU:8/1-0.9=80个线程数。
工作线程数是不是设置的越大越好
并不是,CPU切换线程是需要消耗时间的,设置越多的线程,CPU就需要保证每一个线程都会执行到,所以会浪费大量的时间用来维护线程和切换线程,反而降低了效率。
可见性
证明内存的可见性
/**
* volatile验证内存的可见性
*/
public class VolatileTest {
public static void main(String[] args) {
Dt1 dt1 = new Dt1();
//新线程,三秒中后将num值设置为100
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " start");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
dt1.setDt();
System.out.println(Thread.currentThread().getName() + " date 0 -> " + dt1.num);
}, "Thread1").start();
while(dt1.num == 0){
//num不变的话会一直卡在这
//num不用volatile修饰的话,会一直卡在这,main的最后一段不会打印
}
System.out.println("main 结束,num值改变了!");
}
}
/**
* 1.不加volatile,num没有可见性。
* 2.添加volatile可以解决可见性问题
*/
class Dt1{
//volatile int num = 0;
int num = 0;
public void setDt(){
this.num = 100;
}
}
多个CPU占用同一个内存(变量)就会造成内存的不可见性的问题,为什么会造成内存的不可见性?
为什么会出现内存的不可见
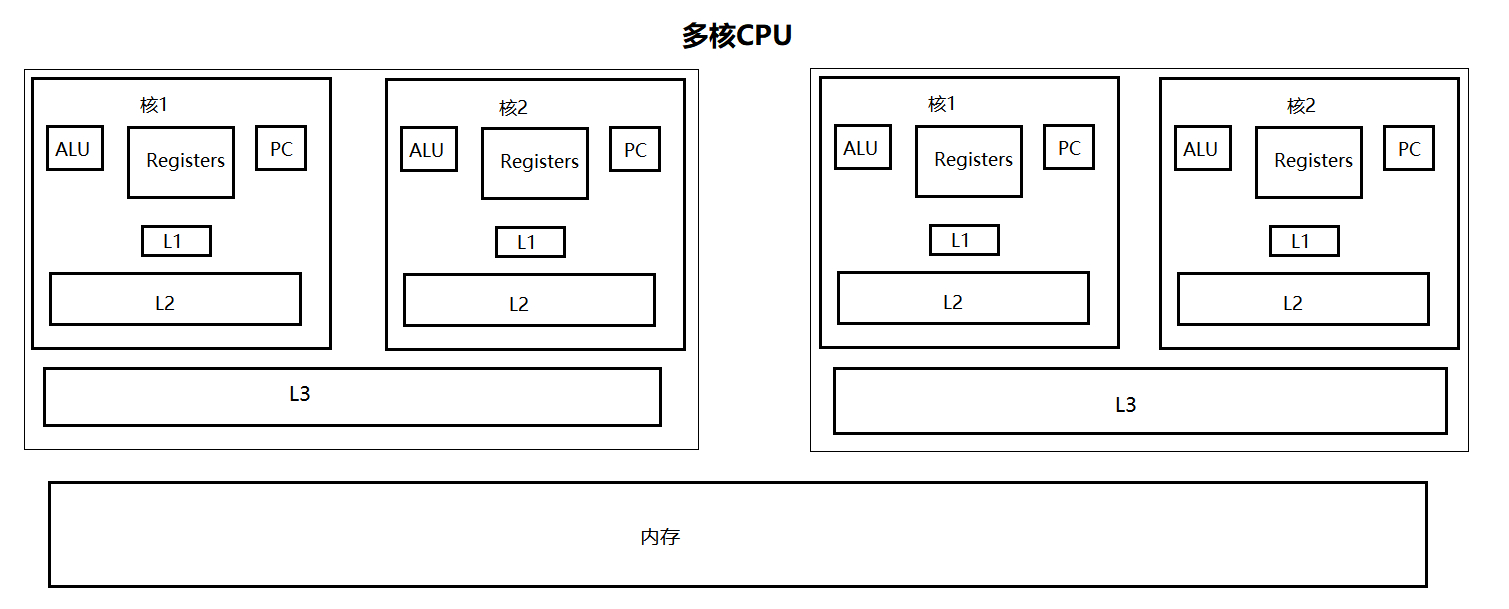
如图,CPU有三级缓存L1、L2、L3。
L1、L2和核在同一个位置上,L3多核共享位于同一颗CPU。
内存中有个变量r=true,读取的顺序是从内存到L3->L2->L1,再次使用的时候是直接使用本地缓存。
当核1使用变量r时,核2也在使用变量r,此时如果核1修改了变量r的值,其实核2并不知道该变量被修改了,所以核2使用的数据还是修改之前的数据。这就是内存的不可见。
计算机层面如何解决内存不可见性
缓存一致性协议,就是解决内存可见性的方式。
Intern的CPU缓存一致性协议叫MESI,其他CPU缓存一致性协议不叫MESI(MSI、MESI、MOSI、Synapse、Firefly、Dragon)。
CPU给每个cache line标记四种状态(额外两位)(Modified、Exclusive、Shared、Invalid),来协助处理缓存一致性。
(什么是cache line缓存行?计算机从内存读取数据时,并不是用到什么读什么,而是一次性读取64字节的数据,它认为你用到了这个数据,大概率会用到这个数据之后的某一些数据,为了提高效率多读了一些)
