









Kettle 数据抽取【Version 6.1】
背景
需要按一定规则从数据库抽取量比较大的数据。使用ETL工具完成。
简述
Kettle是国外开源的ETL工具,Java编写。后来改名PDI
转换(transformation)和工作(job)的区别:
转换是数据流,工作是步骤流,作业的每个步骤必须等前面的步骤都跑完了,后面的步骤才会执行,而转换会一次性把所有控件启动(一个控件对应一个线程)然后数据流会从第一个控件开始,一条记录一条记录地流向后面的控件。
安装使用
安装
绿色无需安装,下载解压就能使用。
设置系统变量(KETTLE_HOME)
PDI的默认配置文件保存在用户目录下的.kettle目录的kettle.properties文件中(C:\Users\Administrator\ .kettle)
设置KETTLE_HOME环境变量的值是:D:\Program Files\pdi-ce-9.1.0.0-324。重启之后在D:\Program Files\pdi-ce-9.1.0.0-324.kettle目录下可以看到kettle.properties配置文件。
使用
双击 Spoon.bat 启动
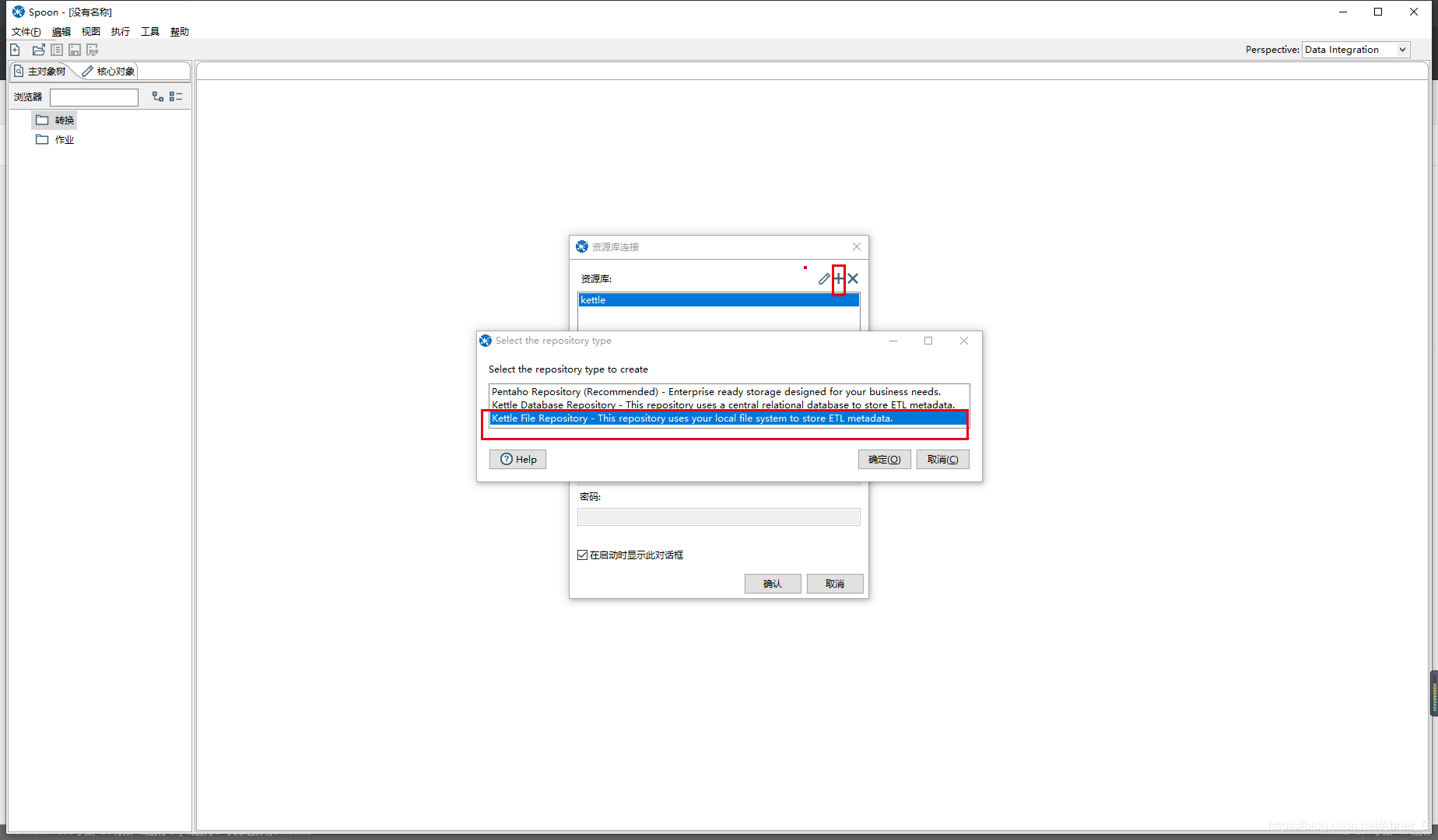
Kettle提供3种资源库,分别是数据库资源库、Pentaho资源库和文件资源库,本文以文件资源库为例。
工具->资源库->连接资源库 【CTRL+R】
刷新资源库【CTRL+E】
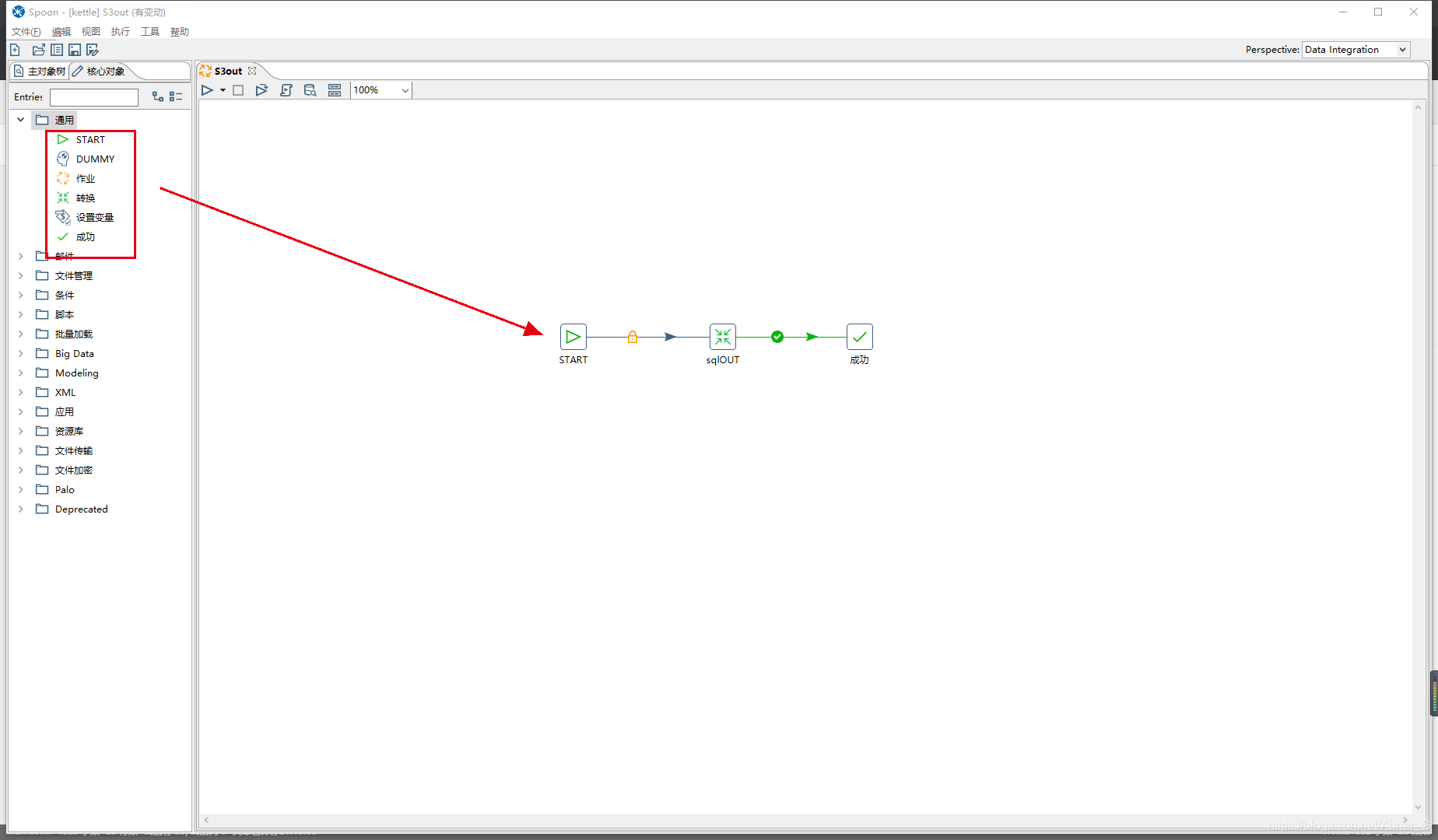
首先创建一个“工作”,建立一个简单的工作流
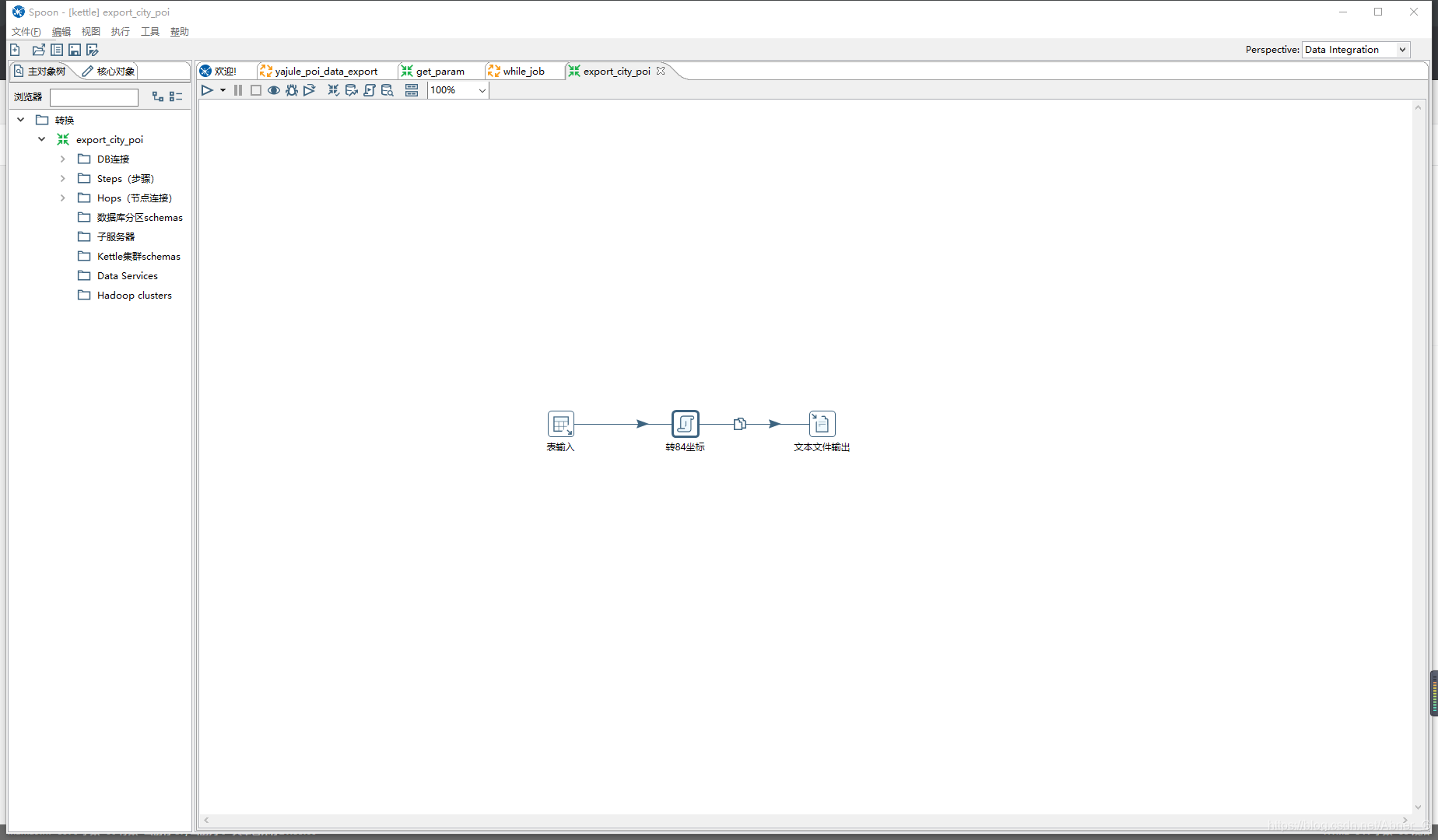
