






整形:数字 int(整型),在python2中数字过大的话,叫做长整型; 不过在python3中就没有长整型的概念了,数字再大也叫做整型。
浮点数:
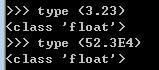 52.3E4 = 52.3*10**4 = 523000.0
52.3E4 = 52.3*10**4 = 523000.0
复数:不常用
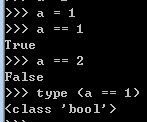
布尔值:布尔值就是True和False,也就是对和不对(1和0)
字符串:string

bytes:
在Python3以后,字符串和bytes类型彻底分开了。字符串是以字符为单位进行处理的,bytes类型是以字节为单位处理的。
bytes数据类型在所有的操作和使用甚至内置方法上和字符串数据类型基本一样,也是不可变的序列对象。
bytes对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。Python3中,bytes通常用于网络数据传输、二进制图片和文件的保存等等。可以通过调用bytes()生成bytes实例,其值形式为 b'xxxxx',其中 'xxxxx' 为一至多个转义的十六进制字符串(单个 x 的形式为:\x12,其中\x为小写的十六进制转义字符,12为二位十六进制数)组成的序列,每个十六进制数代表一个字节(八位二进制数,取值范围0-255),对于同一个字符串如果采用不同的编码方式生成bytes对象,就会形成不同的值.
b = b'' # 创建一个空的bytes b = byte() # 创建一个空的bytes b = b'hello' # 直接指定这个hello是bytes类型 b = bytes('string',encoding='编码类型') #利用内置bytes方法,将字符串转换为指定编码的bytes b = str.encode('编码类型') # 利用字符串的encode方法编码成bytes,默认为utf-8类型 bytes.decode('编码类型'):将bytes对象解码成字符串,默认使用utf-8进行解码。
对于bytes,我们只要知道在Python3中某些场合下强制使用(python3网络编程,需要将str转换成bytes),以及它和字符串类型之间的互相转换,其它的基本照抄字符串。
简单的省事模式:
string = b'xxxxxx'.decode() 直接以默认的utf-8编码解码bytes成string
b = string.encode() 直接以默认的utf-8编码string为bytes
参考链接:https://www.cnblogs.com/R-bear/p/7744454.html
列表:
#Author:Peng Huang list1 = ['huang','ma','shang','zhai','zhang'] list2 = [11,22,33,44,55] print(list1[1]) #切片取值,取第二个值 print(list1[1:4]) #切片取值,取第二个到第四个值 print(list1[-1]) #切片取值,取倒数第一个值 print(list1[-3:-1]) #切片取值,取倒数第二和第三的值(取值都是从左往右数) print(list1[-3:]) #切片取值,取后三位的值 print(list1[:3]) #切片取值,去前三位的值 list1.append('zhou') #列表末尾增加新对象 print(list1) list1.insert(1,'cui') #列表第二位插入新对象 print(list1) list1[1] = 'qiu' #修改列表第二位的值 print(list1) list1.count('ma') #查看ma在列表出现的次数 print(list1.count('ma')) list1.index('ma') #查看ma第一个匹配项的索引位置 print(list1.index('ma')) list1.remove('ma') #根据某个值移除第一个匹配项 print(list1) del list1[1] #删除第二个元素 print(list1) list1.pop(1) #删除第二个元素,如果list1.pop(),不加参数,默认删除最后一个元素 print(list1) list1.reverse() #反向列表元素 print(list1) list1.extend(list2) #列表扩展 print(list1) list1.clear() #列表清空 print(list1)
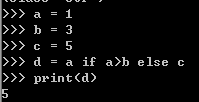
拾遗:三元运算 如果a>b d=a ,否则d=c
列表步长切片
这个步长和range(0,10,2) 的步长是一样的
kl = ["OPPO","VIVO","IPHONE","LEVOVO"] print(kl[1::2])
结果:['VIVO', 'LEVOVO']
因为:从下标1的数据开始取值,取后面全部的值, 并且取值的时候设置了步长,取值的时候跳着取,跳2个下标
可以这样理解:开始的时候下标是1 设置的步长是2 那么就是, 去下标是1 的数据, 还会去 1+步长(2) =3 那么会取下标是3 的数据,再往后就是结果3+步长(2)=5,系统会取下标是5 的数据, 在往后的话就是结果5+步长(2) =7 系统就会取下标是7的数据















 2602
2602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









