







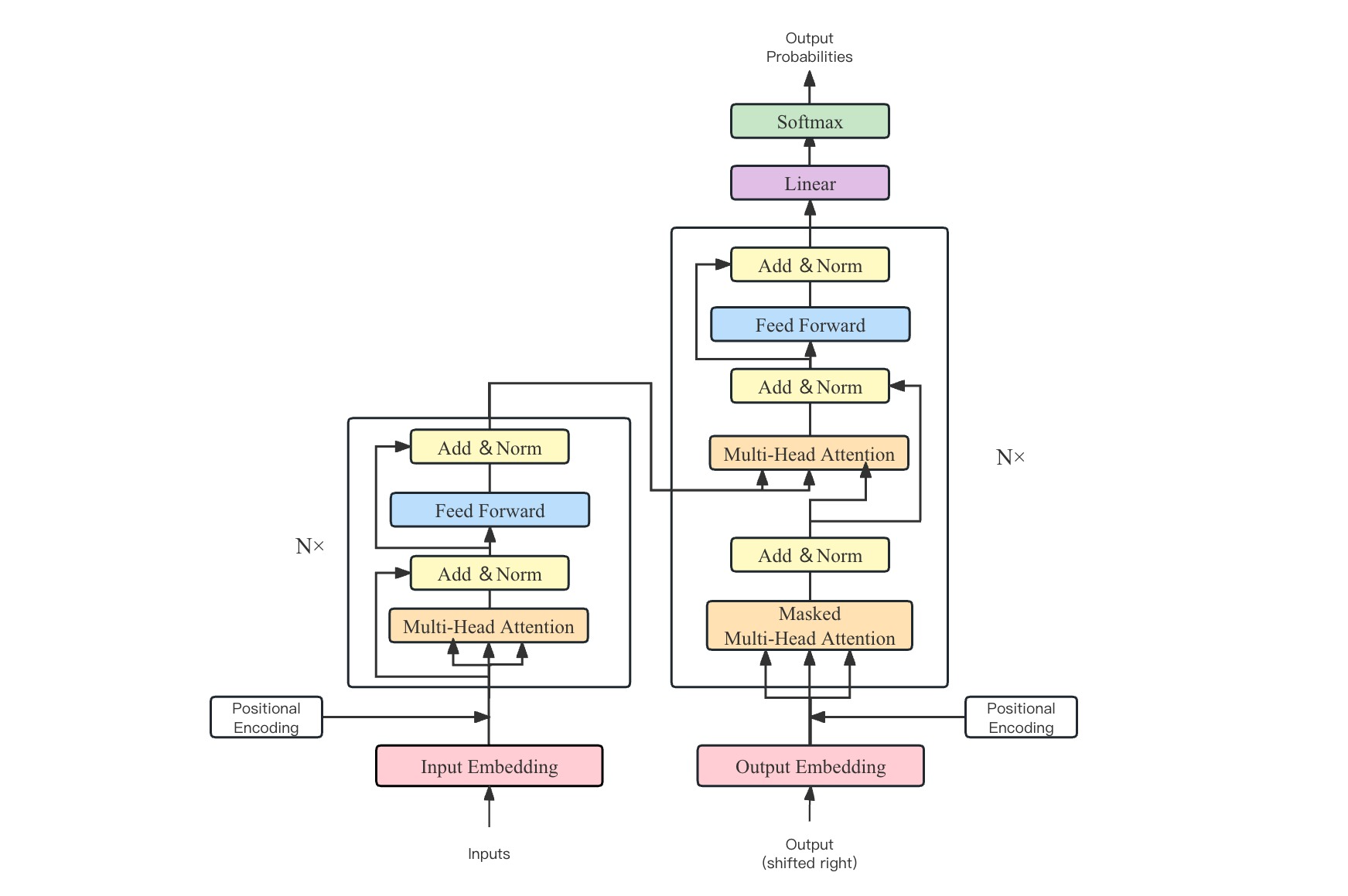
用大白话解释Transformer:编码与解码的奇幻之旅
Attention Is All You Need 英文版
Transformer论文逐段精读
深入浅出解释Transformer原理
从Word Embedding到BERT
概念
- Self Attention
权重:transformer在处理每个词的时候,不仅会注意这个词本身,以及它附近的词,还会去注意输入序列里所有其他的词。然后给予每个词不一样的注意力权重。 - 位置编码:为了让Transformer能识别输入数据的位置关系,就引入了“位置编码”。也就是给每个输入数据按照它们在序列中的位置打上一个标签,这个标签就是位置编码。位置编码的具体实现方法有很多种,最常用的就是利用弦波函数(sine和cosine)来为每个位置生成一个唯一的编码。
- 查询向量,值向量,key向量 :查询向量(Query Vector):用于向模型表示我们在寻找什么类型的信息。键向量(Key Vector):与查询向量配对的键值,用于被模型用来寻找到对应的信息。值向量(Value Vector):一旦找到了对应的键,值向量就会被返回出来。【假设你去图书馆寻找一本关于烘焙的书,但这个大图书馆没有任何标签或者分类指示。那么在这个情景下:“我想找一本烘焙书” 这个请求就像是查询向量,也就是你当前的需求或者问题。图书馆里的每一本书都可以看作是一个键向量。这本书可能是烘焙相关的,也可能是关于其他主题的,和你的需求相关性不同。每本书的内容就是其对应的值向量。一旦找到了和你的查询向量(你的需求)匹配的键向量(合适的书),你就可以获取它的值向量(阅读书中的内容)。】
