






第一个访问的页面没有wcoutput这个文件,参考了原视频下的评论已经自己找方法后发现
wordcount在页面上运行不出来,只出个temp,去/opt/module/hadoop-3.1.3/etc/hadoop里vim mapred-site.xml 添加
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
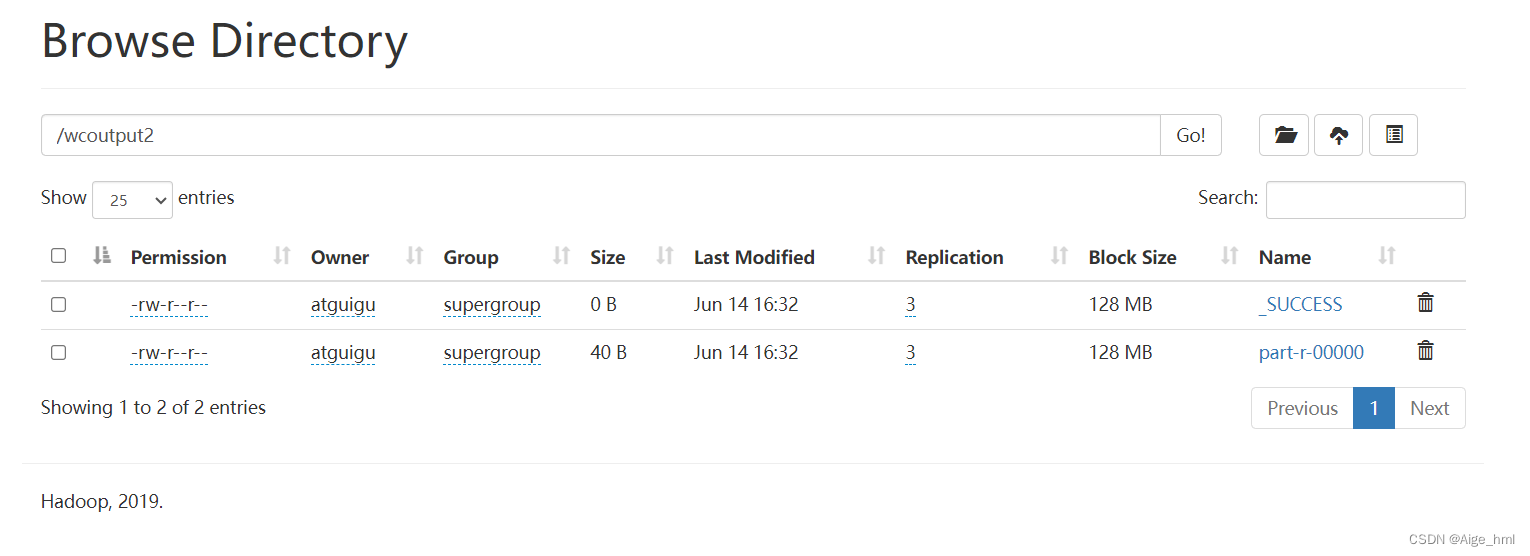
第二个是wcoutput里面没有出来两个文件
有博主说是因为word.txt里面存在空行,把空行删除就可以了,但是对我没有用;也有博主说是应该在wcinput/word.txt,但是我也试过没有用,后来等了十几分钟自己又重新运行了命令,就直接出来了,很无语,wcoutput好像有没有都没有影响,这小小的bug卡了两个小时,小白真的很痛苦
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput2

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