进入转换,进行具体操作
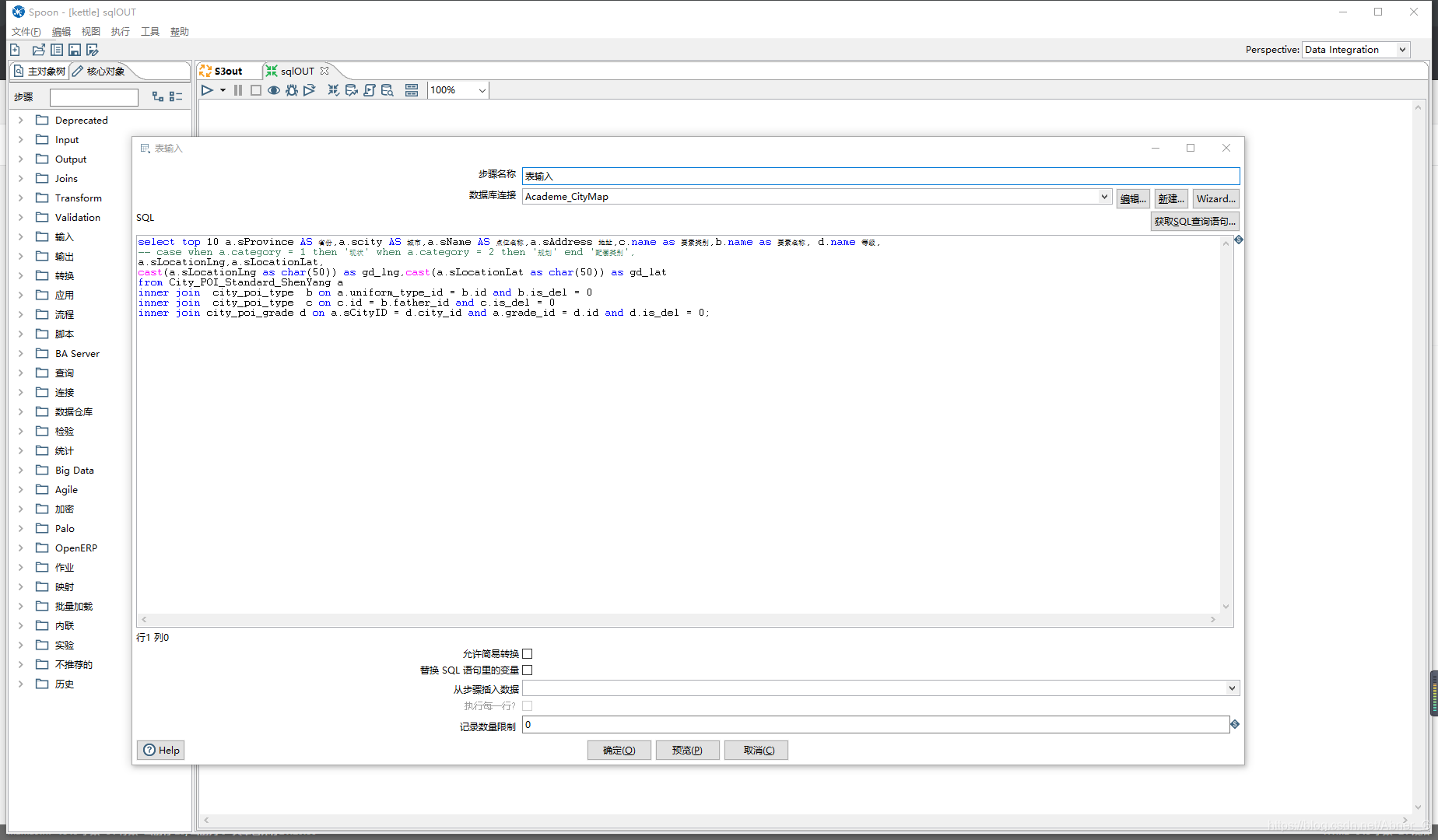
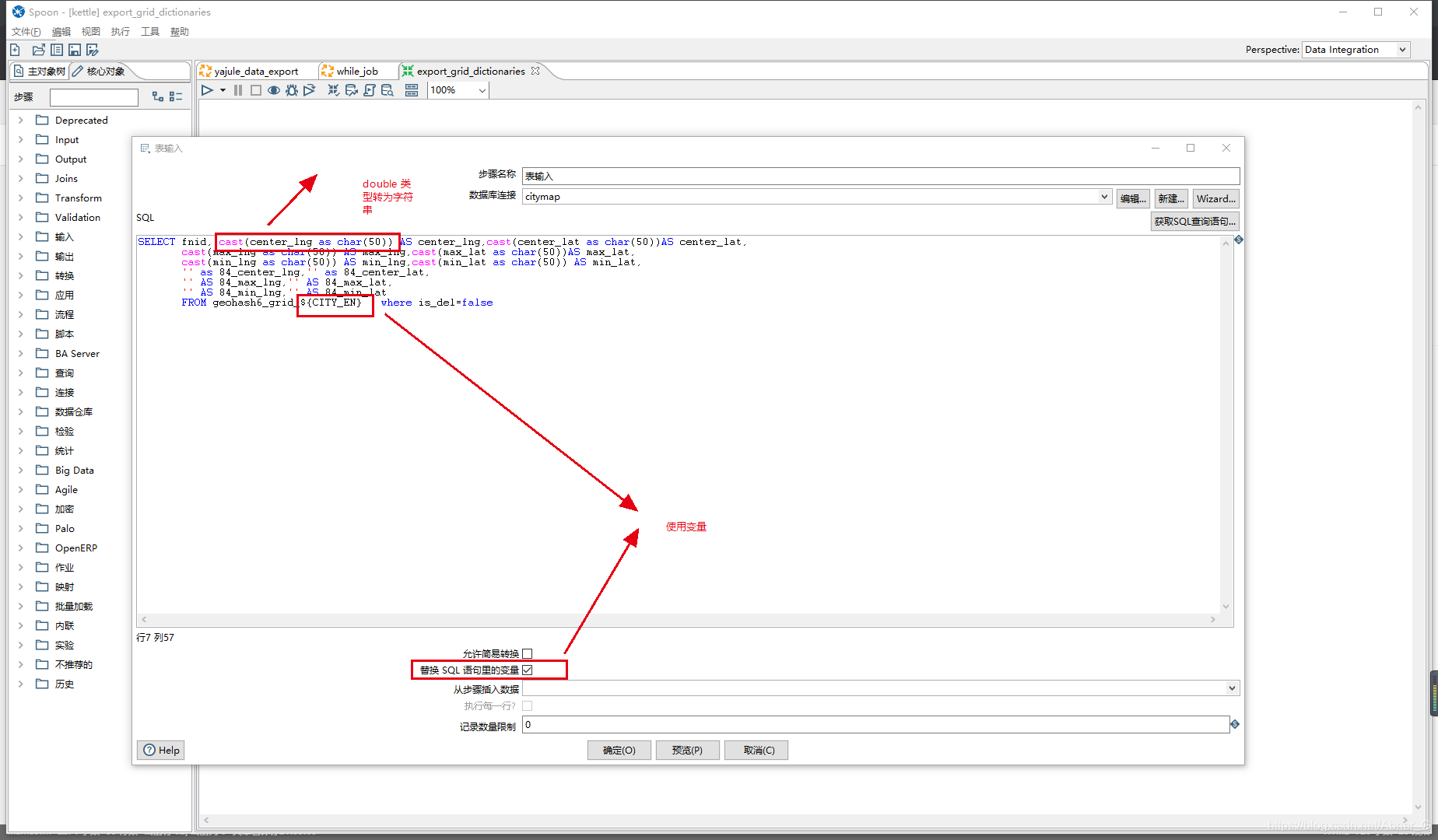
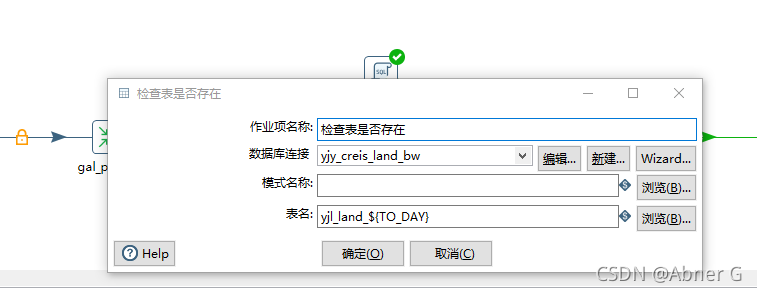
表输入注意点
- 如果sql中使用变量,替换变量选项一定要勾。
- 返回数据类型如果有int,double类型数据,转为字符串类型。默认识别可能会丢失精度
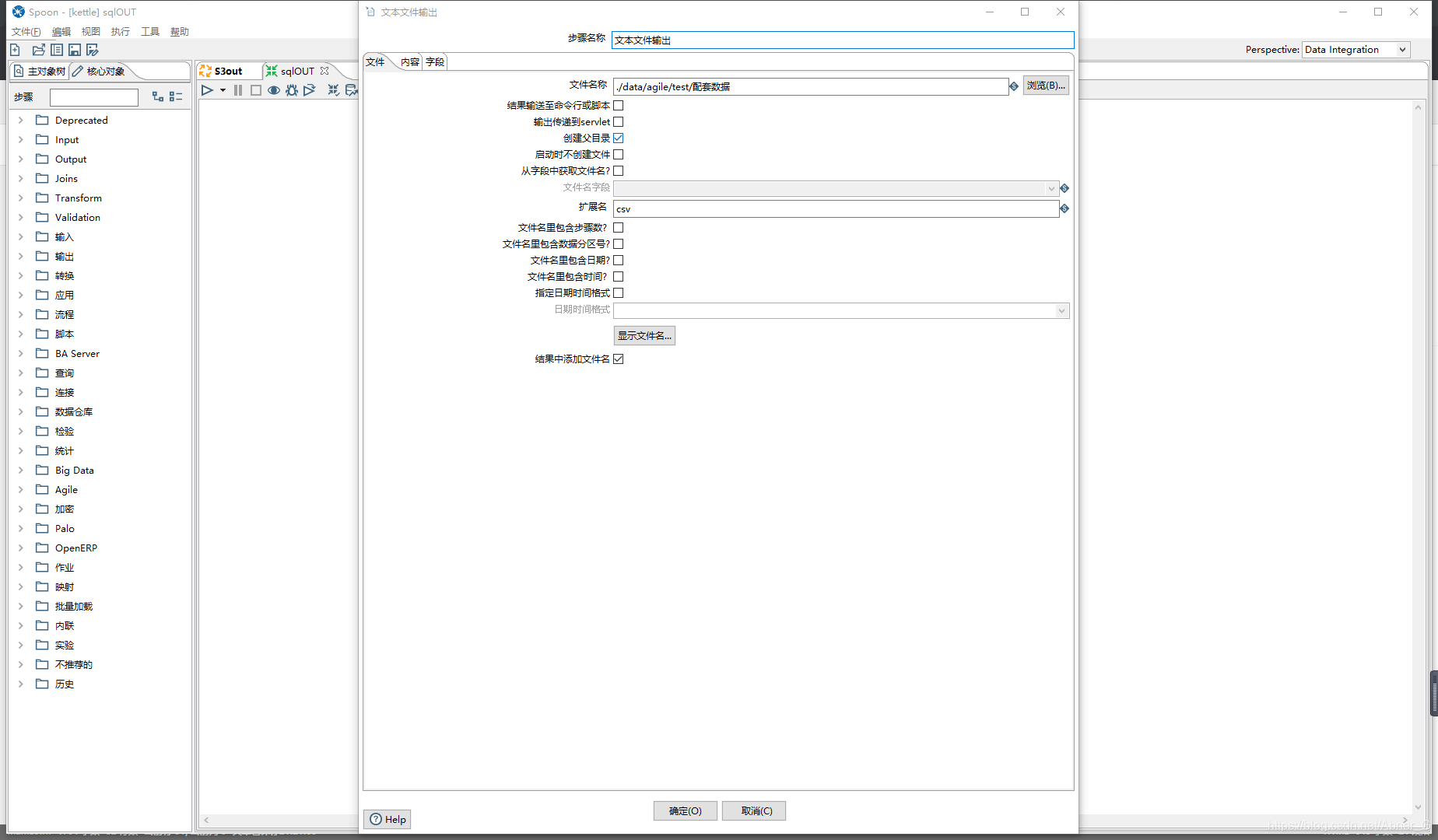
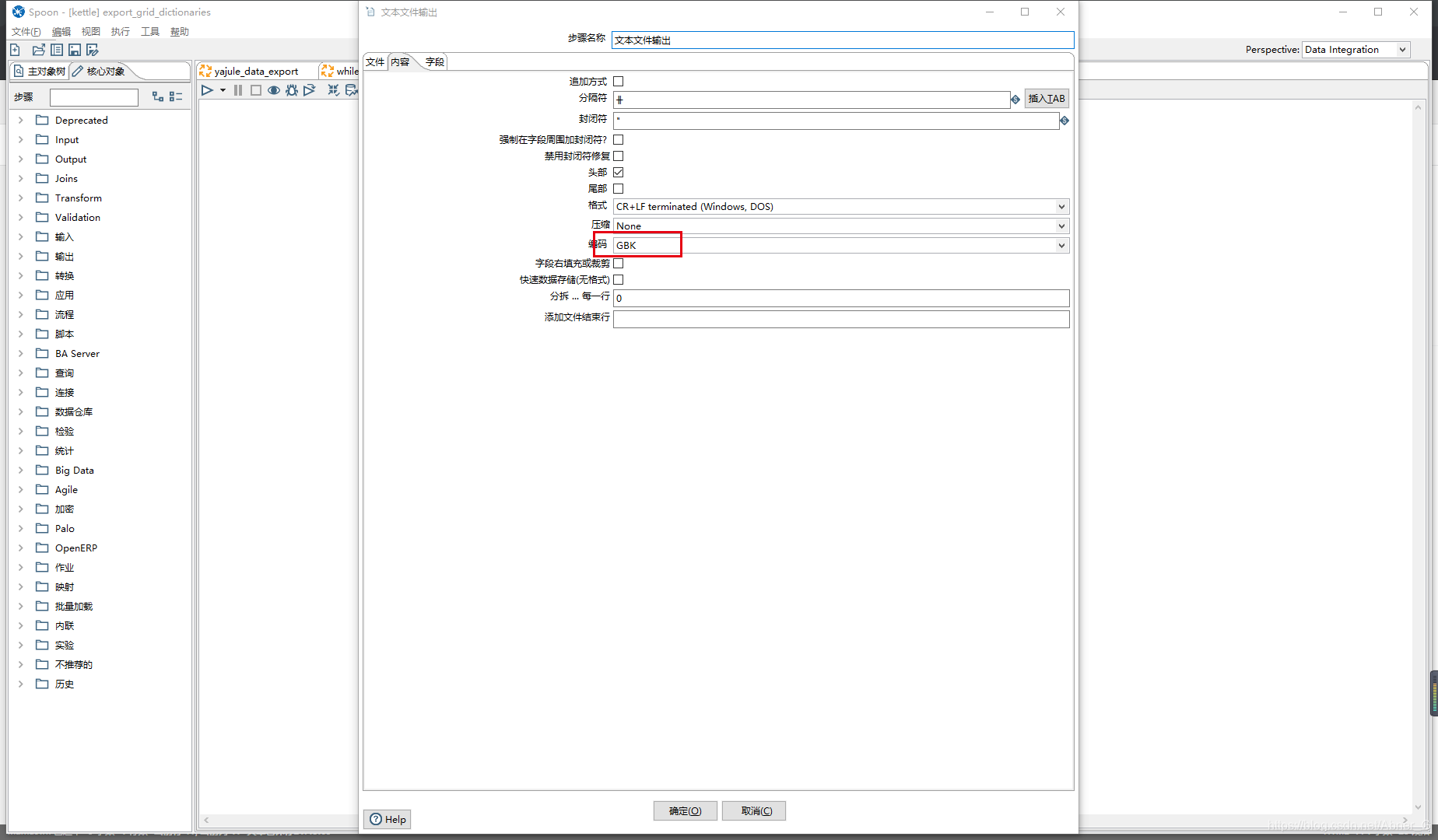
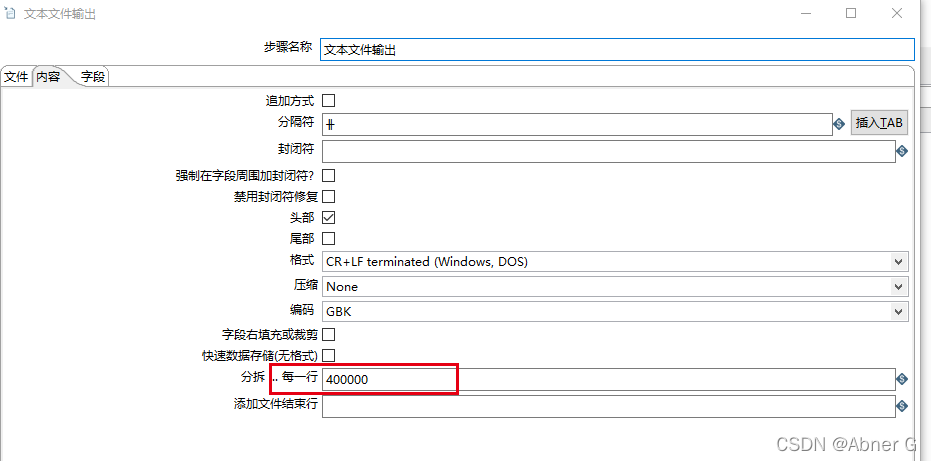
文本文件输出注意点
