









算法基本思路:首先需要确定一个因变量y以此构建一元回归方程,再找到已通过显著性检验的一元线性回归方程中F值最大的解释变量x0,将其并入回归方程中,再分别将剩余的解释变量与解释变量x0作为OLS函数的自变量集拟合回归方程,同样找出其中F值最大的自变量集,如果该自变量集均能通过显著性检验则将该解释变量并入回归方程中并进行下一轮的迭代,否则舍弃该解释变量,并找出F值第二大的自变量集继续对其进行显著性检验。
import pandas as pd
import numpy as np
import statsmodels.api as sm
def test_significance(data, dv, src_idvs):
model = sm.OLS(data.loc[:, dv], data.loc[:, src_idvs]).fit()
for p in model.pvalues:
if p > 0.05:
return False
else:
return True
def find_max_F(data, dv, idvs, res_idvs):
F_max = -1
idv_F_max = None
res_model = None
for idv in idvs:
new_idvs = res_idvs.copy()
new_idvs.append(idv) # 加入新解释变量找出F最大值
model = sm.OLS(data.loc[:, dv], sm.add_constant(
data.loc[:, new_idvs])).fit()
F = model.fvalue
if F > F_max:
F_max = F
idv_F_max = idv
res_model = model
return F_max, idv_F_max, res_model
def stepwise_regression(data, dv, idvs=None): # 向前向后逐步回归
res_idvs = []
src_idvs = idvs.copy()
res_models = []
for step in range(len(idvs)):
isExit = False
while True:
F, idv, model = find_max_F(
data, dv, src_idvs, res_idvs) # 求出F最大值以及对应的解释变量
if model == None: # 多元线性拟合失败
print("第{0}步拟合线性失败".format(step + 1))
isExit = True
break
res_idvs.append(idv)
# 没有新解释变量并入回归方程中
if model.f_pvalue >= 0.05 or not test_significance(data, dv, res_idvs):
res_idvs.pop() # 移除该解释变量
src_idvs.remove(idv)
