










导读:今天这篇文章将从YOLO v1 到 v12的发展历程、相关知识都分享给你,助你轻松入门,快速上手!
YOLO 系列为什么被广泛应用?
YOLO(You Only Look Once)之所以被广泛应用,主要是因为其极快的检测速度和较高的精度,实现了实时目标检测。它将目标检测任务转化为单一的回归问题,直接从图像中预测边界框和类别概率,这种端到端的架构使其在工业界和学术界都备受青睐。
YOLO 系列 发展历程
YOLOv1:开创先河
想象一下,在 YOLOv1 出现之前,目标检测就像在一幅大拼图里找特定的几块,过程繁琐又复杂。YOLOv1 呢,直接把这个问题变得简单粗暴,它把目标检测当成一个回归问题,就好比让模型直接说出目标物体在图片里的位置(边界框)和是什么类别。它的出现,让检测速度大幅提升,能在实时场景里派上用场了,就像给检测任务装上了小马达。
不过它也有缺点,对那些小小的目标,就像拼图里特别小的碎片,检测效果不太好,而且定位目标位置的时候也不够精准。从论文的图来看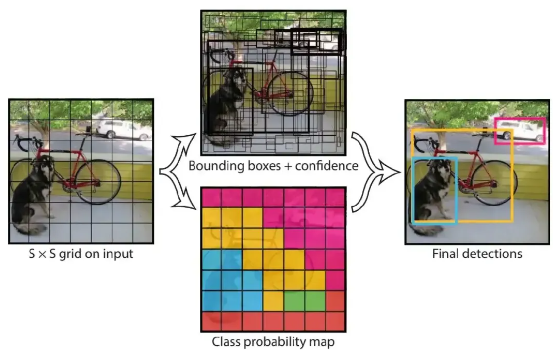
它把输入图像划分成 S×S 个网格,每个网格负责预测目标的边界框和类别概率,这种简单直接的方式虽然快,但也有局限性。
YOLOv2:优化升级
YOLOv2 就像是给 YOLOv1 做了一次全面升级。它引入了 Batch Normalization(批归一化),这东西就像给模型的训练过程做了个 “调理”,让模型收敛速度更快,也更稳定,训练的时候不再那么容易 “跑偏”。
它还采用了高分辨率分类器,在检测前把图像 “收拾” 得更精细,就像拼图前先把碎片都整理好。并且通过 Anchor Boxes 机制,给模型提供了不同尺寸的 “框模板”,这样就能更好地检测不同大小的目标,就像有了不同规格的拼图框,能更精准地匹配碎片。整体性能有了显著提升。
参考论文里,能清晰看到这些改进是如何实现的,下面是论文地址,有需求自取~
YOLOv3:性能飞跃
