






赛题:零基础入门数据挖掘 - 二手车交易价格预测
地址:[链接](https://tianchi.aliyun.com/competition/entrance/231784/introduction? spm=5176.12281957.1004.1.38b02448ausjSX)
赛题理解
- 赛题概况
比赛要求参赛选手根据给定的数据集,建立模型,二手汽车的交易价格。
来自 Ebay Kleinanzeigen 报废的二手车,数量超过 370,000,包含 20 列变量信息,为了保证 比赛的公平性,将 会从中抽取 10 万条作为训练集,5 万条作为测试集 A,5 万条作为测试集 B。同时会对名称、车辆类型、变速 箱、model、燃油类型、品牌、公里数、价格等信息进行脱敏。 - 赛题数据
SaleID
交易ID,唯一编码
name
汽车交易名称,已脱敏
regDate
汽车注册日期,例如20160101,2016年01月01日
model
车型编码,已脱敏
brand
汽车品牌,已脱敏
bodyType
车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7
fuelType
燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6
gearbox
变速箱:手动:0,自动:1
power
发动机功率:范围 [ 0, 600 ]
kilometer
汽车已行驶公里,单位万km
notRepairedDamage
汽车有尚未修复的损坏:是:0,否:1
regionCode
地区编码,已脱敏
seller
销售方:个体:0,非个体:1
offerType
报价类型:提供:0,请求:1
creatDate
汽车上线时间,即开始售卖时间
price
二手车交易价格(预测目标)
v系列特征
匿名特征,包含v0-14在内15个匿名特征 - 评测标准
MAE:均方误差
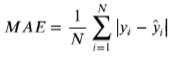
数据分析
载入训练和测试数据并对其进行分析,可分为以下部分
- 数据总览
使用shape(),head(),describe(),info()等函数对其进行整体分析,包括查看数据维度,每列数据的缺失值和类型,和标准差,平均值等统计信息。 - 判断数据缺失
使用isnull()和sum并进行绘图可以初步判断出缺失值数量,之后可使用missingno库的matrix可视化缺失值的分布。这里要注意的一点是缺失值并不一定是Nan,比如notRepairedDamage中使用了‘-’表示了缺失,使用replace用Nan对其进行替换。
另外对于数据分布严重倾斜的列进行删除,如seler和offertype - 查看预测值的分布
使用seaborn了解预测值的总体分布情况,使用kurt()和skew()查看其峰度和偏度,之后对其进行频数统计。本次实验价格符合无界约翰逊分布。 - 特征分类判别
将特征分为类别特征和数字特征,可以通过数据类型是num或者obj来判别。但是本次中数据已经进行了处理,需要通过先验知识对其进行分类,之后分别进行处理。
对于类别特征
- 使用unique()查看其是否为稀疏特征,删除对结果无意义的稀疏特征
- 箱型图可视化 查看异常值,对不同数据分布进行对比
- 小提琴图可视化 箱型图升级版,可以看出数据集中区域
对于数字特征 - 相关性分析corr()后构造热力图sns.heatmap()查看各个特征和预测值的相关性和特征之间的相关性
- 使用pd.melt()整合数据后使用sns.FacetGrid()对单个特征的分布可视化
- sns.pairplot()对数字特征之间相互关系可视化,可以观察到明显的离散值
- 多变量互相回归关系可视化
- 用pandas_profiling生成数据报告
非常好用的一个功能,基本包含了上面所有的分析,缺点就是生成时间有些长,超到3.7的1400用了大概50分钟















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