有了数据的状态,多核CPU就可以知道该数据是否共用、数据是否被另一个线程修改,使用缓存一致性协议将缓存同步,即可解决内存的不可见性。
我们都知道java的volatile关键字可以保证内存的可见性,其本质并不是触发了MESI协议,volatile触发的指令其实是lock指令,MESI协议只能由汇编指令触发-lock指令。
jvm虚拟机规范只说加了volatile修饰的内存修改后能保证可见,具体是怎么实现的不关心,不管是触发lock指令,还是触发MESI,并不重要,只要能保证内存可见性即可。
有序性
实际上计算机并不一定会按照我们写的代码顺序来执行,线程本身是可以乱序执行的。
验证有序性
/**
* 证明cpu的乱序执行
* 当x == 0,y == 0的情况出现,只有cpu执行乱序的时候才会出现。
*
*/
public class Cpu_luanxu_test {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int j = 0;
for(;;) {
j++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(() ->{
a = 1;
x = b; // 排前面去才会出现 x == 0
});
Thread other = new Thread(() ->{
b = 1;
y = a; // 排前面去才会出现 y == 0
});
one.start(); other.start();
one.join(); other.join();
String result = "第" + j + "次(" + x + "," + y + ")";
if(x == 0 && y == 0){
System.out.println(result);
break;
} else {
//System.out.println(result);
}
}
}
}
// 第78794次(0,0)
// 第126032次(0,0)
乱序为什么存在
假如说指令1是从内存中读数据,指令2是在寄存器内部做计算,因为从内存读数据比读cpu的缓存慢100倍,在这读取等待的过程中,CPU在底层执行的时候,为了提高效率,在保证指令乱序后不影响最终的结果的情况下,是有可能将后面的指令提到前面去。
就类似于我烧开水泡茶的时候,完全可以在烧水的过程中去洗茶壶准备茶叶等等。。
什么样的指令才能够乱序
前后没有依赖关系的指令才能够乱序。类似于x = 1;y = 1;完全是有可能乱序的,类似于x = 1;y = x + 1;这是完全不可能乱序的。
在CPU中它只管一件事:不影响单线程的最终一致性。
但是在多线程的情况下,就会出现我们不想要的情况下(上面的小例子)。
new一个对象分为几步
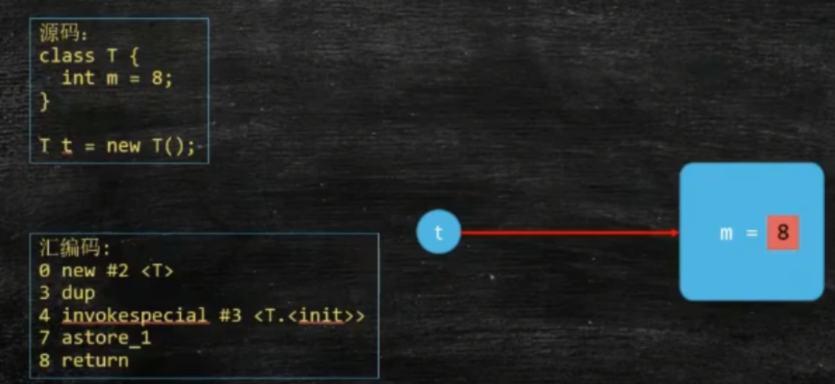
可以说,new一个对象是由三步构成,
1.申请一块内存,存放这个对象,对象中的m初始默认为0(C、C++初始值为随机,为原内存的值,假如说原内存为密码,那么就会将密码读到,java为了安全起见,将这块内存初始为0(int类型));
2.invokespecial是调用构造方法,m设为初始值为8.
