







算法简介
PageRank(网页排名),用于衡量网页的重要程度的Google专有算法。最早的搜索引擎采用的是分类目录的方法,即通过人工进行网页分类并整理出高质量的网站。后来网页越来越多,人工分类已经不现实了。搜索引擎进入了文本检索的时代,即计算用户查询关键词与网页内容的相关程度来返回搜索结果。这种方法突破了数量的限制,但是搜索结果不是很好。因为总有某些网页来回地倒腾某些关键词使自己的搜索排名靠前。
谷歌的两位创始人,当时还是美国斯坦福大学研究生的佩(Larry Page)和布林(Sergey Brin)开始了对网页排序问题的研究。他们借鉴了学术界评判学术论文重要性的通用方法, 那就是看论文的引用次数。由此想到网页的重要性也可以根据这种方法来评价,于是PageRank的核心思想就诞生了。
核心思想
一、如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高。
二、如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。
算法原理
一、给每个网页一个初始PageRank值。
二、通过(投票)算法不断迭代,直至达到平稳分布为止。
PR值物理意义上为一个网页被访问的概率,所以PR初始值可以假设为 1/N ,其中N为网页总数。一般情况下,所有网页的PR值的总和为1。(如果不为1的话也不是不行,最后算出来的不同网页之间PR值的大小关系仍然是正确的,只是不能直接地反映概率)。
网页PR值计算公式为:
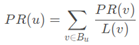
例子
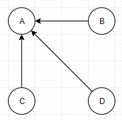
假设一个由只有4个页面组成的集合:A,B,C和D。如果所有页面都链向A,那么A的PR值将是B,C及D的和。
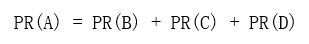
假设B也有链接到C,并且D也有链接到包括A的3个页面。一个页面不能投票2次。所以B给每个页面半票。以同样的逻辑,D投出的票只有三分之一算到了A的PR上。
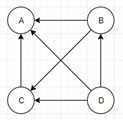
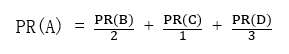
换句话说,根据链出总数平分一个页面的PR值。
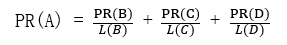
根据多次迭代后,PR值逐渐收敛稳定。
特殊情况
1、排名泄露:如果存在网页没有出度链接,经过多次迭代,所有网页的PR值都会趋于0,产生排名泄露问题。
2、排名下沉:如果存在网页没有入度链接,经过多次迭代,该网页的PR值将趋于0,产生排名下沉问题。
3、排名上升:如果一个网页只有对自己的出链,或者几个网页的出链形成一个循环圈。那么在多次迭代过程后,这一个或几个网页的PR值将只增不减。
例子
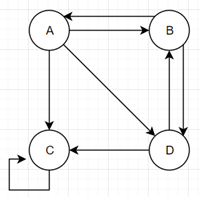
为了解决这个问题,我们假设一个随机浏览网页的人,当他到达C网页后,假定他有一个确定的概率(1–a)会输入网址直接跳转到一个随机的网页,并且跳转到每个网页的概率是一样的。
于是此图中C的PR值可表示为:
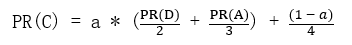
在一般情况下,一个网页的PR值计算如下:
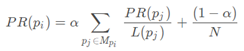
其中Mpi是所有对Pi网页有出链的网页集合,L(Pj)是网页Pj的出链数目,N是网页总数,a一般取0.85。根据上面的公式,我们可以计算每个网页的PR值,在不断迭代趋于平稳的时候,即为最终结果。
算法分析
PageRank算法优点
1、PageRank是一个与查询无关的静态算法,所有网页的PageRank值通过离线计算获得,有效减少在线查询时的计算量,极大降低了查询响应时间。
PageRank算法缺点
1、人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题性降低。例如,当搜索“苹果”时,一个数码爱好者可能是想要看 iphone 的信息,一个果农可能是想看苹果的价格走势和种植技巧,而一个小朋友可能在找苹果的简笔画。理想情况下,应该为每个用户维护一套专用向量,但面对海量用户这种方法显然不可行。所以搜索引擎一般会选择一种称为主题敏感PageRank(Topic-Sensitive PageRank)的折中方案。主题敏感PageRank的做法是预定义几个话题类别,例如体育、娱乐、科技等等,为每个话题单独维护一个向量,然后想办法关联用户的话题倾向,根据用户的话题倾向排序结果。
2、没有区分站内导航链接。很多网站的首页都有很多对站内其他页面的链接,称为站内导航链接。这些链接与不同网站之间的链接相比,肯定是后者更能体现PageRank值的传递关系。
3、没有过滤广告链接和功能链接。这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
4、对新网页不友好。一个新网页的一般入链相对较少,即使它的内容的质量很高,要成为一个高PR值的页面仍需要很长时间的推广。
算法改进
针对PageRank算法的缺点,提出了TrustRank算法,用来检测垃圾网站。
TrustRank算法工作原理:先人工去识别高质量的页面(“种子”页面),那么由“种子”页面指向的页面也可能是高质量页面,即其TR值也高,与“种子”页面的链接越远,页面的TR值越低。“种子”页面可选出链数较多的网页,也可选PR值较高的网站。
TrustRank算法给出每个网页的TR值。将PR值与TR值结合起来,可以更准确地判断网页的重要性。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









