









前序
提出了一种新的基于元学习的数据评估方法。与以前的工作不同,我们的方法将数据评估集成到预测模型的训练过程中。这使得预测模型能够从对给定任务更有价值的样本中获得额外的监督,从而提高预测器和数据评估性能。为了推断数据值,我们提出了一个数据值估计器(DVE),它估计数据值并选择最有价值的样本来训练预测器。这种选择操作基本上是不可微的,因此不能使用传统的基于梯度下降的方法。相反,我们建议使用强化学习(RL),以便对分布式虚拟环境的监督基于在小验证集上量化预测器性能的奖励。
在给定状态、输入样本的情况下,奖励将策略的优化导向最优数据估值的动作。在这里,我们将预测模型学习和评估框架视为一个环境,作为一个新的应用场景的学习辅助机器学习。
性能良好的数据值估计器可以根据需要重新安排训练样本的使用优先级,并且即使在面对低质量、有噪声或域外训练样本的情况下也能够训练高性能预测器。
模型架构
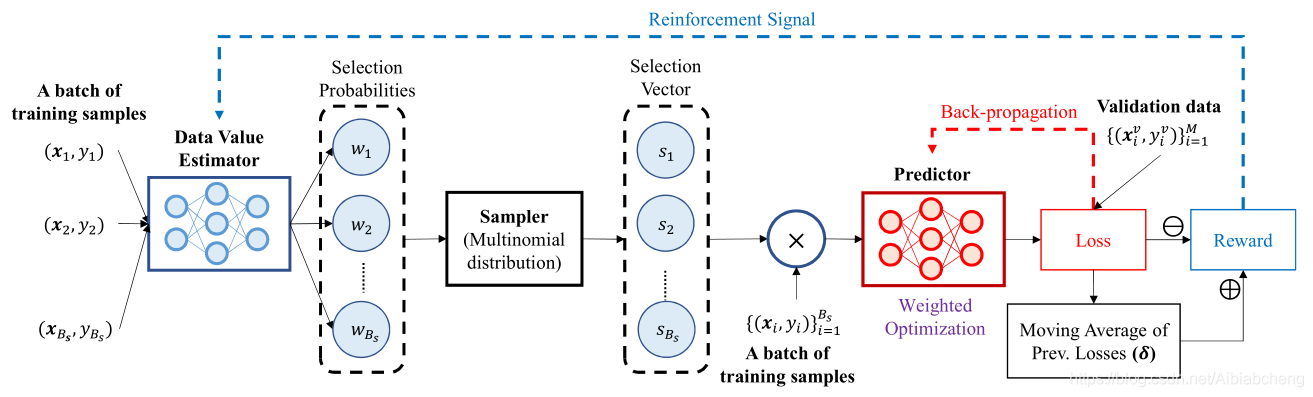
•
一批训练样本被输入到分布式虚拟式分布环境,然后输出选择概率
Wi
的多项式分布。
•
采样器
基于该分布,返回选择向量
s
。
•
使用传统的梯度下降优化,仅使用选择向量
si
=1
的样本来训练目标任务预测模型。选择概率根据样本的重要性对样本进行排序,这些重要性分数被用作数据价值。
•
预测模型的损失在一个小的验证集上进行评估,并与以前损失的移动平均值进行比较,以确定奖励
reward
。
•
最后,这个奖励导向的强化信号更新
DVE
。
【DVE
的输出作为数据价值
】
•
DVRL
首先使用整个数据集训练基础模型
(
无需重新加权
)
。然后,使用这个预先训练的基础模型来初始化预测器网络,并使用
DVRL
更新步骤进行微调。微调过程的收敛比从头开始训练的收敛要快得多。
•
在推断时,数据值估计器可用于获得每个样本的数据值。数据评估的运行时间通常比预测模型
(
如
ResNet-32
模型
)
快得多
(
每个样本不到
1
毫秒
)
。
复杂度:
DVRL
的训练时间与数据集大小不成正比,而是由所需的迭代次数和每次迭代的复杂度决定。最小化计算开销的一种方法是在每次迭代时使用预先训练的模型来初始化预测器模型。

实验
- 12个数据集(3 tabular datasets、7 image datasets、2 language datasets)考虑各种机器学习模型作为baseline预测模型,以强调所提出的模型无关的数据评估框架。
- Baseline:8个。Random、LOO、Data Shapley、Learning to Reweight、MentorNet、Influence Function、ADDA、DANN。
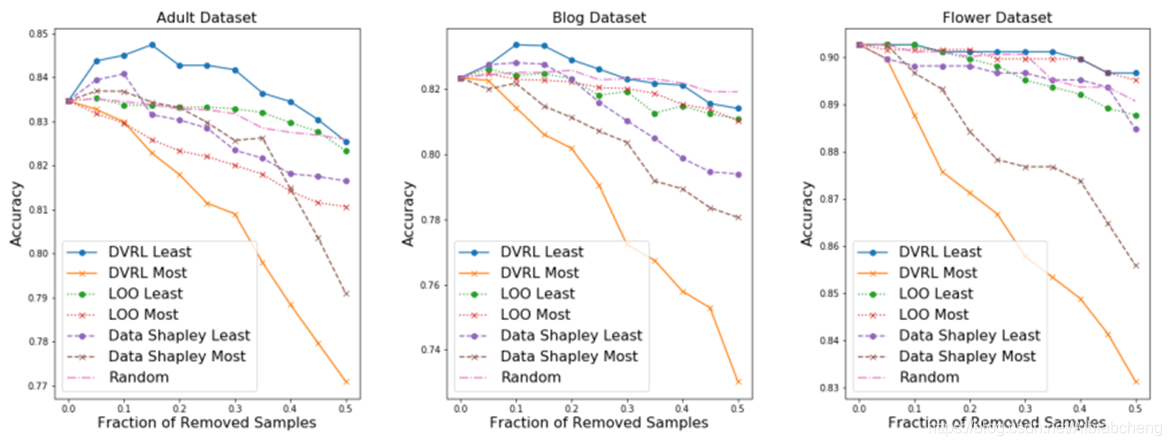
- Removing high/low value samples
从训练集中移除低质量样本可以提高预测器模型的性能,尤其是在训练集包含损坏样本的情况下。另一方面,移除 高质量样本 ,尤其是在小训练数据集的情况下,将显著降低性能 。
- Corrupted sample discovery
- Robust learning with noisy labels
- Domain adaptation
消融实验

marginal information:defined as the difference between the predictions of a separate predictive model (fine-tuned or trained from scratch on the validation set) for the training samples and the original training labels respectively.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