3.astore_1建立关联,将局部变量指向引用类型。
其中,第2步、第3步是有可能乱序的,在单例模式下,会有这个隐患
单例模式下指令重排序的隐患
public class SingletonExample {
private /*volatile*/ static SingletonExample singletonExample;
public SingletonExample getInstance(){
if (singletonExample==null){
synchronized (SingletonExample.class){
if (singletonExample==null){
singletonExample=new SingletonExample();
}
}
}
return singletonExample;
}
}
以上,假如说不加volatile,SingletonExample 对象创建的时候第2、3步就有可能乱序。
假如说线程1 调用new SingletonExample()时乱序,局部变量指向引用类型,但是对象里面的变量因为没有调用构造方法初始化,都是默认值。
此时线程2过来获取对象,发现singletonExample不等于null,此时获取的对象就是没有初始化过的对象,会有问题。
为什么volatile修饰了一个对象就可以禁止指令重排
计算机为了两条指令之间阻止重排序,中间可以加一堵墙(内存屏障),每一种cpu的内存屏障指令是不一样的,inter的cpu内存屏障指令有三条(lfance-读,sfance-写,mfance-所有的)。
volatile并不是加了屏障指令,每一种jvm的实现是不一样的。jvm也有内存屏障(jvm级别的实现!并不是cpu级别的实现):
让你了解什么是内存屏障
hanppens-before原则(JVM规定重排序必须遵守的规则)
具体哪些指令可以重排序,哪些指令不可以重排序?JLS(java语言规范)?
1.程序次序规则:同一个线程内,按照代码出现的顺序,前面的代码先于后面的代码,准确的说是控制流顺序,因为要考虑到分支和循环结构。
2.管程锁定规则:一个unlock操作先行发生于后面(时间上)对同一个锁的lock操作。
3.volatile变量规则:对一个volatile变量的写操作先行发生于后面(时间上)对这个变量的读操作。
4.线程启动规则:Thread的start()方法先行发生于这个线程的每一个操作。
5.线程终止规则:线程的所有操作都先行于此线程的终止检测。可以通过Thread.join()方法结束、Thread.isAlive()的返回值等手段检测线程的终止。
6.线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupt()方法检测线程是否中断。
7.对象终结规则:一个对象的初始化完成先行于发生它的finalize()方法的开始。
8.传递性:如果操作A先行于操作B,操作B先行于操作C,那么操作A先行于操作C。
HotSpot虚拟机底层对volatile的实现
hot spot虚拟机实际上是用c++写的,它对用volatile修饰的内存进行了如下操作:
// bytecodeinterpreter.cpp
int field_offset = cache->f2_as_index();
if(cache->is_volatile()) {
if(support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence();
}
}
// orderaccess_linux_x86.inline.hpp
inline void OrderAccess::fence() {
if(os::is_MP()) {
// always us locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0.0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0.0(%%esp)" : : : "cc", "memory");
#endif
}
}
lock指令:解决了内存可见、重排序。
lock用于在多处理器中执行指令时对共享内存的独占使用。另外还提供了有序的指令无法越过这个内存屏障的作用。
lock解释:
lock指令锁总线:我这个cpu访问这个数据的时候,其他cpu不可以通过总线去访问。只有等我访问完了,其他人才能继续。这样就能保证顺序执行了。
lock:把当前处理器对应的缓存的内容,刷新到内存,并使其他处理器对应的缓存失效(触发了MESI)。保证了可见性。
这里是直接加上lock了,锁的粒度太大,没有使用精准的内存屏障指令(lfance-读,sfance-写,mfance-所有的),仅仅是因为懒,lock指令对所有的cpu都支持,内存屏障指令每种cpu不一样。。
实际上addl指令的意思是在某个寄存器rsp、esp 加上某个数,这里加了0,实际上这个addl指令并没有任何意义。原因是lock指令后面必须得跟一个指令,只能跟一条没有意义的指令。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











