







大多数情况下,适当提出你的class和定义以及functions声明,是花费最多心里的两件事。一旦正确完成它们,相应的实现大多直接了当。尽管如此,还是有些东西需要小心。太快定义变量可能造成效率上的拖延;多度使用转型(casts)可能导致代码变慢又难维护,又找来微妙难解的错误;返回对象“内部数据之号码牌”可能会破坏封装并留给客户虚吊号码牌;未考虑异常带来的冲击则可能导致资源泄漏和数据败坏;过渡热心的inlining可能引起代码膨胀;多度耦合则可能导致让人不满意的冗长建置时间。
条款26:尽可能延后变量定义式的出现时间
比如下面这个例子,你需要加密密码,如果密码太短,抛出异常,否则返回加密后的版本:
|
1
2 3 4 5 6 7 8 9 10 11 |
std::string encryptPassword(
const std::string &password)
{ using namespace std; string encrypted; if(password.length() < MinimumPasswordLength) { throw logic_error( "Password is too short"); } ... //开始加密 return encrypted; } |
|
1
2 3 4 5 6 7 8 9 10 11 |
std::string encryptPassword(
const std::string &password)
{ using namespace std; if(password.length() < MinimumPasswordLength) { throw logic_error( "Password is too short"); } string encrypted; ... //开始加密 return encrypted; } |
|
1
2 3 4 5 6 7 8 9 10 11 |
std::string encryptPassword(
const std::string &password)
{ using namespace std; if(password.length() < MinimumPasswordLength) { throw logic_error( "Password is too short"); } string encrypted(password); ... //开始加密 return encrypted; } |
如果在循环语句中定义变量,我们将需要考虑到它的构造(析构)成本与赋值成本所承受成本的大小比较问题,看下面这两种形式:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 |
//A :变量定义于循环外 Widget w; for( int i = 0; i < n; i++) { w = ..; ... } //B:变量定义于循环内 for( int i = 0; i < n; i++) { Widget w(xxx); ... } |
A: 1个构造函数 + 1个析构函数 + n个赋值函数
B: n个构造函数 + n个析构函数
我们开始比较:如果Widget的构造析构成本比赋值成本要高的话,无疑A的做法总体效率要高;反之则B的做法效率高.
请记住:
◆ 尽可能延后变量定义式的出现.这样做可增加程序的清晰度并改善程序效率.
条款27:尽量少做转型动作
(T)expression //将expression转换为T类型
函数转型语法如下:
T(expression) 将expression转换为T类型
这两种转型语法,我们称之为"旧式转型",既然是"旧式",那当然有"新式转型"啰,当然有,C++中提供了四种"新式转型",我大概将它们的适应的范围介绍一下(关于新式转换的详细的介绍,我在C++语言基础分类中的已经写了一篇,请注意浏览,呵):
■ const_cast用来将对象的const属性去掉,功能单一,使用方便,呵呵.
■ dynamic_cast用于继承体系下的"向下安全转换",通常用于将基类对象指针转换为其子类对象指针,它也是唯一一种无法用旧式转换进行替换的转型,也是唯一可能耗费重大运行成本的转型动作.
■ reinterpret_cast 低级转型,结果依赖与编译器,这因为着它不可移植,我们平常很少遇到它,通常用于函数指针的转型操作.
