






安科瑞戴婷 Acrel-Fanny
今年的snec上海光伏展吸引了来自全球各地的光伏行业专业人士及爱好者,本次展会共有来自30多个国家和地区的超过2000家企业参展,展出的光伏产品涵盖了太阳能电池、太阳能组件、逆变器、太阳能辅助设备等众多领域。
随着近年来光伏技术的不断进步,太阳能发电成本逐渐下降,太阳能发电已经成为可再生能源中具有发展潜力的领域之一。
根据CNESA,截至2023年底,中国投运储能项目累计装机规模达86.5GW,其中新型储能装机规模达34.5GW/74.5GWh,在2023年新增装机规模达21.5GW/46.6GWh,为2022年的三倍左右,锂电池技术占比提升至97.3%。理想情景下预计2024-2027年新型储能累计装机规模分别为54.7/80.4/108.9/138.4GW。
并网规模:预计2024年新增并网规模有望提升至85-107GWh,新疆将持续储能市场。
央国企优势明显。从并网规模超1GWh的开发商来看,国家电投项目遍布22个省份,总规模达3.76亿元,显示出行业高度集中性;从供货排名前十名设备制造厂商来看,占据全年新增并网规模的57%,前20名企业占据73%。
可见,虽然中国有175家储能企业,但市场主要由前20名企业。

此次展会,不仅看到了诸多耳熟能详的储能行业公司,也对光伏储能这一块更加了解。储能市场现在更新换代很快,但是相对的也有很多痛点
1.设备维度:要考虑系统安全、设备效能、成本优化及寿命提升;
2.场站维度:综合考虑空间布局、惹到效应、环境适应性和运维管理;
3.电网维度:需要提供设计良好、电网适应性强的储能系统
我司针对于储能市场的痛点,也出了适配于电网的源网荷储充一体化的储能方案。
Acrel-2000MG微电网能量管理系统是安科瑞电气股份有限公司根据新型电力系统下微电网监控系统与微电网能量管理系统的要求,总结国内外的研究和生产的先进经验并结合自身20多年来的技术积累,基于新能源预测、全景监控、优化控制、多能互补、源荷互动、智能运维,专门研制出的新一代企业微电网能量管理系统,打造一个新能源全景全生命周期解决方案。包括新能源全景监控系统、基于Al的新能源预测算法、新能源综合管理终端、储能系统、多能互补的综合能源管理系统、需求侧响应等,为以新能源为主体的新型电力系统,提供包括产品、集成、管理、增值服务等全流程一揽子解决方案。
本系统可以对光伏系统、风力发电、储能系统以及充电桩等24小时进行数据采集分析,监视微电网内各设备运行状态及健康状况,是一套集监视控制、能量管理为一体的管理系统。该系统在安全稳定的基础上以经济优化运行为目标,促进可再生能源应用,提高电网运行稳定性、补偿负荷波动。有效实现用户侧的需求管理、消除昼夜峰谷差、平滑负荷,提高电力设备运行效率、降低用电成本。为企业微电网能量管理提供安全、可靠、经济运行提供全新的解决方案。

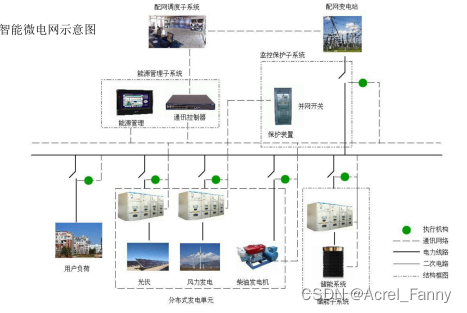
微电网系统:
由分布式电源、储能装置、能量转换装置、相关负荷和监控、保护装置汇集而成的小型发配电系统,是一个能够实现自我控制、保护和管理的自治系统。
分类:
并网型:既可以与外部电网连接运行,也支持离网独立运行,以并网为主。
离网型:不与外部电网联网,实现电能自发自用,功率平衡微电网。
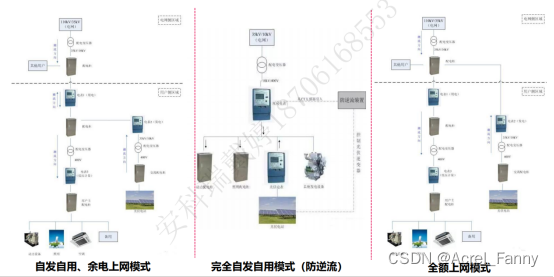
Acrel-2000MG微电网能量管理系统能够对微电网的源、网、荷、储能系统、充电负荷进行实时监控、诊断告警、全景分析、有序管理和准确控制,满足微电网运行监视、安全分析智能化、调整控制前瞻化、全景分析动态化的需求,完成不同目标下光储充资源之间的灵活互动与经济优化运行,实现能源效益、经济效益和环境效益。
主要功能:实时监测;能耗分析;智能预测;协调控制;经济调度;需求响应。
系统特点:平滑功率输出,提升绿电使用率;
削峰填谷、谷电利用,提高经济性;
降低充电设备对局部电网的冲击;
降低站内配电变压器容量;
实现源荷高匹配效能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









