







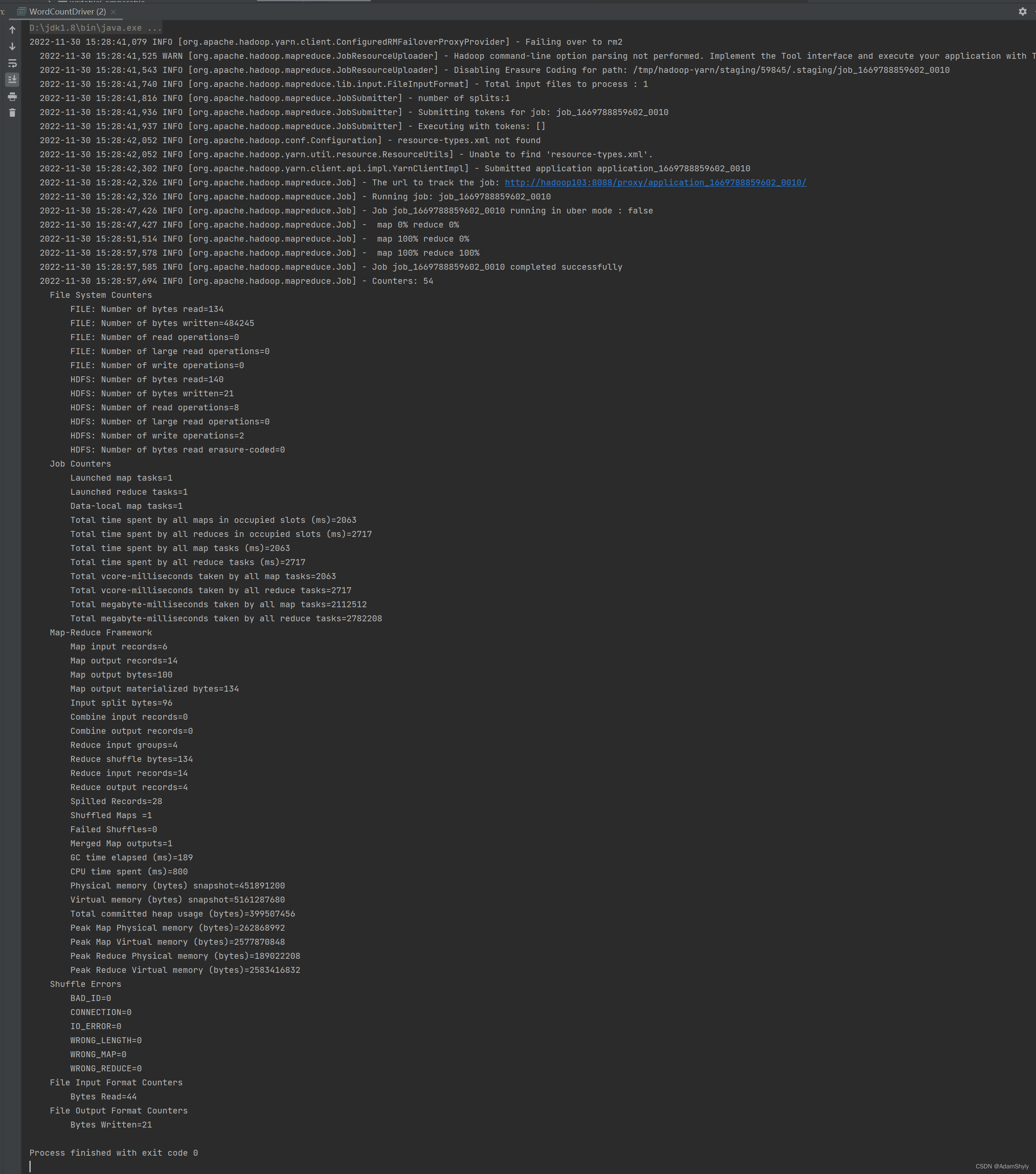
本文通过IDEA本地执行MR程序的main函数 ,而不是打包成Jar手工放到服务器上运行,发现以下错误提示:No job jar file set,然后在HDFS的/tmp下也没发现有该项目的Jar包,可以推测是任务提交给yarn后,本地并没有将项目打包成Jar提交给ResourceManager,导致找不到Mapper与Reducer类。
所以总体思路就是将项目借助Maven打包成Jar,然后通过添加mapreduce.job.jar的xml配置指定该Jar包在本地的存储路径。注意不能是绝对路径,必须是相对路径(项目文件为根路径),否则还是无法提交成功,但是No job jar file set的提示消失了,却依旧找不到类。
package com.atguigu.mapreduce.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
context.write(key, outV);
}
}
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1.获取一行
String line = value.toString();
// 2.切割
String[] words = line.split(" ");
for (String word : words) {
// 封装outK
outK.set(word);
//写出
context.write(outK, outV);
}
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1 获取job
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.job.jar","test.jar");
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class );
// 6 设置输入路径和输出路径
// FileInputFormat.setInputPaths(job, new Path("D:\\BaiduNetdiskDownload\\11_input\\inputword"));
// FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\output\\output1"));
FileInputFormat.setInputPaths(job, new Path("/input/word.txt"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
点击package按钮进行打包
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