print("第{0}步移除解释变量{1}".format(step + 1, idv))
if len(src_idvs) == 0: # 该轮for循环并没有解释变量能够并入回归方程中
isExit = True
break
else: # 找到新解释变量,结束While循环
print("第{0}步并入解释变量{1}".format(step + 1, idv))
res_models.append(model)
break
if isExit: # 提前结束逐步回归
break
else:
src_idvs = []
for idv in idvs:
if idv not in res_idvs:
src_idvs.append(idv)
return res_idvs, res_models
data = pd.read_excel('./normalization.xlsx')
equations = []
stdouts = []
for column in data.columns:
idvs = list(data.columns.copy())
idvs.remove(column)
res, models = stepwise_regression(data=data, dv=column, idvs=idvs)
equation = 'y = '
stdout = 'y为' + column + '、'
for index in range(len(res)):
equation += str(models[index].params[1]) + ' * x' + str(index)
stdout += 'x' + str(index) + '为' + res[index]
if index != len(res) - 1:
equation += ' + '
stdout += '、'
equations.append(equation)
stdouts.append(stdout)
with open(file='./MultivariateLinearity.txt', mode='w', encoding='utf-8') as f:
for index in range(len(equations)):
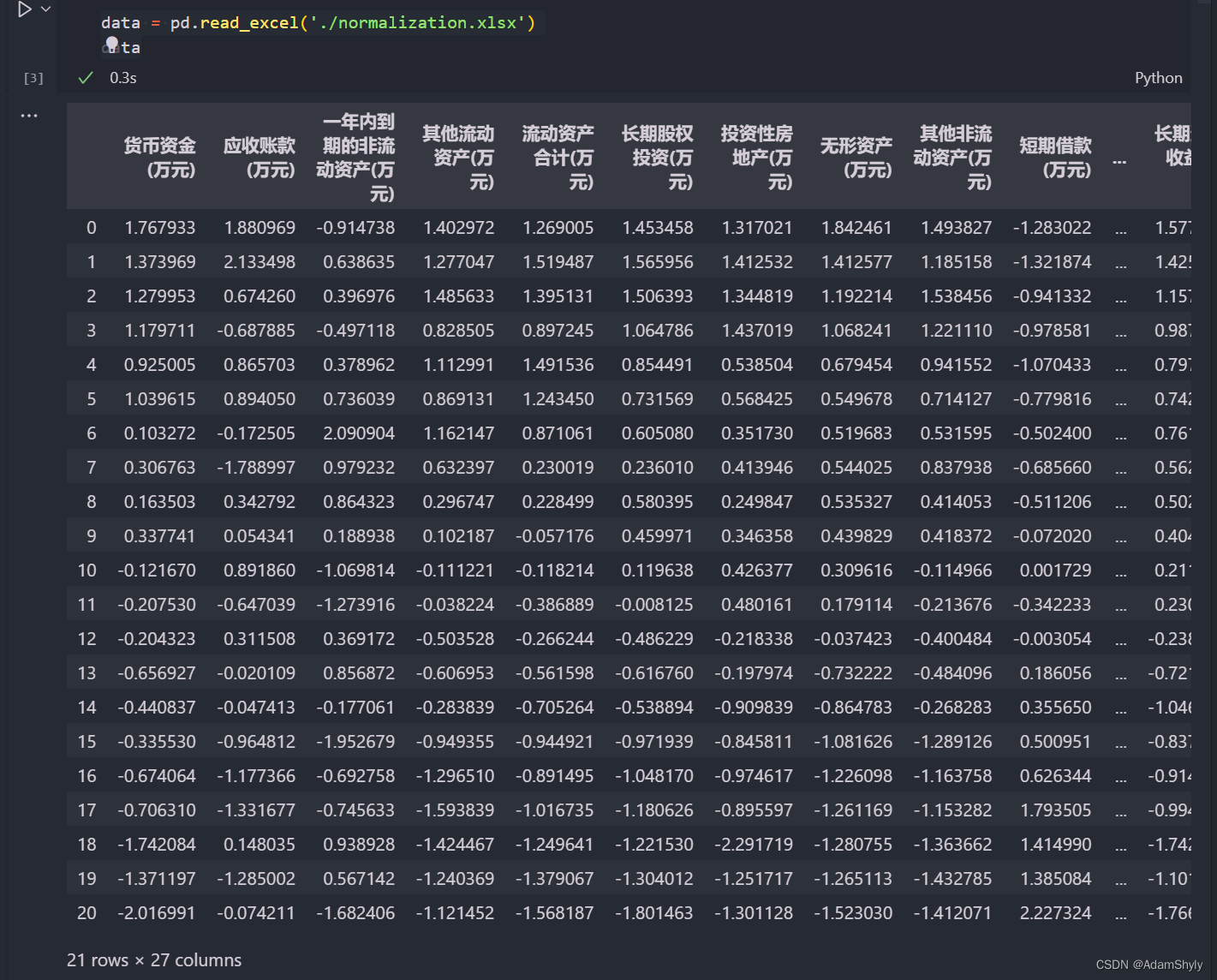
f.write(equations[index] + '\n其中: ' + stdouts[index] + '\n')以下是data数据集格式,一个解释变量为一列
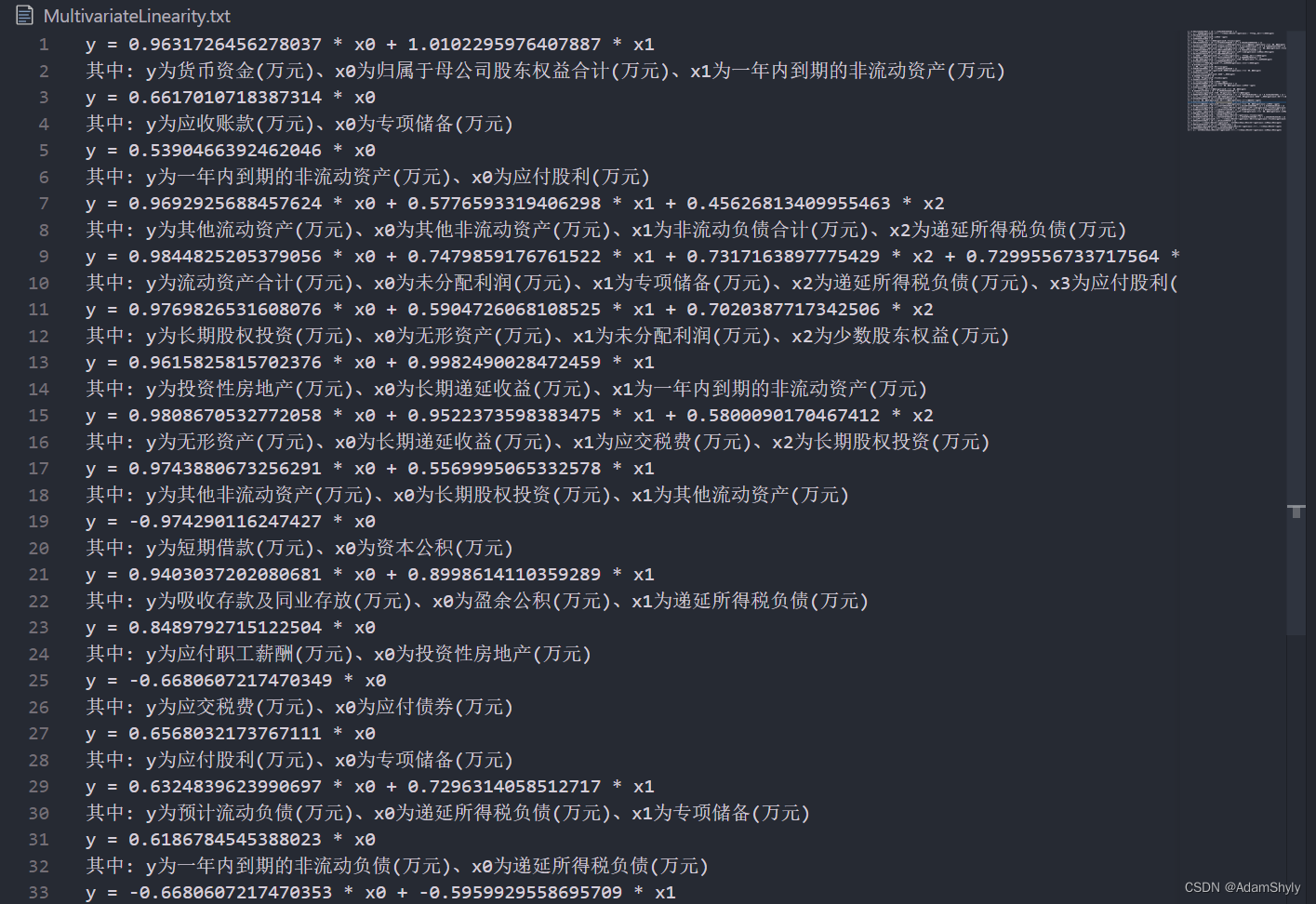
 以下是将方程以及变量解释输出至.txt文件的最终结果
以下是将方程以及变量解释输出至.txt文件的最终结果














 3212
3212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