- 需求为输出为CSV文件,使用UTF-8编码会造成中文乱码。改为GBK解决中文乱码
- 字段获取的时候,要点一下最小宽度。不点的情况下,默认识别数据的宽度不确定(如果数据不够宽度以空格填充)这样会造成文件太大。浪费空间。
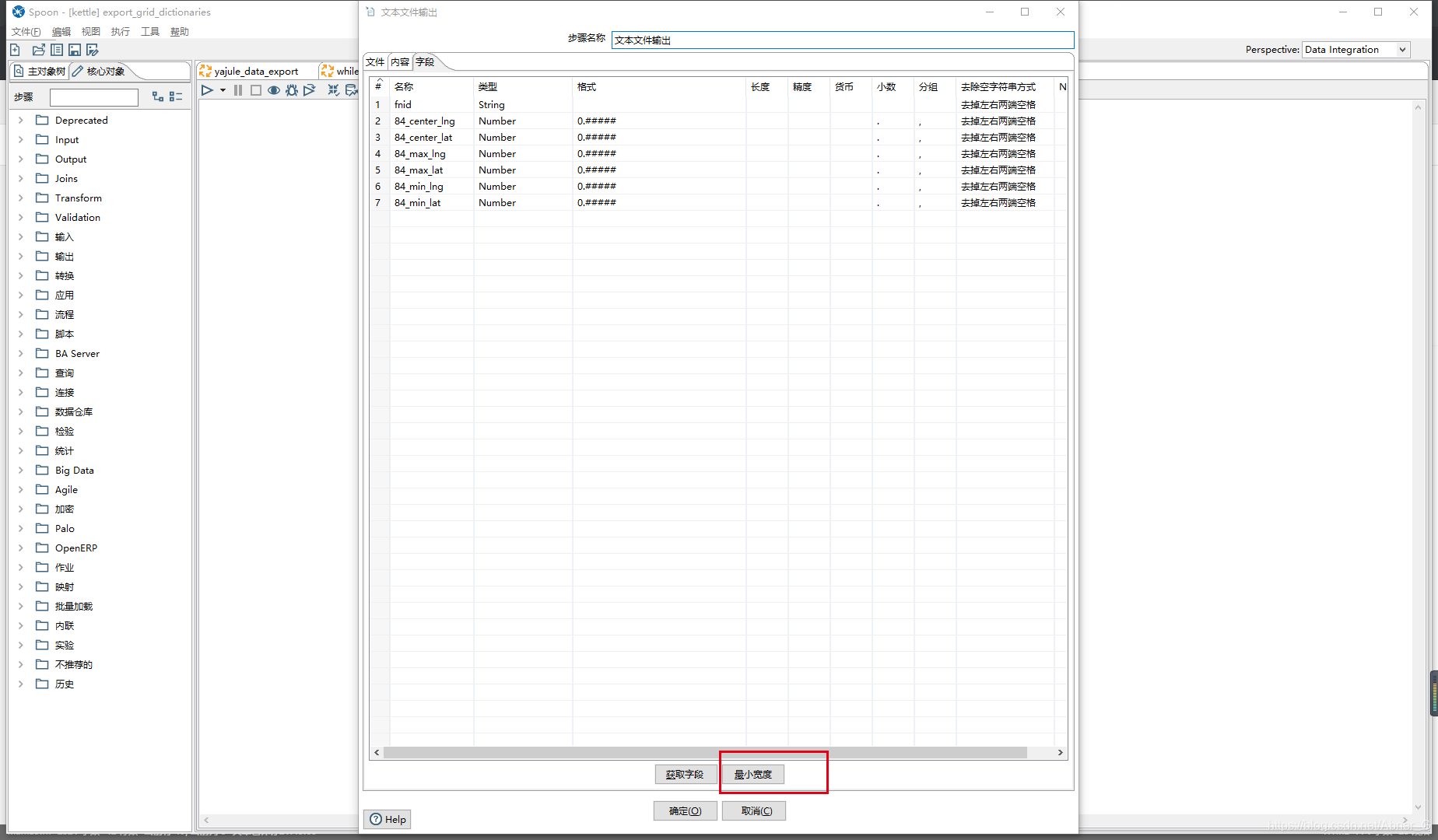
按数据量分多个文件导出
循环
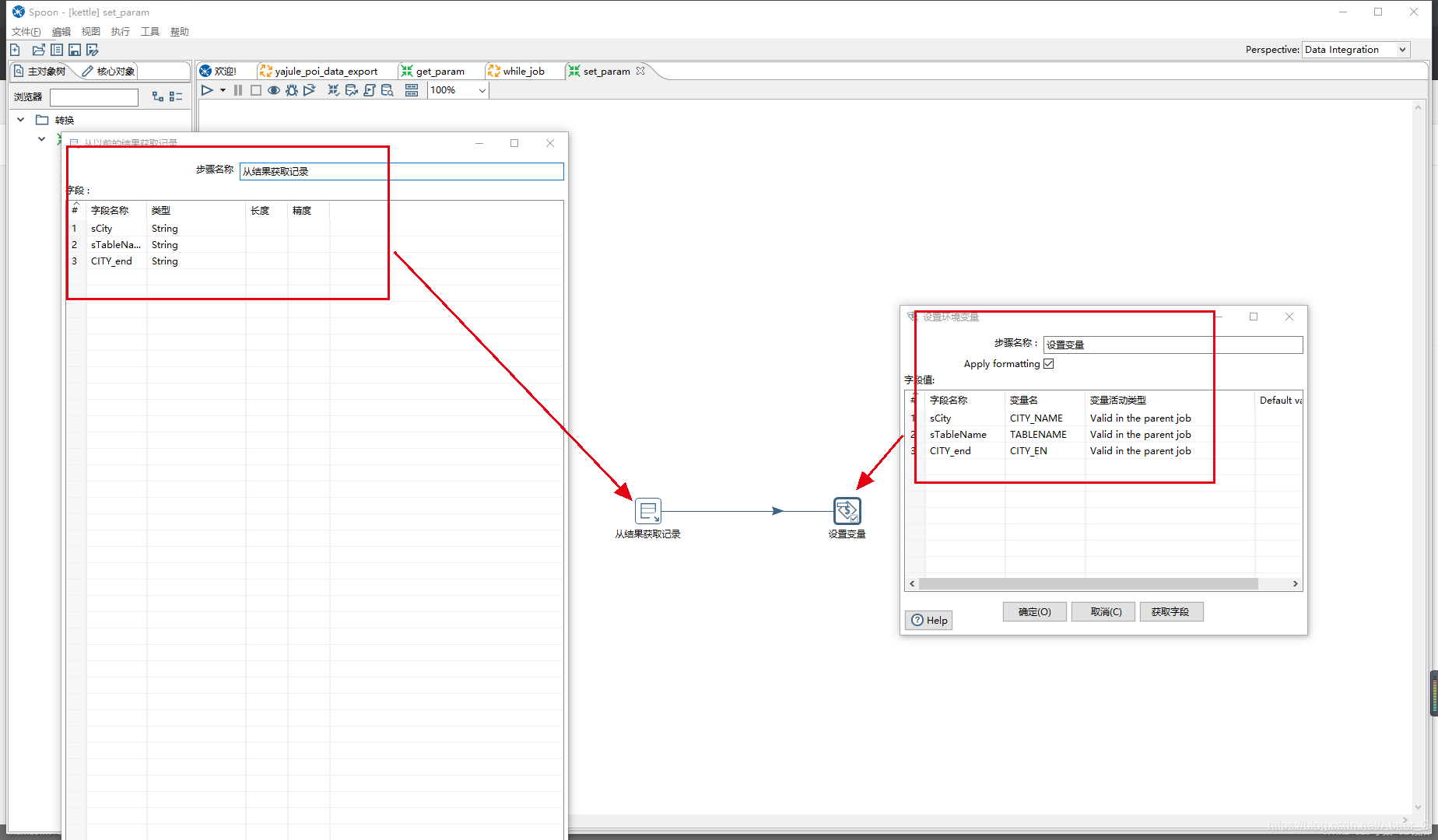
设置参数
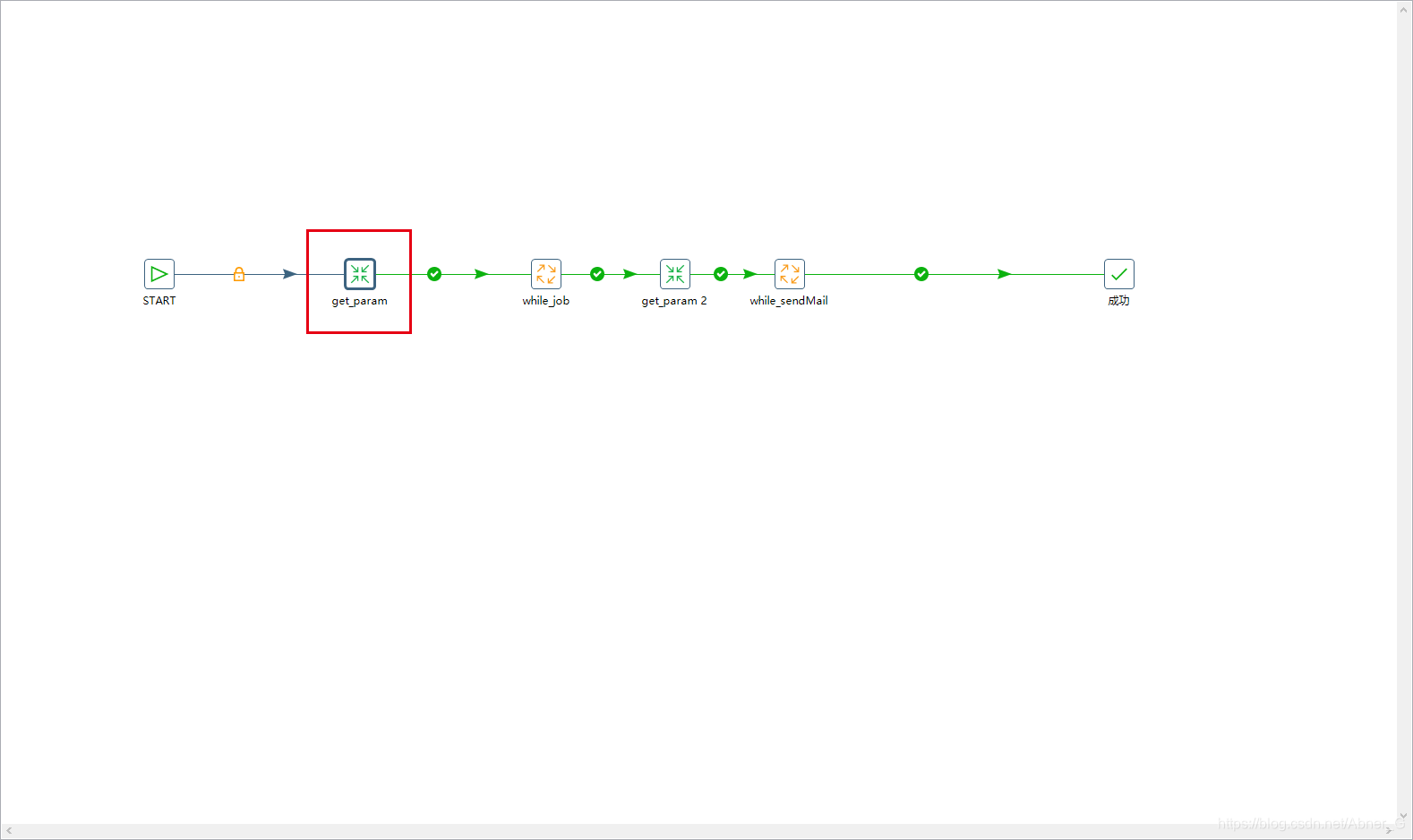
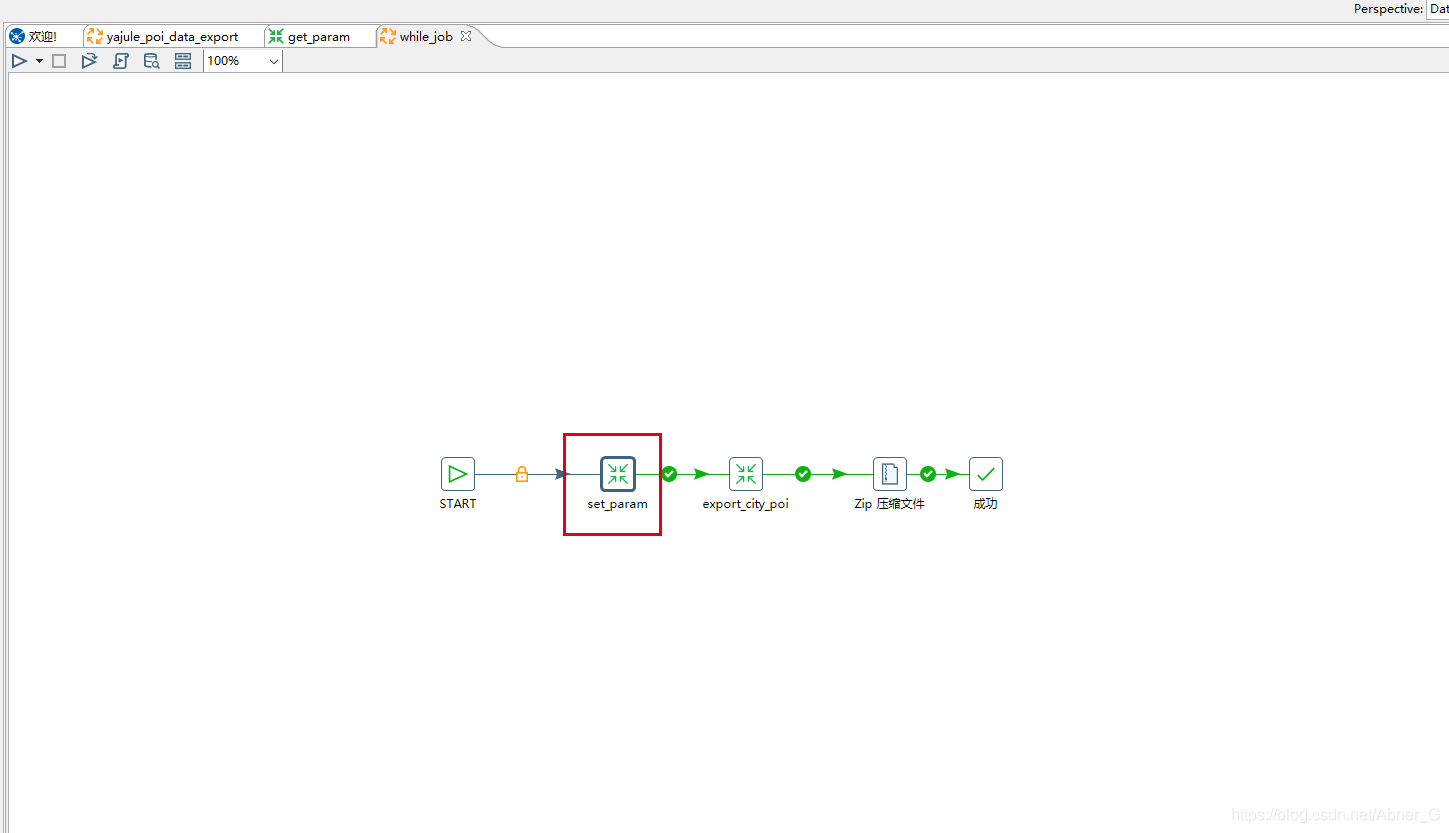
接下来使用一个JOB循环
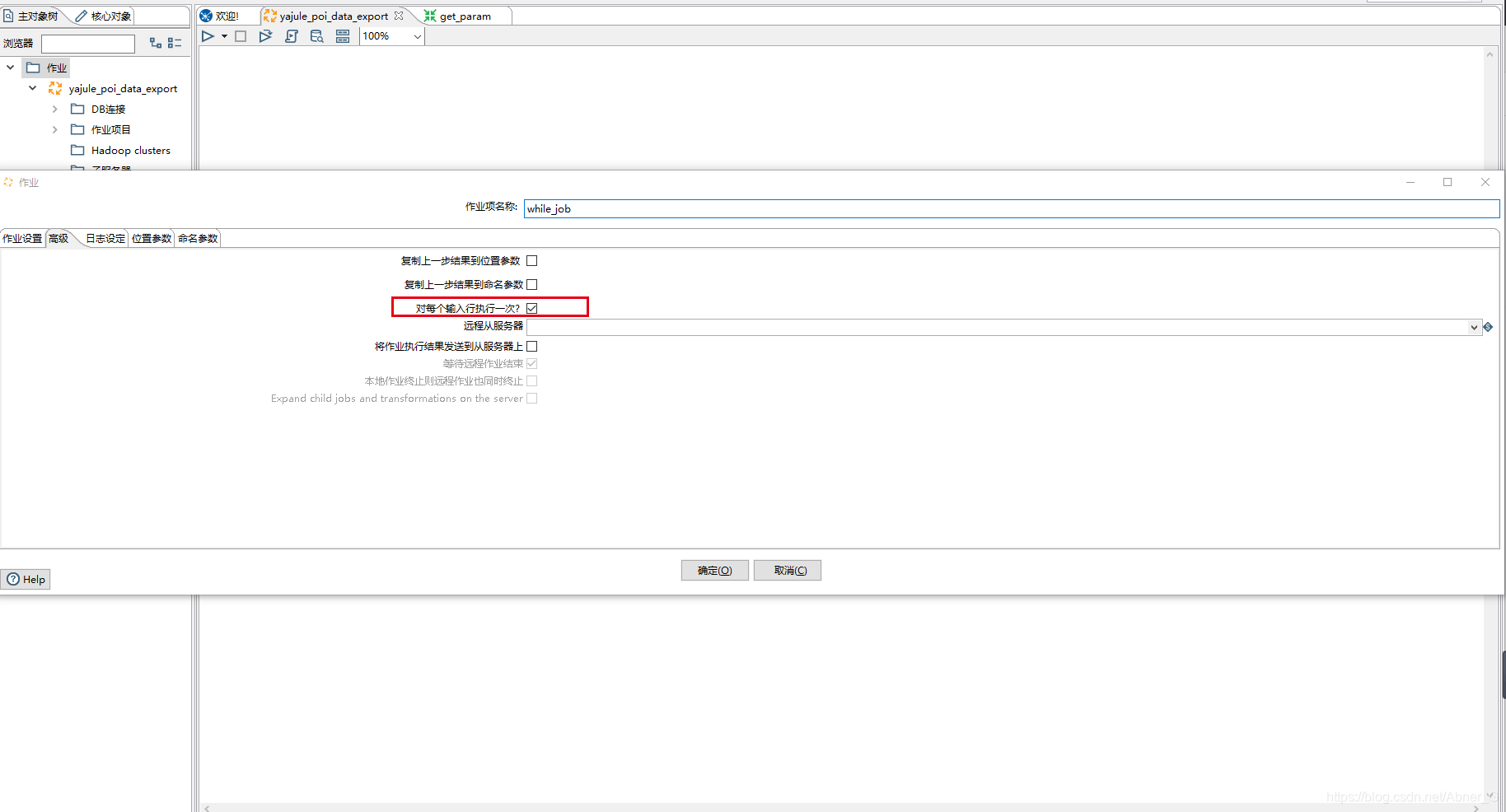
循环job注意点
- 高级设置 要勾选对每个输入行执行一次?