然后看一个让人无比纠结的例子:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
class Base
{ public: Base( int i = 0): bVal(i) { cout << "基类构造函数" << endl; } virtual void say() { cout << ++bVal << endl; } int bVal; }; class Drived: public Base { public: Drived( int i = 10, int j = 5): Base(i), dVal(j) { cout << "派生类构造函数" << endl; } void say() { cout << "基类值为:" << endl; static_cast<Base>(* this).say(); //错误做法 // Base::say(); //正确做法 cout << "派生类值为:" << endl; cout << dVal << endl; } private: int dVal; }; |
|
1
2 3 4 5 6 7 8 |
int main()
{ Drived d; d.say(); cout << d.bVal << endl; return 0; } |
Base::say(); 结果如下:
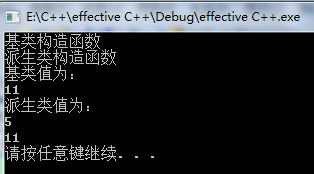
static_cast<Base>(*this).say(); 结果:
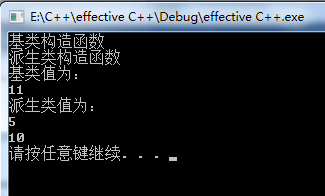
虽然static_cast<Base>(*this).say();的打印结果都是11,但是使用cout<<d.bVal<<endl;时,d.bVal的值却不一样了:使用强制类型转化后,d.bVal的还是10;而调用基类函数时,d.bVal的值就变成了11。这中间的问题出在哪里了呢?就是static_cast<Base>(*this).say();是在当前对象基类成分的副本上调用say函数,而不是当前对象本身。所以cout<<++bVal<<endl;修改的是副本的bVal值,而不是d中的。总而言之一句话:当在派生类中想调用基类的某些成分时,直接通过作用域操作符告诉使用的是基类的成员,而不是通过类型转换。
下面再说说dynamic_cast。这个函数效率很低,能不用就不用吧。通常,只有当你想在一个认定为派生类对象的身上执行派生类操作,而你却只有一个基类指针或者引用时,才需要dynamic_cast:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
class Base
{ public: Base( int i = 0): bVal(i) { cout << "基类构造函数" << endl; } /* virtual void say() { cout<<"基类函数"<<endl; }*/ virtual void fun() {} private: int bVal; }; class Drived: public Base { public: Drived( int i = 10, int j = 5): Base(i), dVal(j) { cout << "派生类构造函数" << endl; } void say() { cout << "派生函数" << endl; } private: int dVal; }; int main() { Base *pd = new Drived; Drived *pd1 = dynamic_cast<Drived *>(pd); pd1->say(); return 0; } |
通常,有两种办法解决这个问题:
1.在基类里添加对应的虚函数:
|
1
2 3 4 5 6 |
public:
Base( int i = 0): bVal(i) { cout << "基类构造函数" << endl; } virtual void say() {} //什么也不做 |
|
1
2 |
Base *pd =
new Drived;
pd->say(); |
|
1
2 3 4 |
typedef vector<std::tr1::shared_ptr<Drived>> VPD;
VPD d( 1); for(VPD::iterator iter = d.begin(); iter != d.end(); ++iter) (*iter)->say(); |
总而言之,好的代码很少使用类型转化。如果非要类型转换,则应该使用C++风格的,且应该把它隐藏在某个函数中,而不是暴漏给用户。
条款28:避免返回handles指向对象内部成分
句柄是一种特殊的智能指针 。当一个应用程序要引用其他系统(如数据库、操作系统)所管理的内存块或对象时,就要使用句柄。句柄与普通指针的区别在于,指针包含的是引用对象的内存地址,而句柄则是由系统所管理的引用标识,该标识可以被系统重新定位到一个内存地址上。这种间接访问对象的模式增强了系统对引用对象的控制。
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
#include<iostream>
#include<memory> using namespace std; //点类 class Point { public: Point( int xVal, int yVal): x(xVal), y(yVal) {} ~Point() {} void setX( int newX) { x = newX; } //返回X坐标,以后测试用 int getX() const { return x; } void setY( int newY) { y = newY; } private: int x; int y; }; //矩形数据结构 struct RectData { RectData( const Point &p1, const Point &p2): ulhc(p1), lrhc(p2) {} Point ulhc; //坐上 Point lrhc; //右下 }; //矩形类 class Rectangle { public: Rectangle(RectData data): pData( new RectData(data)) {} //const Point &upperLeft() const //因为返回Point,实际上可以使用setX,与const不符合 { return pData->ulhc; } //const Point &lowerRight() const //因为返回Point,实际上可以使用setY,与const不符合 { return pData->lrhc; } private: std::tr1::shared_ptr<RectData> pData; }; int main() { Point coord1( 0, 0); Point coord2( 100, 100); RectData data(coord1, coord2); const Rectangle rec(data); rec.upperLeft().setX( 50); //顺利编译通过 system( "pause"); return 0; } |
