







目录
五、获取好友空间说说的json文件,获取姓名、说说内容、时间等信息,存入数据库
一、前言
玩了这么多年QQ,学了爬虫当然要爬一下啦,肯定有大佬要说爬个QQ空间还要多线程吗,人家只是刚看了多线程方面的知识想用一下啦*٩(๑´∀`๑)ง*。第一次写博客,希望有大佬能指出不足。

二、利用selenium模拟登陆获取cookie并保存到本地
PS:很多朋友问我QQ空间现在用这个方法登录有滑动验证码,但是论文+复试=繁忙,所以提供一个简单的方法:
1、手动登录自己的QQ空间,然后F12->Network,随便点一个链接,手动复制下右边Headers里边的cookie

2、到python里运行下把cookie转字典的代码
cookie = '刚刚手动复制的cookie'
# 字符串cookie转字典格式
cookie_dict = {}
for i in cookie.split('; '):
cookie_dict[i.split('=')[0]] = i.split('=')[1]
print(cookie_dict)效果如下:

3、获取g_tk

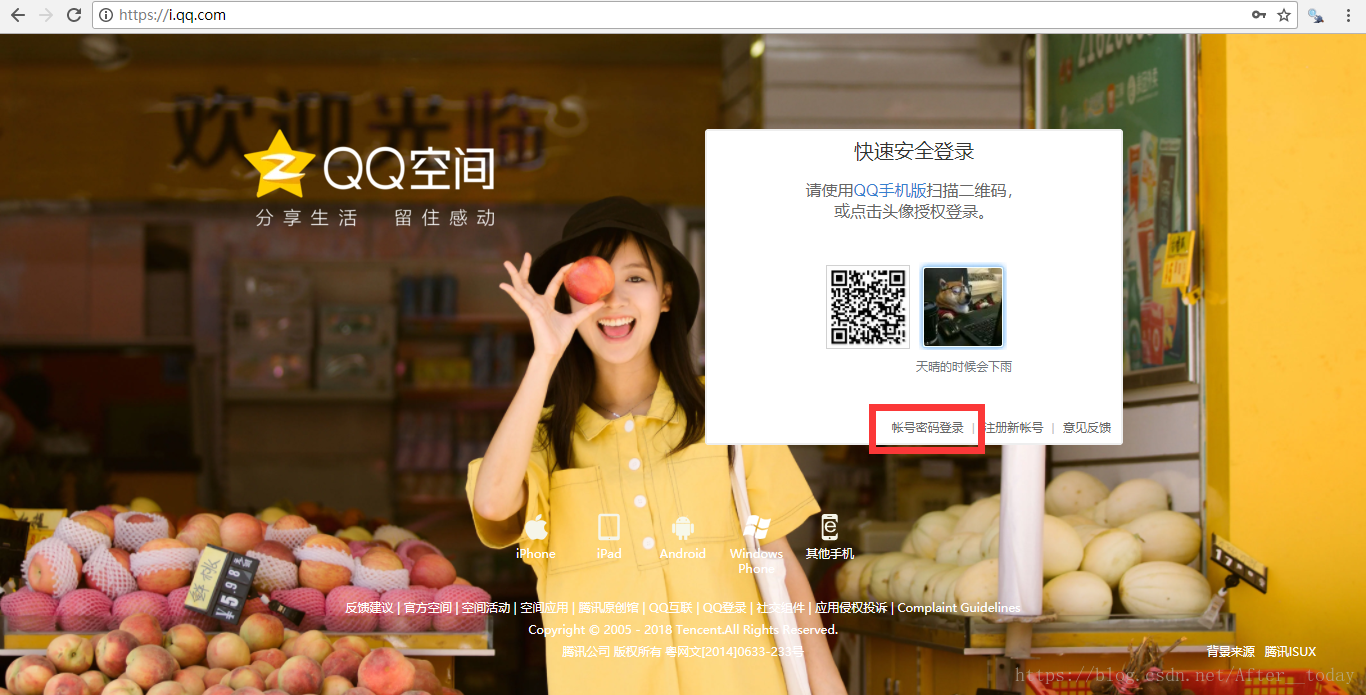
用selenium打开https://i.qq.com/,可以选择直接点击已登陆的QQ头像登陆或者选择账号密码登陆,这里我采用账号密码登陆获取cookie,需要注意的是登陆界面是在一个iframe里面,需要先切换到这个iframe里面然后才能点击输入账号密码以及登陆等操作。

这里我选择把它保存到本地的txt文件中,方便从文件中直接读取。具体获取cookie的代码如下:
from selenium import webdriver
import time
import json
qq_number = '********'
password = '********'
login_url = 'https://i.qq.com/'
driver = webdriver.Chrome()
driver.get(login_url)
#进入登陆的ifame
driver.switch_to_frame('login_frame')
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
time.sleep(1)
driver.find_element 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