job中接收获取参数
java代码
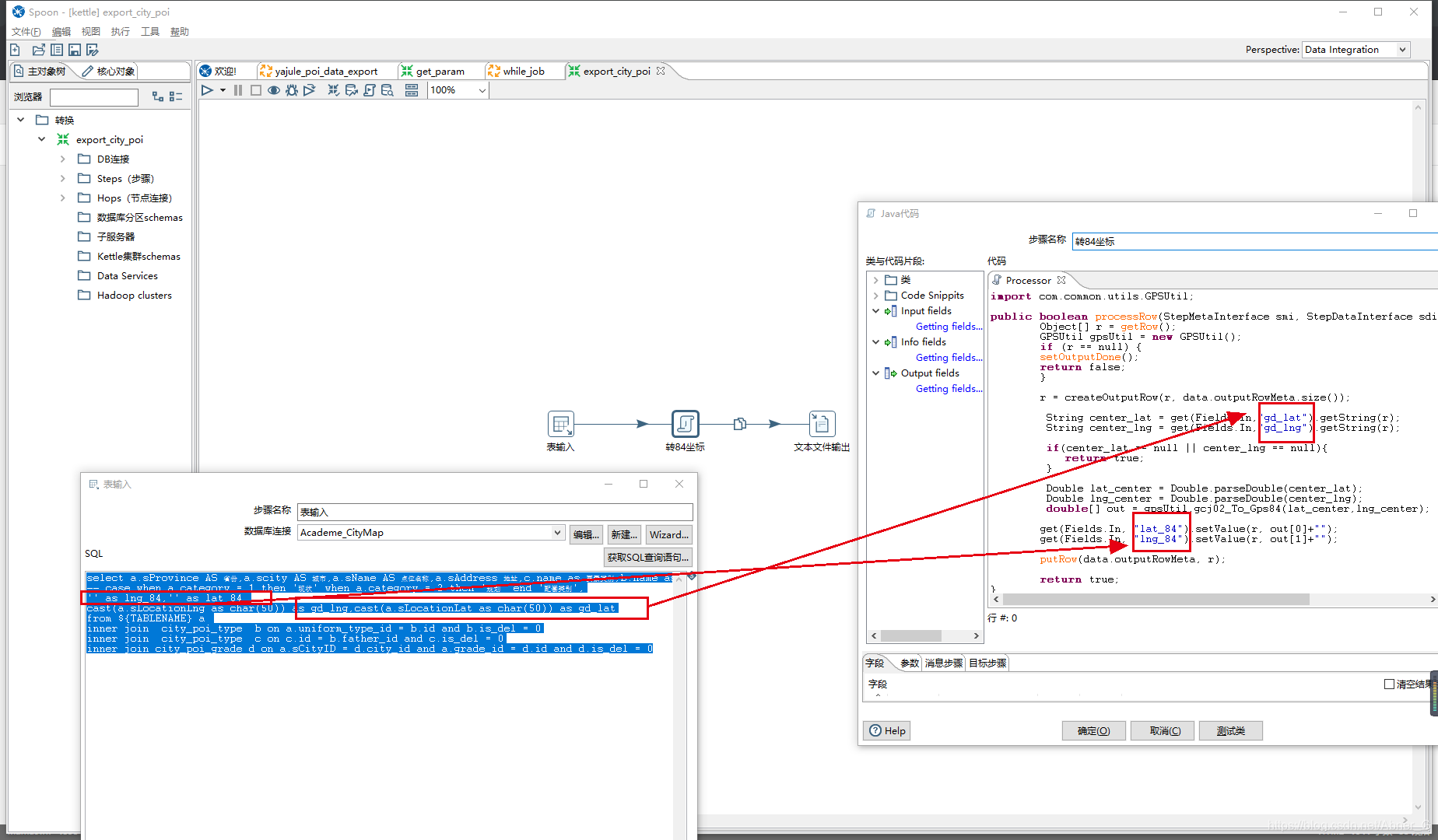
java代码注意点
如果要对值做转换,需要一个新属性来接受,不能在原属性覆盖
此处gd_lat—>使用lat_84接收
压缩文件
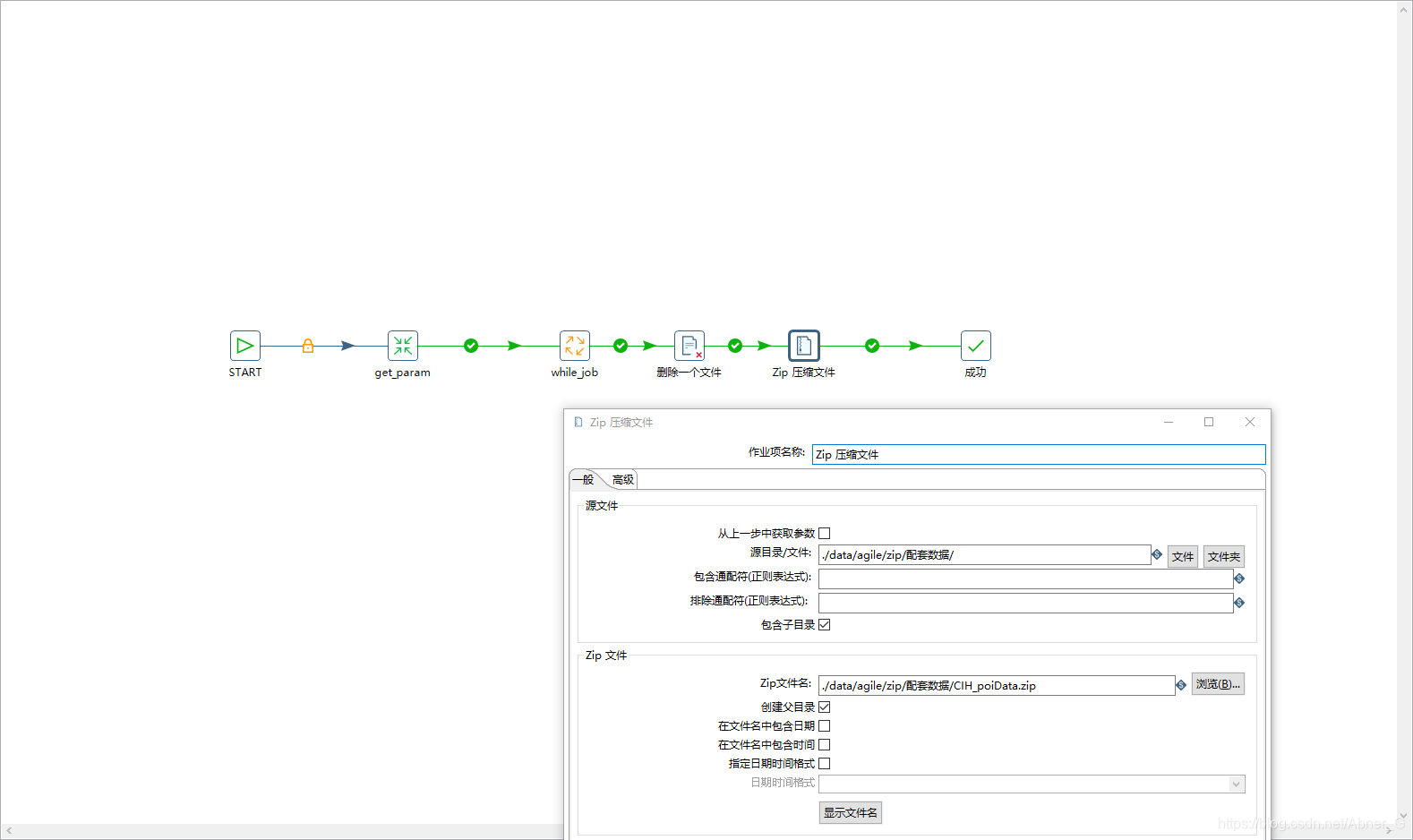
压缩文件注意点
压缩文件,如果(高级设置)zip存在的情况下,没有覆盖的功能。所以要在压缩之前加一个删除文件。避免不压缩
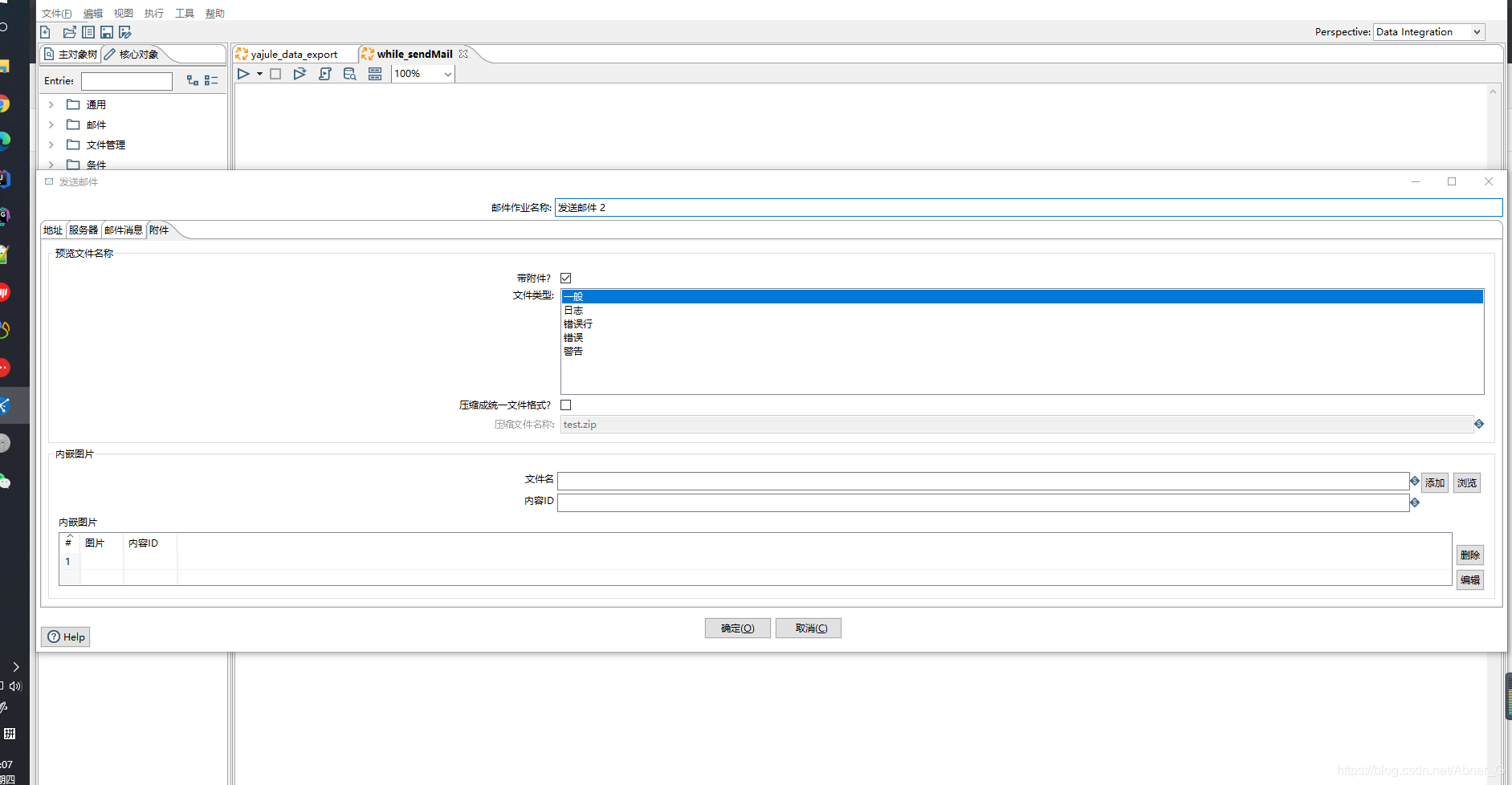
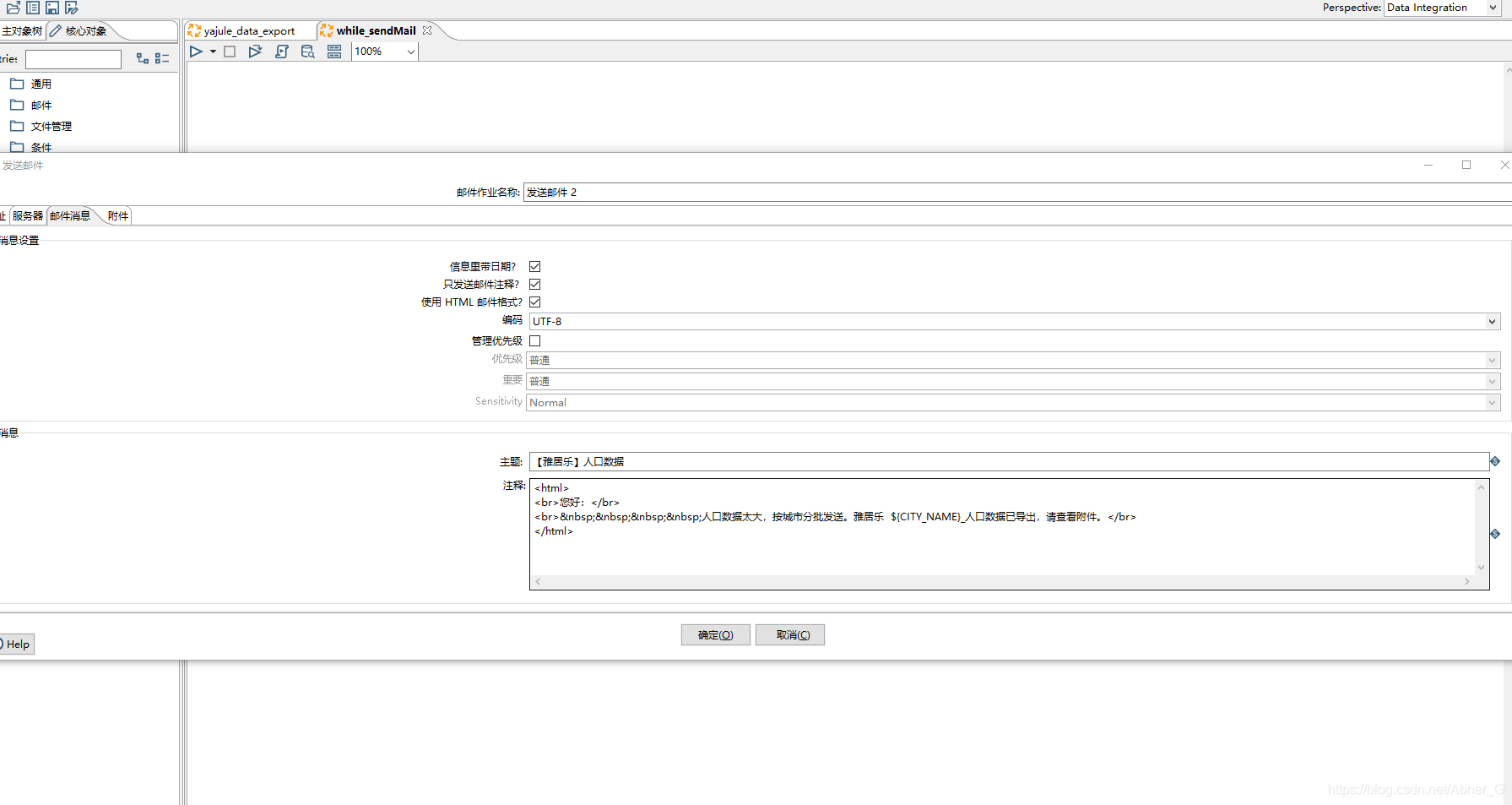
