






-
微信开发者工具中未勾选不校验合法域名设置
未勾选这个设置在任何环境下发送http网络请求会失败
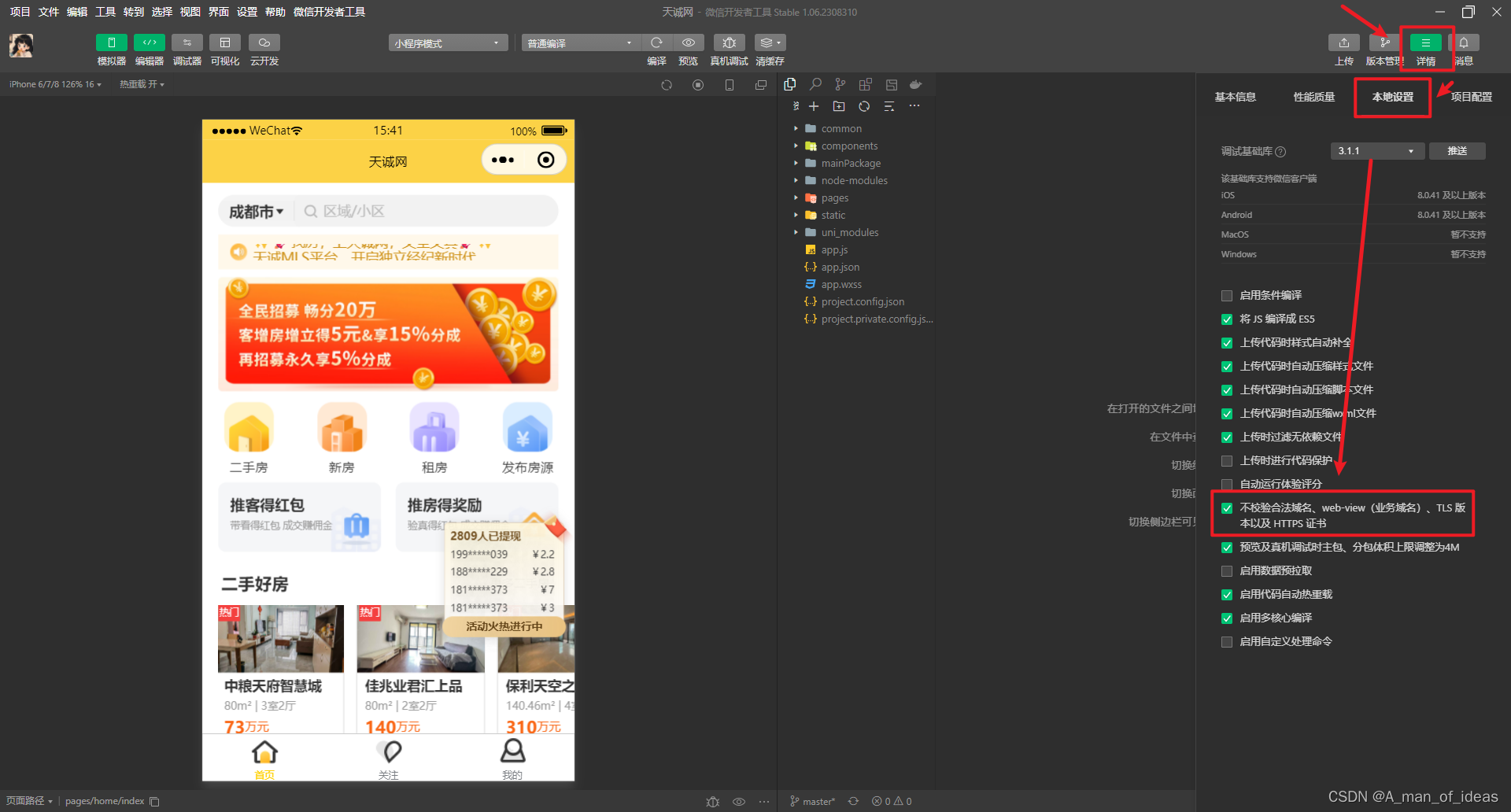
发送的是https请求,但网络请求依旧是失败
需要到官方的微信小程序后台的 开发管理 -> 开发设置 -> 服务器域名配置位置进行域名的配置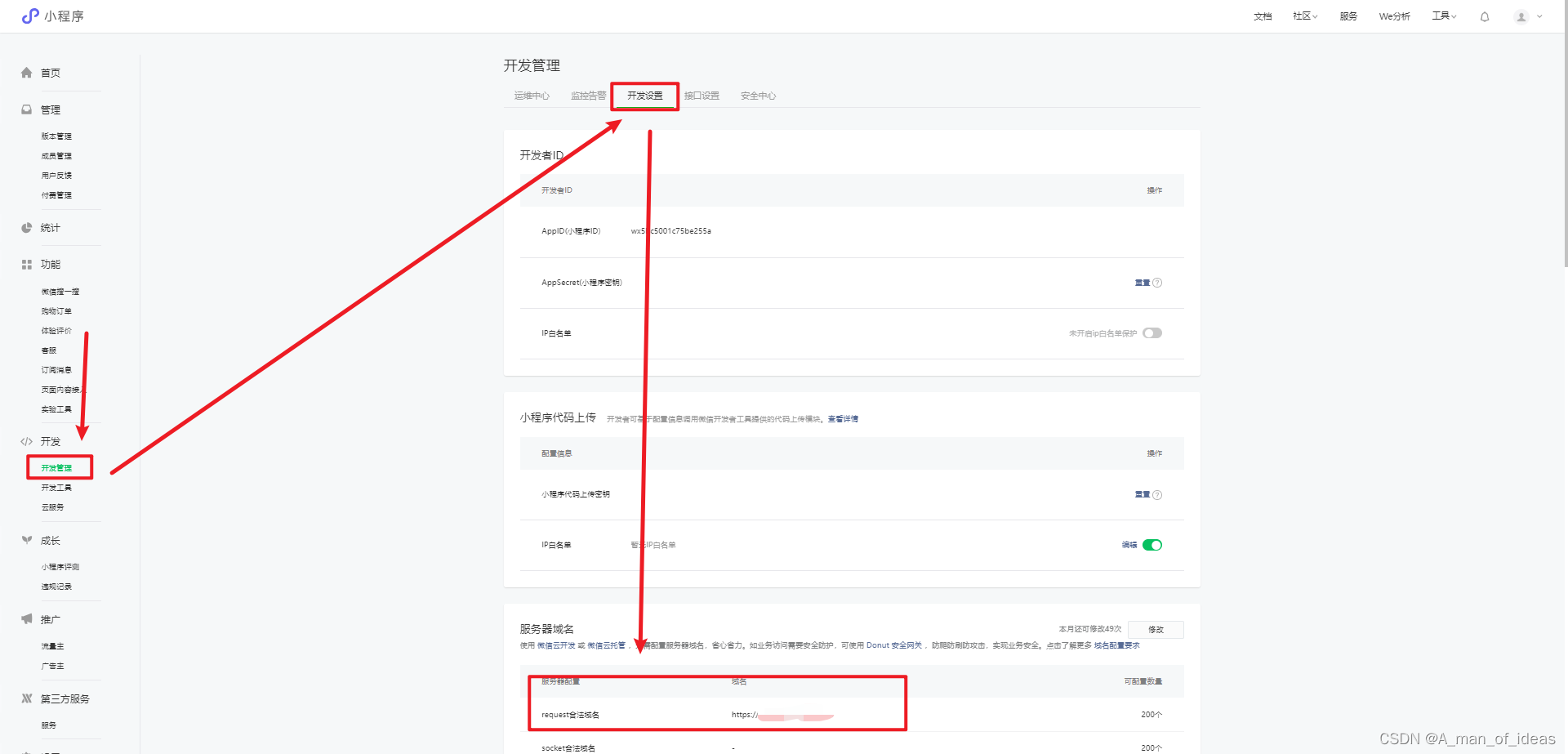
-
在体验版环境下无法发送http网络请求
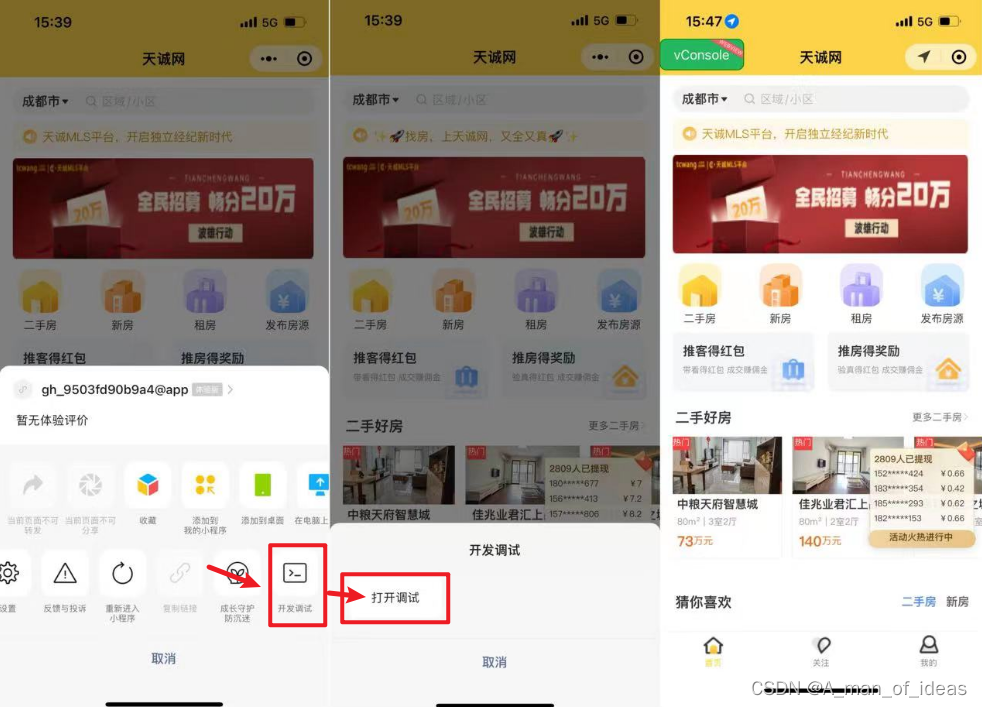
点击小程序右上角 ··· 打开菜单
- 点击开发调试按钮
- 打开调试
- 打开后需要重新打开小程序
- 然后小程序界面中出现绿色的 vConsole 按钮即可
未勾选这个设置在任何环境下发送http网络请求会失败
需要到官方的微信小程序后台的 开发管理 -> 开发设置 -> 服务器域名配置位置进行域名的配置
点击小程序右上角 ··· 打开菜单

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1万+
1万+





