







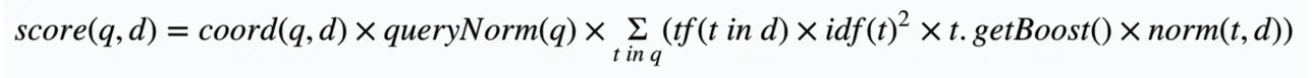
D:文档
Q:查询条件
score(D,Q):指使用Q的查询语句在该文档下的打分函数
coord(q,d):得分因子,score factor,一个文档中包含越多的查询Term词,则该文档的得分越高,对应lucene类TFIDFSimilarity.coord(int overlap, int maxOverlap);
queryNorm(q):归一化因子,normalizing factor,使得不同查询间的得分具有可比性,但并不会影响文档的排序,
tf(t in d):Term在文档d中出现的次数,对应lucene类TFIDFSimilarity.tf(float freq);
idf(t):Term的逆文档频率,即一个Term在所有文档中出现的次数越多,重要性越小,对应lucene类TFIDFSimilarity.idf(long docFreq, long numDocs);
norm(t,d):封装了文档字段field的权重和field内容长度因子,在index时计算,对应lucene类 TFIDFSimilarity.computeNorm(FieldInvertState state);
lengthNorm:field内容长度因子,field字段内容长度越短,则值越大,对应lucene类TFIDFSimilarity.lengthNorm(FieldInvertState state);















 4788
4788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