邮件控件
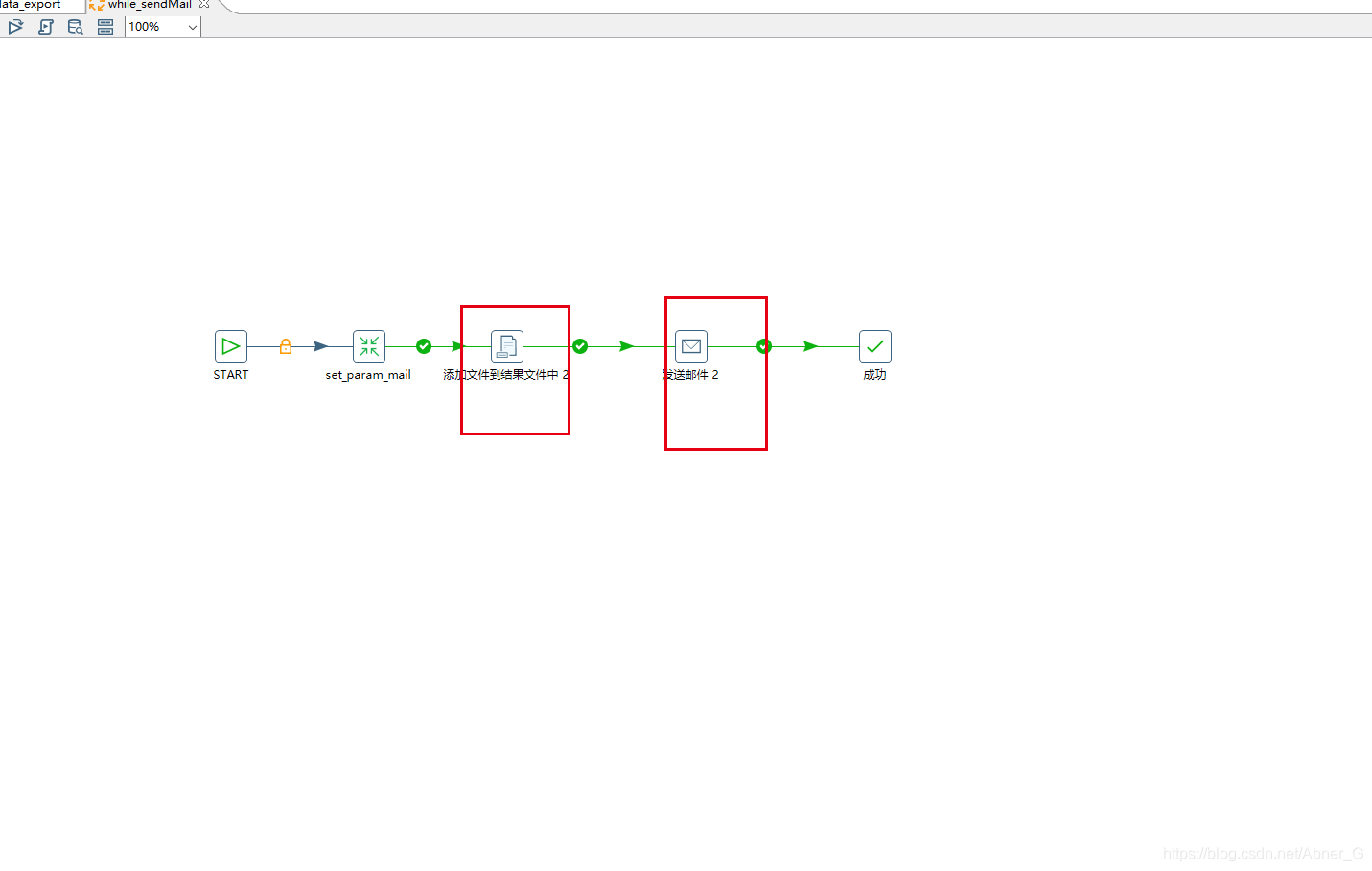
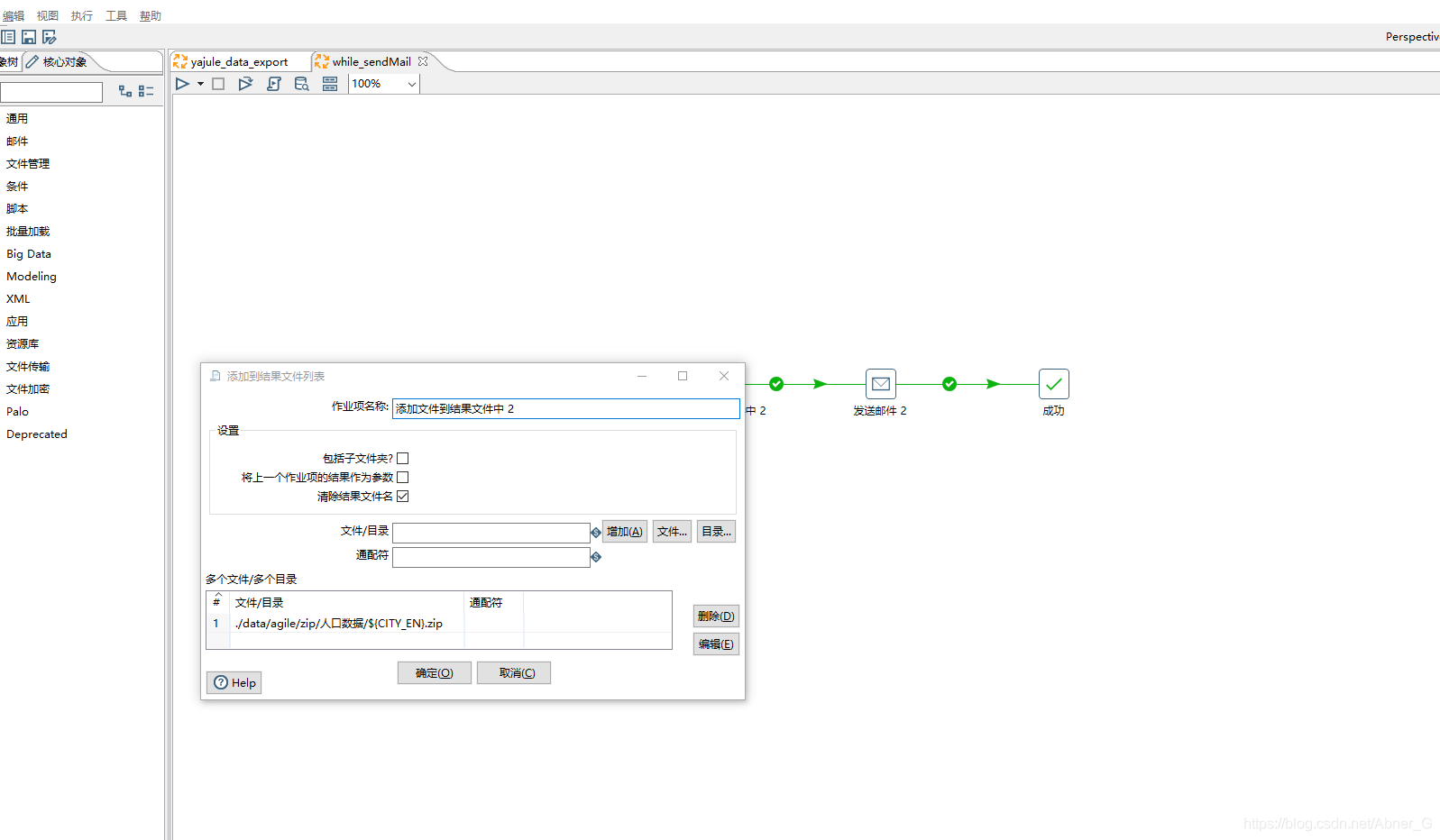
发送邮件,要配合【添加文件到结果文件中】使用
资源
Kettle 压缩包,数据库驱动jar,坐标转换工具类jar,java代码
Kettle 数据抽取【Version 6.1】-- 20211029更新
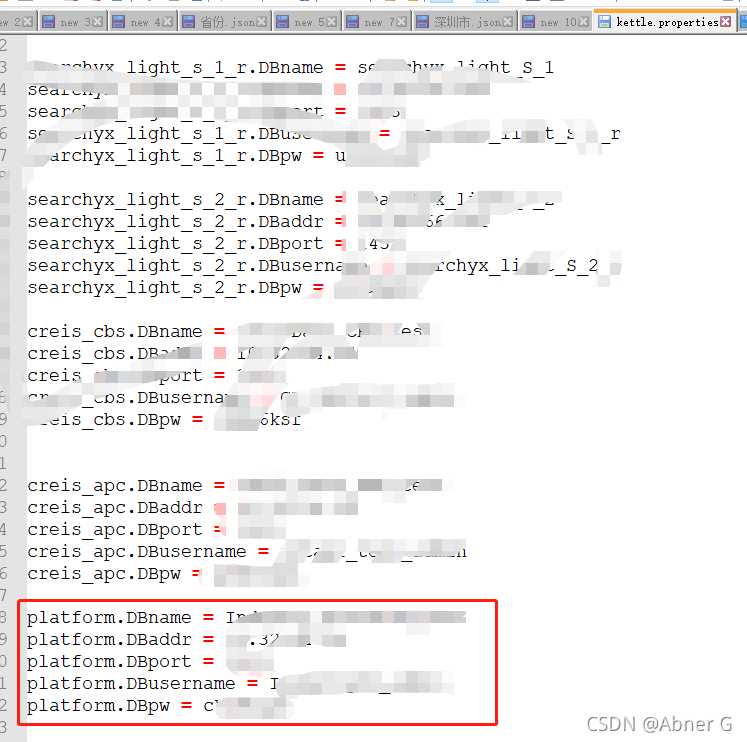
新增连接串
- 配置文件新增
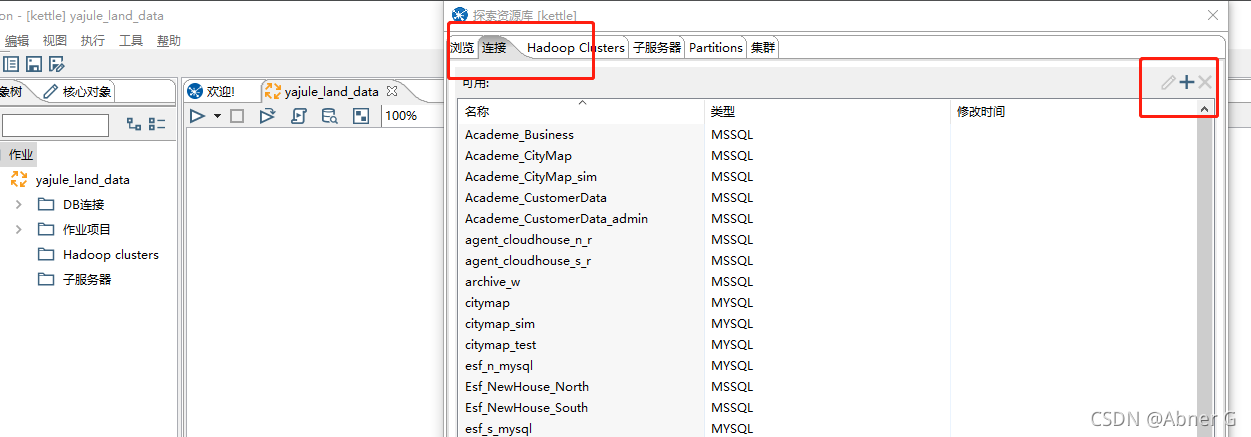
- 去资源库新增连接
判断表是否存在,分流