过程拆解
Input Embedding (向量嵌入)
把有序的输入数据转化为计算机能认识的数据形式。
总揽
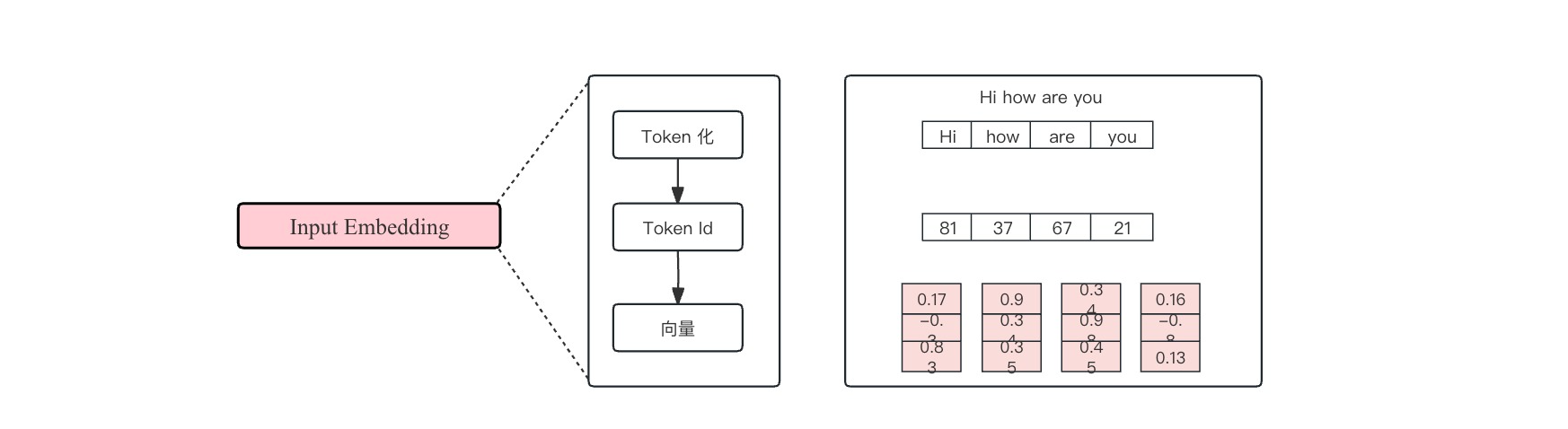
Token 化
把输入拆分成各个token。Token可以被理解为是文本的一个基本单位,取决于不同的token划分方法。短单词可能每个词是一个token,长单词可能被拆成多个token。
将例子中的hi how are you 处理为一个一个token。

Token Id
因为计算机内部无法储存文字,需要将每个token用一个整数数字表示,这个数字被叫做token ID。

向量化
将上一步转化的token ID 传入嵌入层转化为向量。

Positional Encoding (位置编码)
因为输入是有序的,为了更好的理解输入的数据,把这种顺序的信息也加到数据上。
总览
模型既知道每个词的意义,又能知道词在句子中的位置。(区别于RNN)
使用正余弦函数表示绝对位置,通过两者乘积得到相对位置
最常用的就是利用弦波函数(sine和cosine)来为每个位置生成一个唯一的编码。
s i n ( α + β ) = s i n a c o s β + c o s α s i n β sin(α+β)=sinacosβ+cosαsinβ sin(α+β)=s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











