







向导
介绍
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/getting-started.html
cluster
Elasticsearch集群是由一个或多个节点组成,通过其集群名称来进行唯一标识。节点在搜索到集群之后,通过判断自身的 cluster.name 来决定是否加入该集群
node
节点就是单个的Elasticsearch实例。在一般情况下,每个节点都在独立的容器中运行。
文档
文档是ES搜索的最小数据单元。简单说,文档相当于关系型数据库中的行。但他有具有一些关系型数据库所没有的特点
- 文档是独立的
- 文档中还可以包含文档,可以套娃
- 文档的结构非常灵活。不同于关系型数据库,无需实现定义文档的结构,可以随用随加
索引
在ES中,索引是文档的集合,每个索引由一个或多个文档组成,并且这些文档可以分布在不同的分片之中。这类似于关系型数据库中的 database 。它只是一种逻辑命名空间,内部包含的是 1~N 个主分片,0~N 个副本
分片
一个索引可以存储海量的数据。比如一个具有10 亿文档的索引占据1 TB 的磁盘空间,而任一节点都没有这么大的磁盘空间或单个节点处理响应太慢。
为了解决这个问题,ES选择将索引划分为多分,这些划分出来的部分就叫分片(shard)。ES会自动管理这些分片的分布和排列,有了分片,我们可以随意扩展数据容量,可以在多个节点上进行并行操作,进一步提高了吞吐量
分片健康状态
分片健康状态就是分片的分配状态,可以间接指示集群当前工作状态
- 红色:至少存在一个主分片未分配
- 黄色:主分片均已分配,但至少一个副本为分配
- 绿色:everything is good
es与mysql对比
- es的index: 相当于数据库;如book索引.
- 为提高查询效率, es会对索引进行分片: 默认分为5片;
- 为防止数据丢失, 会对数据备份 ,备份不会帮助检索数据
- 索引下分为type; 对应mysql中的表; es5一个index可有多个索引, es6的版本每个index可以创建1个type, es7中type废除
- 每个type下有多个document…对应mysql中的行
- 每个document下是多个field. 对应mysql的列
rest api
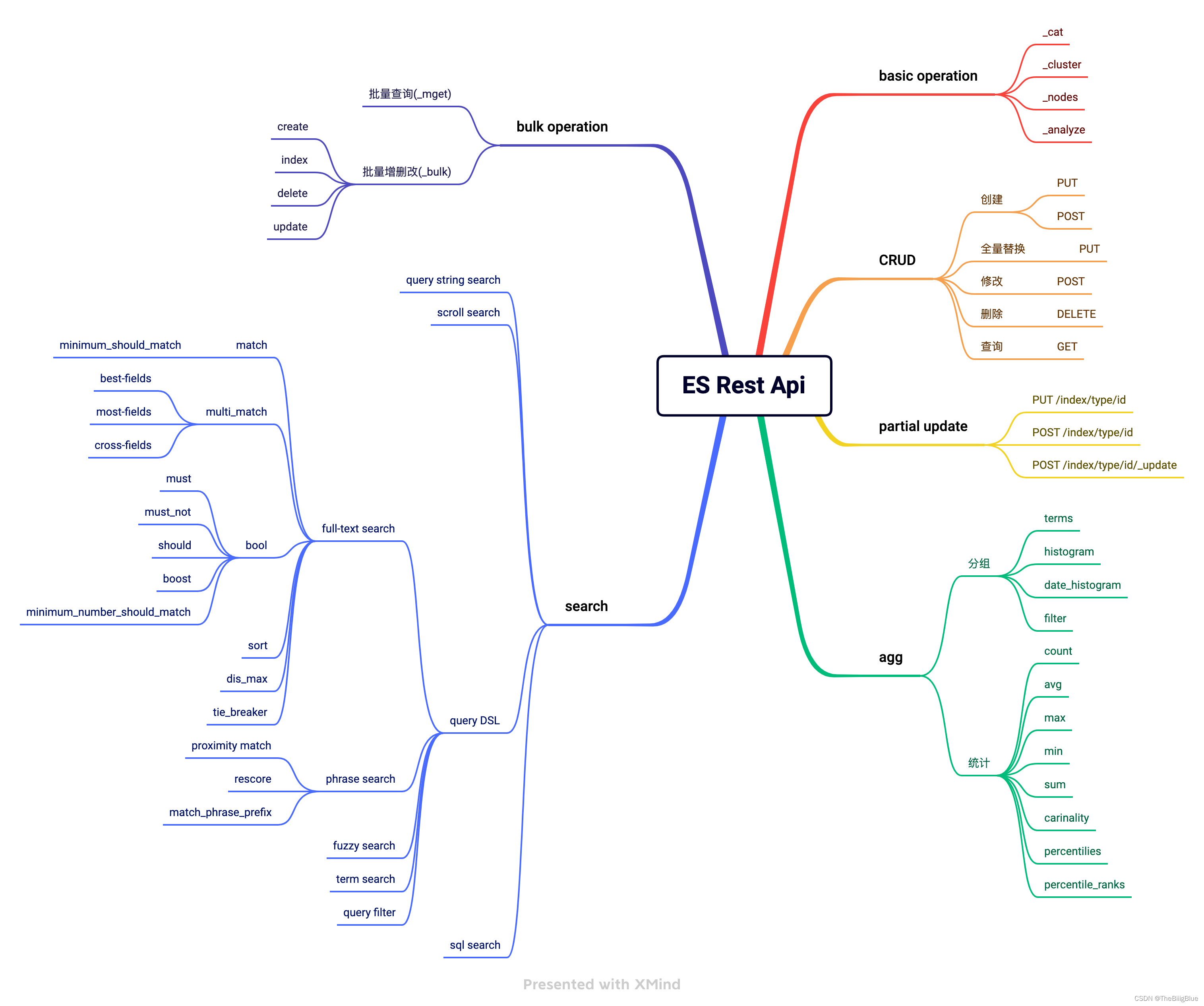
基本操作 basic operation
# 获取集群基本信息
GET /
# 获取别名信息
GET /_cat/aliases?v
# 获取索引信息
GET /_cat/indices?v
# 获取索引的分片信息
GET /_cat/shards?v
# 获取节点的基本信息
GET /_cat/nodes?v
# 获取集群健康状态
GET _cat/health?v
# 获取集群的设置信息,只展示通过API修改过的设置
GET /_cluster/settings
# 获取集群的健康状态
GET /_cluster/health
# 获取集群的详细信息
GET /_cluster/state
# 获取集群的简略状态信息
GET /_cluster/stats
# 获取节点的信息
GET /_nodes
# 获取节点的信息
GET /_nodes/stats
# 测试解析器
GET /_analyze
POST /_analyze
GET /<index>/_analyze
POST /<index>/_analyze
GET /_analyze
{
"analyzer" : "standard",
"text" : "Quick Brown Foxes!"