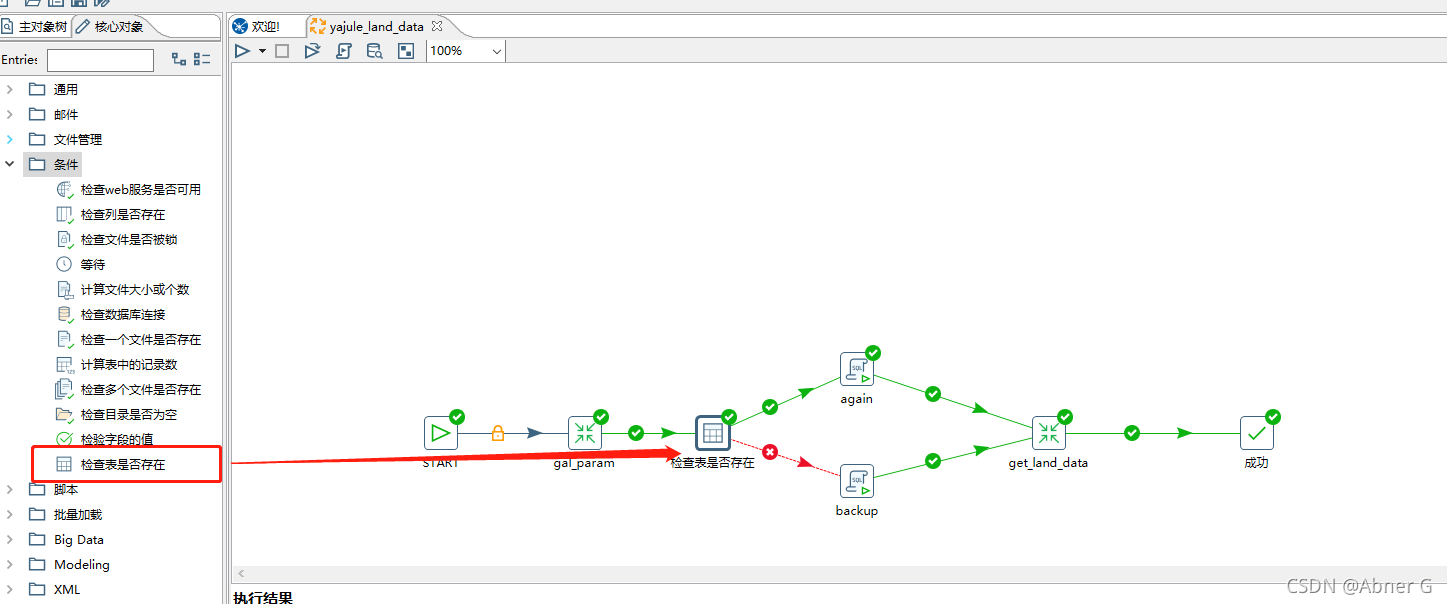
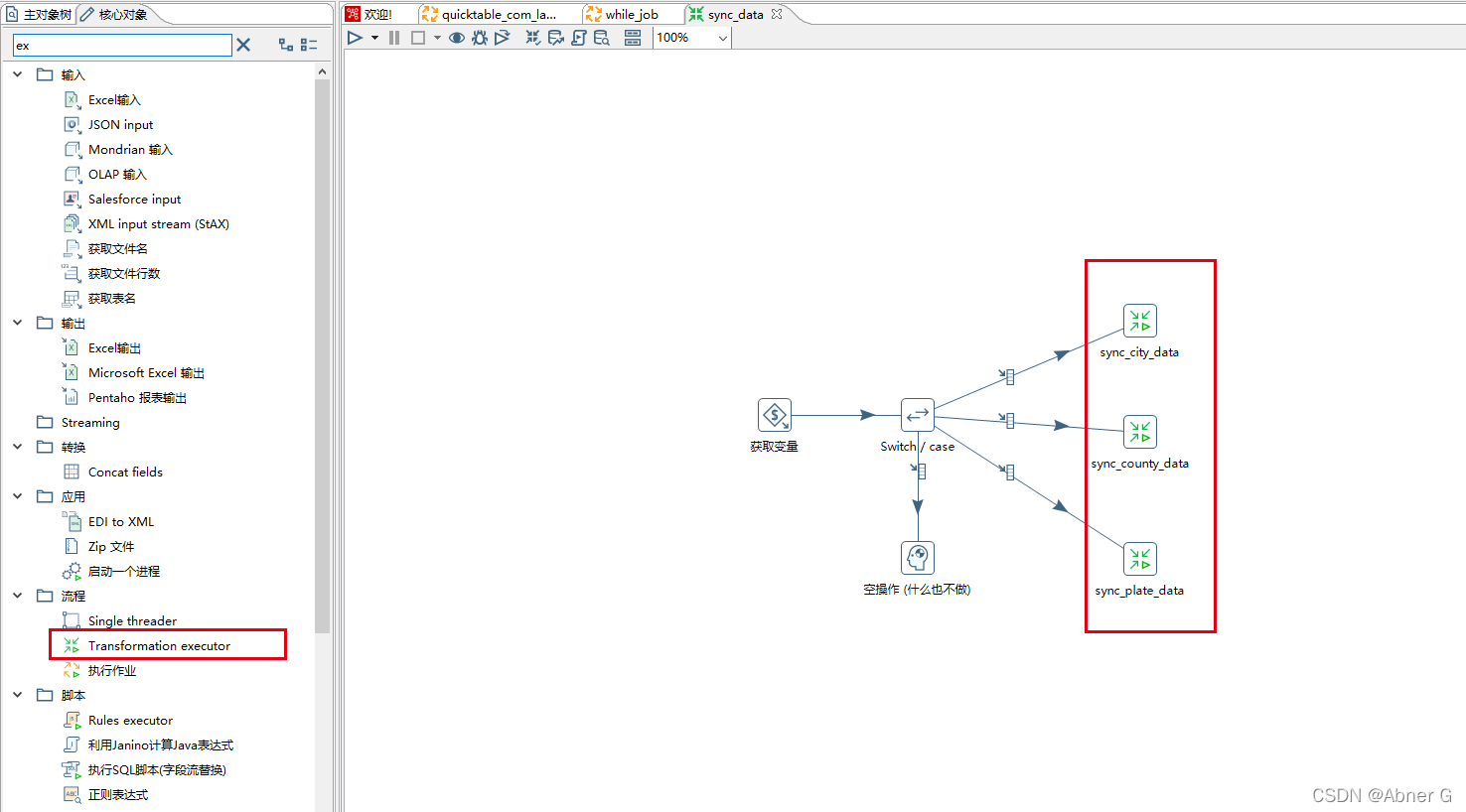
Switch/case 存在BUG
直接使用 Switch/case 不好使
需要配合【transformation executor】组件,具体执行放在转换里。
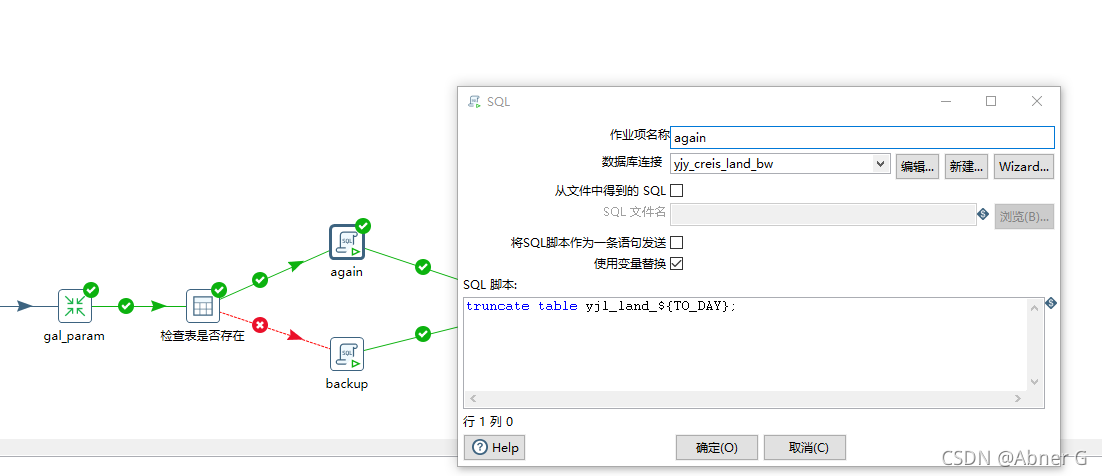
SQL脚本
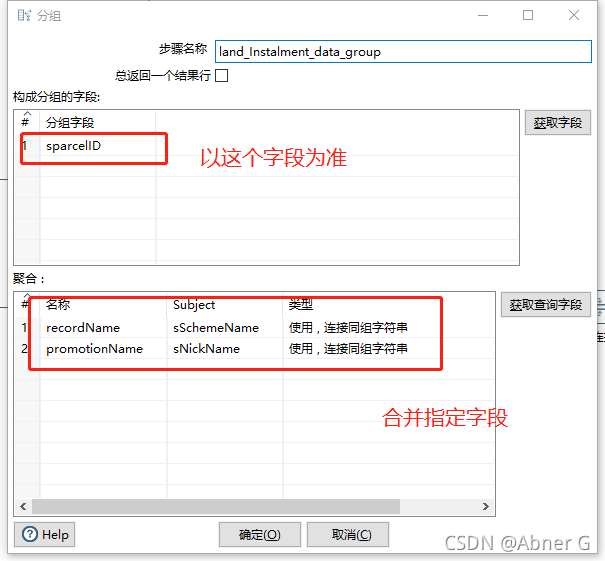
按字段合并多行数据,不同字段按逗号分隔
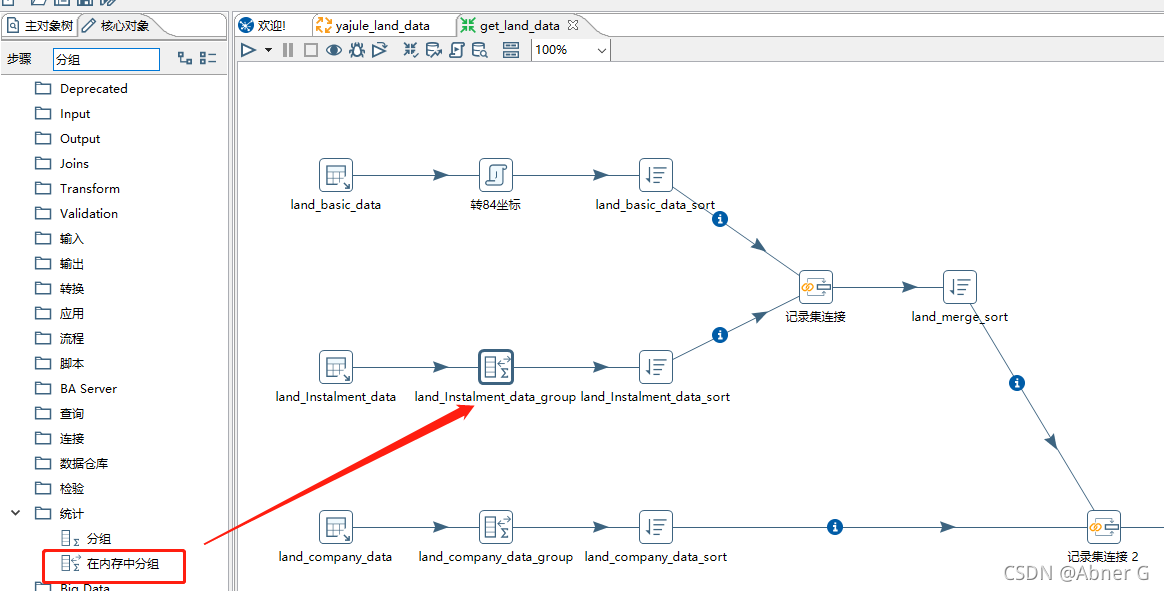
