










今天来聊一聊BERT和GPT的分词器,了解大模型的第一步:Tokenizer。
Tokenizer(分词器)是大语言模型(如BERT和GPT)预处理文本的核心组件,其作用是将原始文本拆解为子词、单词或字符,同时保留语义和结构信息。
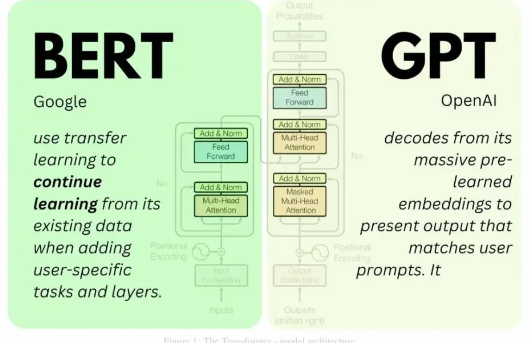
一、BERT(WordPiece)
BERT的Tokenizer:基于WordPiece的子词分词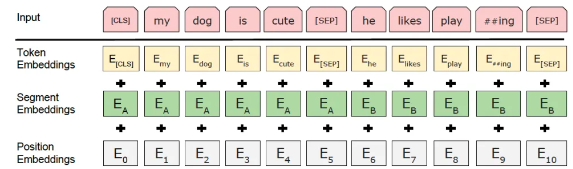
一、分词工作原理:
BERT使用WordPiece算法生成子词(subword)单元,通过贪心算法迭代合并语料中高频出现的字符对,平衡词汇表大小与OOV(未登录词)问题。
BERT将特殊标记预置在输入序列中,通过结构化标记引导模型理解任务目标与上下文边界。
[CLS]:表示序列的起始位置,常用于分类任务。
[SEP]:分隔不同句子或段落。
例如,Input 'my dog is cute. he likes playing' 分词为:
'[CLS]'、'my'、'dog'、'is'、'cute'、'[SEP]'、'he'、'likes'、'play'、'##ing'(“##”表示子词延续)和'[SEP]'。
二、专业术语:
忽略:WordPiece算法、贪心算法、OOV问题。
关注:Token(词元)、Tokenizer(分词)、Subword(子词)、Tag(标记)
三、存在问题:
(1)中文适配性差
BERT 原始 Tokenizer 依赖空格分词(如英文),对中文等无显式空格的语言需额外分词预处理。
(2)难以适应动态任务
[CLS]、[SEP] 等特殊标记的语义和位置固定,难以适应动态任务需求(如可变长度的分类任务、多轮对话)。
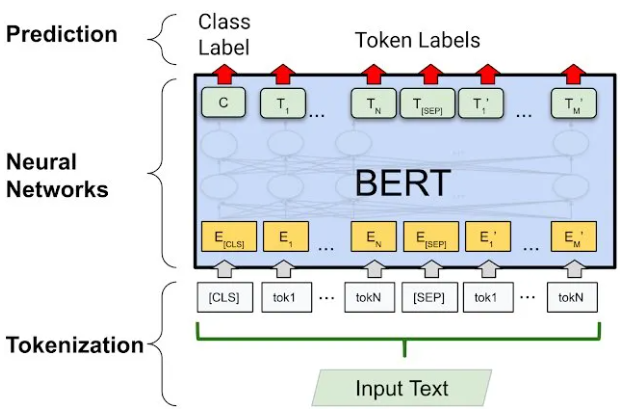
二、GPT(BPE)
GPT的Tokenizer:基于BPE的子词分词
GPT(尤其是GPT-2/3)使用BPE算法,通过合并高频字节对生成子词,与WordPiece不同,BPE更注重频率统计。同时GPT-2采用字节级BPE,支持多语言输入(如中文、代码)而无需额外预处理。

二、专业术语:
忽略:BPE算法、频率统计、字节级BPE。
关注:Token(词元)、Tokenizer(分词)、Subword(子词)
扫码添加小助理,获取大模型路线图

三、BPE和WordPiece两者差异:
(1)符号标记
BPE:无特殊标记,直接合并高频子词(如happy)。
WordPiece:依赖##标记后缀(如##ness),拆分规则更严格。
(2)跨语言能力(中英文)
BPE:通过字节级编码统一处理多语言(如pneu+monia)。
WordPiece:需预分词(如中文按字拆分),跨语言泛化性弱。
(3)适用场景
BPE:生成任务(GPT)、多语言混合、非规范文本WordPiece。
WordPiece:理解任务(BERT)、短文本分类、精准语义解析。

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