}
# 索引相关
GET /<index>/_count
GET /<index>/_stats
GET /<index>/_mapping
GET /<index>/_settings
GET /<index>/_search
# 配置es慢日志查询
PUT index*/_settings
{
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms",
"index.search.slowlog.level": "info"
}
增删改查 CRUD
- 创建/全量替换,记录不存在就是创建, 否则是全量替换.
PUT /index/type/id
{
"属性名" : "value"
...
}
# 样例
# PUT 是全量替换, 且是幂等操作
PUT /company/_doc/1
{
"age":25,
"salary":"20k",
"skill":["java","mysql","es"]
}
- 创建
# 如果不传id, 则系统自动生成一个UUID
POST /index/type/
{
"属性名":修改值
}
# 或者
POST /index/type/id
{
"属性名":修改值
}
# 样例
POST /company/_doc
{
"age":30,
"salary":"30k",
"skill":["python","redis","hadoop"]
}
- 修改
# 没有带上的属性会被清除
POST /index/type/id
{
"属性名":修改值
}
# 只更新当前字段,其他字段保留
POST /index/_update/id
{
"doc": {
"属性名":修改值
}
}
# 样例
# POST修改, skill属性被清除了, 属性现在只有age和salary
POST /company/_doc/1
{
"age":40,
"salary":"100k"
}
# 只更新age字段,其他字段保留
POST /company/_update/1
{
"doc": {
"age":20
}
}
- 查询
# 对id查询
GET /index/type/id
# 查询全部
GET /index/_search
# 查询指定条数
GET /index/_search/?size=1
# 样例
GET /company/_doc/1
- 删除
DELETE /index/type/id
# 样例
DELETE /company/_doc/1
部分更新 partial update
# 只更新当前字段,其他字段保留
POST /index/_update/id
{
"doc": {
"属性名":修改值
}
}
# 样例
POST /company/_update/1
{
"doc": {
"age":20
}
}
批量操作 bulk operation
批量处理 _bulk:index、delete、create、update
- 批量创建/更新 index
POST _bulk
{ "index" : { "_index" : "teacher", "_type" : "_doc", "_id" : "1" } }
{ "name" : "Milton" }
{ "index" : { "_index" : "teacher", "_type" : "_doc", "_id" : "2" } }
{ "name" : "Cherish" }
{ "index" : { "_index" : "teacher", "_type" : "_doc", "_id" : "3" } }
{ "name" : "Evan" }
- 批量创建
POST _bulk
{ "create" : { "_index" : "teacher", "_type" : "_doc", "_id" : "4" } }
{ "name" : "yangp" }
{ "create" : { "_index" : "teacher", "_type" : "_doc", "_id" : "5" } }
{ "name" : "yangf" }
- 批量更新
POST /teacher/_doc/_bulk
{ "update" : { "_id" : "4" } }
{"doc":{ "name" : "yangp_update" }}
{ "update" : { "_id" : "5" } }
{"doc":{ "name" : "yangf_update" }}
- 批量删除
POST /teacher/_doc/_bulk
{"delete":{"_id":"4"}}
{"delete":{"_id":"5"}}
批量获取 _mget
- 获取索引teacher中,id为1,2的document
GET /_mget
{
"docs":[
{
"_index":"teacher",
"_type":"_doc",
"_id":"1",
"_source" : false
},
{
"_index":"teacher",
"_type":"_doc",
"_id":"2",
"_source" : ["name"]
}
]
}
- 获取索引teacher中,id为1,2的document
GET /teacher/_mget
{
"docs":[
{
"_type":"_doc",
"_id":"1"
},
{
"_type":"_doc",
"_id":"2"
}
]
}
- 获取索引teacher中,id为1,2的document
GET /teacher/_doc/_mget
{
"docs":[
{ "_id":"1"},
{ "_id":"2" }
]
}
- 获取索引teacher中,id为1,2的document
GET /teacher/_doc/_mget
{
"ids":["1","2"]
}
匹配删除 _delete_by_query
从索引teacher中删除name为“Evan”的document
POST /teacher/_delete_by_query
{
"query":{
"match": {
"name": "Evan"
}
}
}
匹配更新_update_by_query
从索引teacher中,更新name包含“Milton”的文档,设置其gener=“Boy”,age=100
POST /teacher/_update_by_query
{
"query":{
"match": {
"name": "Milton"
}
},
"script":{
"source":"ctx._source.gener=params.gener;ctx._source.age=params.age",
"params":{
"gener":"Boy",
"age":100
}
}
}
搜索 search
待续














 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









