










“黑箱”特性一直是阻挠强化学习在某些关键领域发展的重要问题,比如医疗、金融、交通等高风险、对可解释性需求迫切的领域,模型的决策不仅要正确,还需要更加透明可信。
在这样的背景下,可解释强化学习逐渐成为当前重要研究方向之一,又因为需求大、挑战多,还没有很统一的分类和评估标准(意味着研究空白很多),成了如今的学术研究热点,陆续出现了不少值得称赞的成果,比如顶会IEEE INFOCOM上的SYMBXRL。
从这些成果来看,这方向的创新主要围绕模型、算法、跨学科方法等多维度,如果想要发论文,也建议大家由此切入。我这边挑选了11篇可解释强化学习最新论文,有需求的同学可以拿来做参考,代码已附方便复现。
扫码添加小助理,回复“977C”
免费获取论文资料和人工智能路线图

SYMBXRL: Symbolic Explainable Deep Reinforcement Learning for Mobile Networks
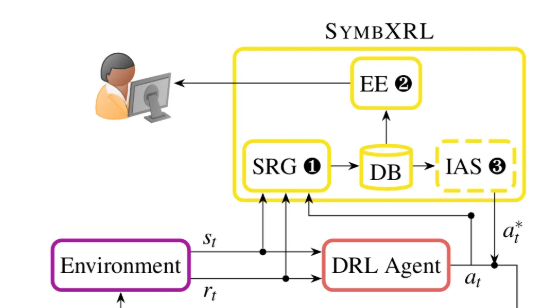
方法:论文提出了SYMBXRL,这是一种可解释强化学习方法。它通过符号AI将DRL代理的状态和动作转换为符号逻辑表示,生成易于理解的解释,并通过意图驱动的行动引导来优化代理行为,提升性能。
创新点:
-
提出SYMBXRL,一种新的可解释强化学习技术,利用符号AI生成DRL代理的直观解释。
-
通过一阶逻辑(FOL)将DRL代理的状态和动作转换为符号表示,提升解释的可读性和语义丰富度。
-
引入意图驱动的行动引导(IAS),通过逻辑规则优化DRL代理的行为,显著提高性能。

Explainable reinforcement learning via temporal policy decomposition
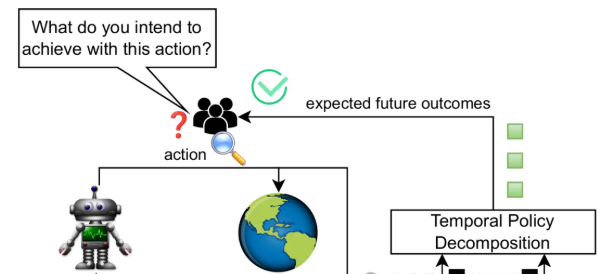
方法:这篇论文提出了TPD,一种新的可解释强化学习方法。TPD 通过将强化学习策略中的广义价值函数分解为一系列预期未来结果,来解释每个时间步上的特定结果,从而提供对 RL 行为的更全面理解。
创新点:
-
提出TPD方法,将强化学习中的价值函数分解为预期未来结果,解释每个动作的未来影响。
-
使用固定时间范围的时序差分学习,实现对EFOs的离策略学习,支持对比不同动作的解释。
-
通过实验验证,TPD能够生成准确的解释,帮助理解策略的未来策略和奖励构成。

扫码添加小助理,回复“977C”
免费获取论文资料和人工智能路线图
Explainable post hoc portfolio management financial policy of a Deep Reinforcement Learning agent
方法:这篇论文提出了一种新的可解释深度强化学习方法,用于金融投资组合管理。该方法结合了近端策略优化算法和SHAP、LIME等可解释性技术,能够在交易时解释模型的预测结果,增强决策的透明度和可解释性。
创新点:
-
提出一种新的可解释深度强化学习(XDRL)框架,专门用于金融投资组合管理。
-
将PPO算法与SHAP、LIME等可解释性技术相结合,增强模型预测的透明度。
-
实现了在交易时对DRL代理行为的解释,评估其是否符合投资策略或风险水平。

Social interpretable reinforcement learning
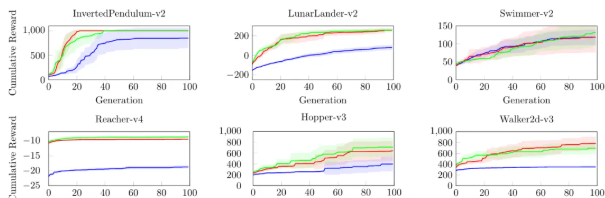
方法:论文提出了一种名为SIRL的可解释强化学习方法,通过模仿群体学习过程,在合作和个体阶段分别进行学习,最终在多个基准测试中实现了高效且可解释的学习效果。
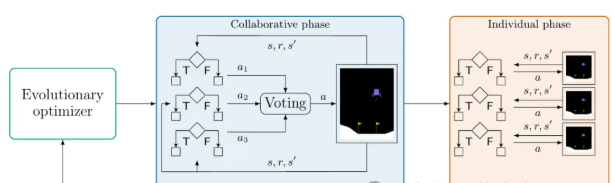
创新点:
-
提出SIRL方法,基于社会学习原理,通过群体智能体合作与个体学习相结合的方式,提高可解释强化学习的效率和性能。
-
采用投票机制选择动作,结合合作和个体学习阶段,减少计算成本并提升学习效果。
-
在多个基准任务上,SIRL在性能、训练成本和可解释性方面均优于现有可解释方法。
扫码添加小助理,回复“977C”
免费获取论文资料和人工智能路线图



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