YOLOv3 进一步改进了网络结构,它用的 Darknet - 53 骨干网络,就像是给模型换了个更强大的 “大脑”,增强了特征提取能力,能从图像里获取更多有用信息。它还采用多尺度预测,简单说就是从不同大小的 “视角” 去看图像,这样不管大目标还是小目标,都能被更好地检测到,就像用不同倍数的放大镜看拼图。
在损失函数设计上也更合理,把边界框回归、目标置信度和类别预测的损失都照顾到了,让模型在训练的时候能从各个方面提升自己。从论文的图示中,能直观感受到这些改进带来的效果。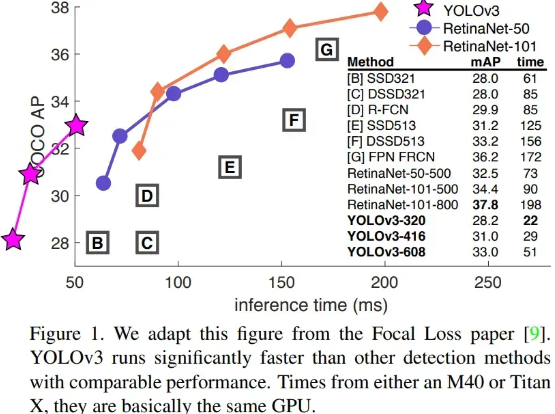
YOLOv4:集大成者
YOLOv4 堪称 “集大成者”,它在训练技巧和网络结构上做了大量优化。它结合了很多先进技术,像 Mish 激活函数,能让模型在处理信息的时候更聪明;CSPNet(跨阶段局部网络),让模型的计算效率更高。它在提升模型性能的同时,还保持了较高的推理速度。在复杂场景下,它的检测准确率和召回率都表现很好,就像一个厉害的拼图高手,不管拼图多复杂,都能又快又准地完成。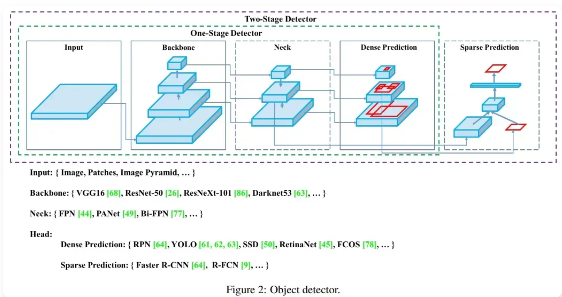
YOLOv5 - YOLOv12:持续创新
从 YOLOv5 到 v12,这些版本就像一群不断进化的小能手,在不同方面持续改进。有的在模型轻量化上下功夫,让模型变得更 “苗条”,在一些资源有限的设备上也能轻松运行;有的针对特定场景做适应性优化,比如在交通场景里检测车辆和行人,就把模型调整得更适合这类场景;还有的引入新的检测算法和数据增强策略,让模型能学习到更多不同的 “拼图技巧”。每个版本都根据不同的应用需求和硬件条件进行调整,让 YOLO 系列能在更广泛的领域大显身手。在对应版本的论文中,能看到它们各自独特的创新点。
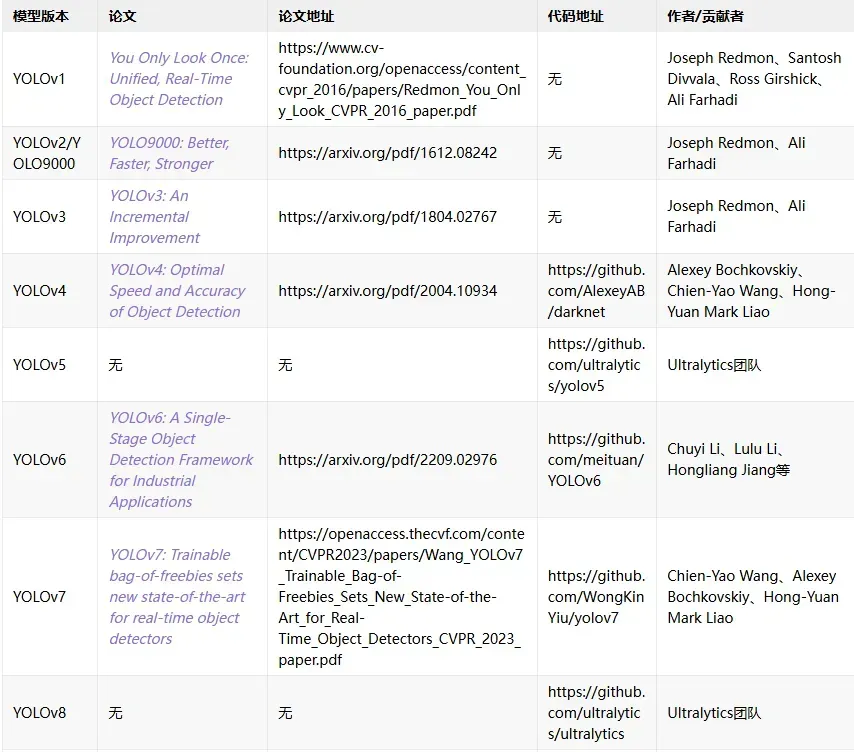
更多关于YOLO系列的论文地址+模型源码我们已经为大家准备好了,有需要的扫码即可获取资料包


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









