









 本文详细介绍了如何在虚拟机环境中使用Kafka3.0.0版本,配合ZooKeeper搭建一个高可用的分布式Kafka集群,包括解压、配置、环境变量设置以及启动/停止集群的步骤。
本文详细介绍了如何在虚拟机环境中使用Kafka3.0.0版本,配合ZooKeeper搭建一个高可用的分布式Kafka集群,包括解压、配置、环境变量设置以及启动/停止集群的步骤。
下载Kafka压缩包
下方是Kafka官网下载地址,本文使用Kafka 3.0.0在虚拟机环境中搭建分布式集群。
Apache Kafka Downloads link
虽然在Kafka 2.8.0之后可以使用KRaft模式搭建高可用的集群以提高数据处理效率,但是目前还有许多企业依然使用ZooKeeper搭建Kafka集群,所以本文也采用ZooKeeper组件来搭建Kafka分布式集群。

基于ZooKeeper的Kafka高可用集群
本文使用三台CentOS7虚拟机分别搭建三个broker节点的Kafka集群。以broker ID为0的节点为例,下方是该节点配置Kafka的具体步骤,另外两个broker节点的配置步骤与其一致。
- 解压
kafka_2.12-3.0.0.tgz压缩包
tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
- 重命名文件夹名称(可选),注意后面的配置文件也需要根据该名称进行修改。
cd /opt/module
mv kafka_2.12-3.0.0 kafka
- 修改
/opt/module/kafka/config/server.properties配置文件中最基础的参数配置:第一个是broker节点ID,第二个是topic数据存储路径。
vim server.properties
broker.id=0
log.dirs=/opt/module/kafka/datas
- 修改环境变量。
sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
- 使用
source命令刷新环境变量。
source /etc/profile
启动Kafka集群
- 启动ZooKeeper。在先前的博客中已介绍过ZooKeeper组件集群的搭建配置方式,并自定义了ZooKeepr集群启动脚本。所以本文直接使用该集群启动脚本
zk.sh启动ZooKeeper。其中hadoop102 103 104为三个broker节点的域名。
[hadoop@hadoop102 bin]$ cat zk
#!/bin/bash
case $1 in
"start"){
for host in hadoop102 hadoop103 hadoop104
do
echo ------------ zookeeper $host 启动 ---------------
ssh $host "/opt/module/zookeeper-3.5.9/bin/zkServer.sh start"
done
}
;;
"stop"){
for host in hadoop102 hadoop103 hadoop104
do
echo ------------ zookeeper $host 停止 ---------------
ssh $host "/opt/module/zookeeper-3.5.9/bin/zkServer.sh stop"
done
}
;;
"status"){
for host in hadoop102 hadoop103 hadoop104
do
echo ------------ zookeeper $host 状态 ---------------
ssh $host "/opt/module/zookeeper-3.5.9/bin/zkServer.sh status"
done
}
;;
*) echo Not exist the instruction
;;
esac
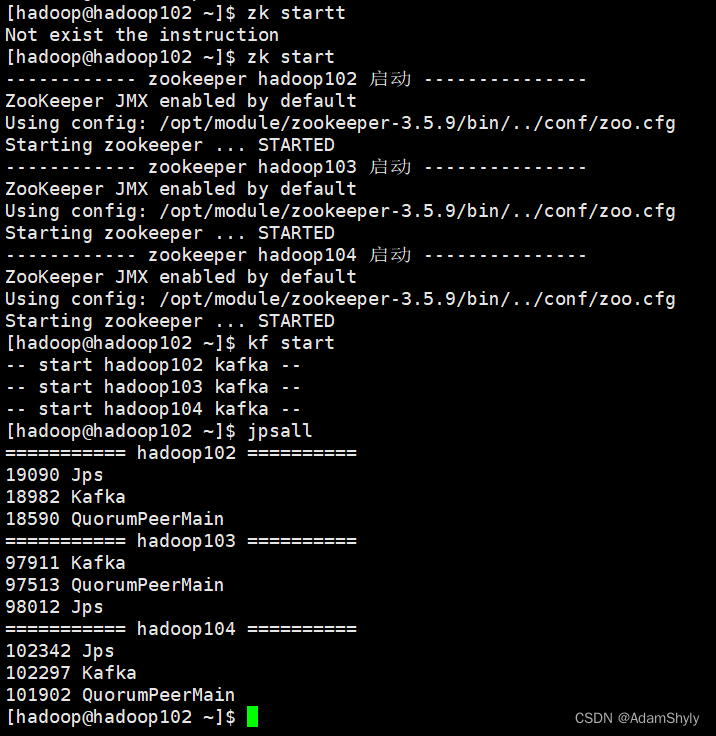
[hadoop@hadoop102 bin]$ ./zk start
- 启动Kafka集群。本文也针对Kafka集群定义了集群启动与停止Shell脚本,所以直接使用该脚本
kf.sh启动Kafka集群即可。注意:必须先启动ZooKeeper再启动Kafka集群;在停止集群运行的时候,需要先停止Kafka集群,再停止ZooKeeper服务。
[hadoop@hadoop102 bin]$ cat kf
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo "-- start $i kafka --"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo "-- stop $i kafka --"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"
done
;;
esac
[hadoop@hadoop102 bin]$ ./kf start















 1173
1173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