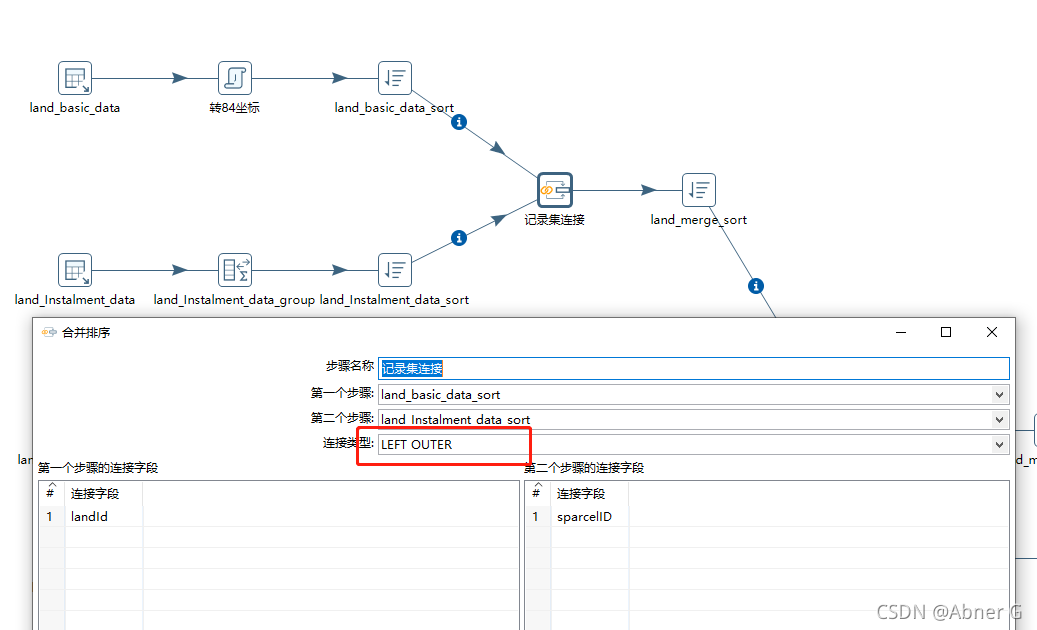
关联字段合并(类似SQL join操作)
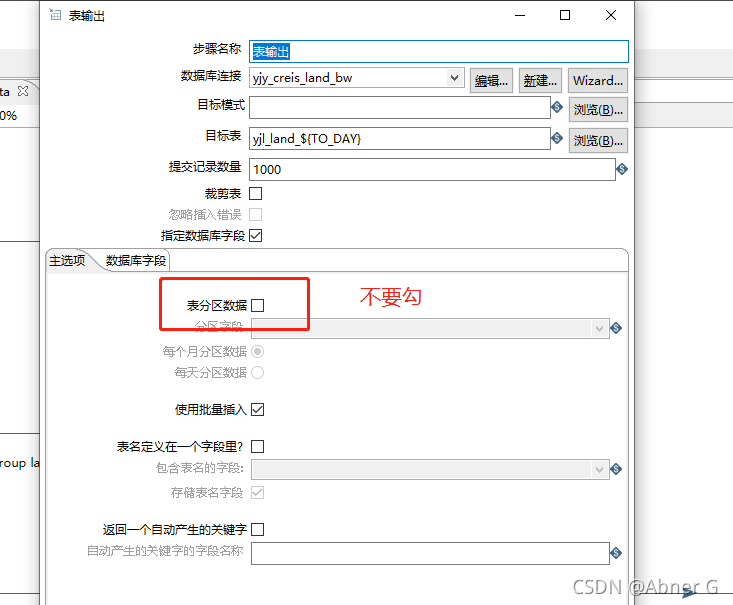
表输出
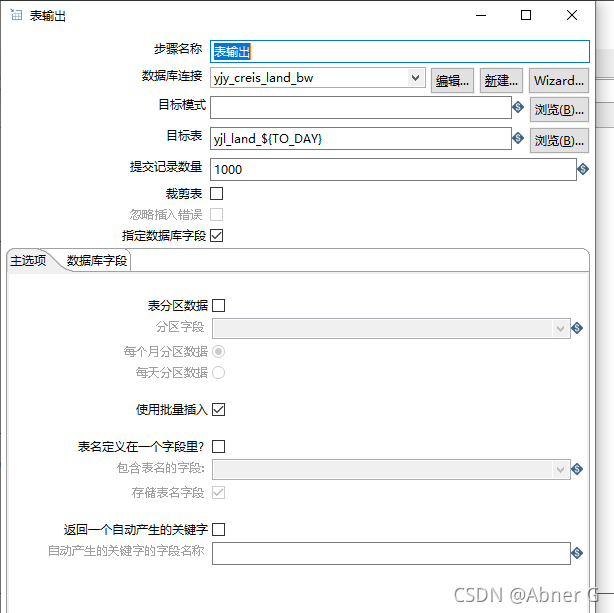
报错 “kettle:The tablename is not defined (empty)”
去掉表输出中的“表分区数据”
















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