1.变量的封装性最多等于“返回其引用”的函数的访问级别:这里upperLeft函数是返回的都是Point类型的引用,所以即使矩形的数据pData被声明为private,但是还是可以访问里面的内容。
2.如果函数成员返回一个指向数据的引用,那么且这个数据被储存在对象之外,那么即使这个函数被声明为const,我们也可以通过这个函数修改它。在这里,Rectangle类的数据成员只是一个指向RectData的智能指针,而指针实际指向的数据,却是在RectData中储存的。upperLeft虽然声明为const,但这只意味着他不修改指针(的指向),至于指针指向的内容,当然是可以修改的了。
同理,返回对象的引用、指针、迭代器都会造成这种局面,它们都是“句柄”。返回一个代表对象内部数据的句柄,会降低对象的封装。
在这个例子中,只要对它们的返回类型加上const就可以了:
|
1
2 3 4 5 6 7 8 |
const Point &upperLeft()
const
{ return pData->ulhc; } const Point &lowerRight() const { return pData->lrhc; } |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
//一个GUI对象 class GUIObject { public: GUIObject(Rectangle r) {} //返回一个指定大小的矩形框 const Rectangle getRec() const { Point coord1( 50, 50); Point coord2( 200, 200); RectData data(coord1, coord2); const Rectangle rec(data); return rec; } }; //返回obj的外框 const Rectangle boundingBox( const GUIObject &obj) { return obj.getRec(); } |
|
1
2 3 4 5 6 7 8 9 10 11 |
Point coord1(
10,
10);
Point coord2( 100, 100); RectData data(coord1, coord2); const Rectangle rec(data); GUIObject obj(rec); //一个GUI对象指针 GUIObject *pgo = &obj; //获取它的左上角点 const Point *pUpperLeft = &(boundingBox(*pgo).upperLeft()); cout << pUpperLeft->getX(); return 0; |
条款29:为“异常安全”而努力是值得的
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
class PrettyMenu
{ public: ... void changeBackground(std::istream &imgSrc); //改变背景图案 ... private: Mutex mutex; //互斥器 Image *bgImage; //保存当前背景图案 int imageChange; //记录背景图案改变的次数 }; 如果changeBackground()函数如下定义: void PrettyMenu::changeBackground(std::istream &imgSrc) { lock(&mutex); //取得互斥器 delete bgImage; //删除旧的背景图案 ++imageChange; //修改次数+1 bgImage = new Image(imgSrc); //添加新的背景图案 unlock(&mutex); //释放互斥器 } |
这个函数版本问题很多:如果new操作抛出异常,则互斥器永远不会释放,同时图案指针就指向一个空对象,并且在修改失败的情况下次数仍然累加上去。
优化方法:(1)以对象管理资源:
|
1
2 3 4 5 6 7 8 |
void PrettyMenu::changeBackground(std::istream &imgSrc)
{ Lock m1(&mutex); //获得互斥器并放它放进资源管理类中 delete bgImage; ++imageChange; bgImage = new Image(imgSrc); //不需要再调用unlock()了 } |
|
1
2 3 4 5 6 7 8 9 10 11 12 |
class PrettyMenu
{ ... std::tr1::shared_ptr<Image> bgImage; ... }; void PrettyMenu::changeBackground(std::istream &imgSrc) { Lock m1(&mutex); bgImage.reset( new Image(imgSrc)); //以new的执行结果设定为bgImage的内部指针 ++imageChanges; } |
(3)使用copy and swap方法下的pimpl idiom手段:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
struct PMImpl
//使用结构而不使用类,因为PrettyMenu类的数据封装已经由私有成员的智能指针来保证,使用结构会更灵活 { std::tr1::shared_ptr<Image> bgImage; int imageChanges; }; class PrettyMenu { ... private: Mutex mutex; std::tr1::shared_ptr<PMImpl> pImpl; }; void PrettyMenu::changeBackground(std::istream &imgSrc) { using std::swap; Lock m1(&mutex); //获得互斥器的副本 std::tr1::shared_ptr<PMImpl> pNew( new PMImpl(*pImpl)); pNew->bgImage.reset( new Image(imgSrc)); //修改副本 ++pNew->imageChanges; swap(pImpl, pNew); //交换数据,释放互斥器 } |
1.“异常安全性”(exception safety)能够为函数带来两个好处:
- 不泄漏任何资源;
- 不允许数据败坏:操作未正确完成却已经改变了部分数据。
以这样的思想设计的函数(异常安全性函数)提供以下三个保证,即具有三个安全性等级:
- 基本承诺:如果抛出异常,程序内的任何事物仍然保持在有效状态下,没有任何对象或数据结构会因此而败坏,所有对象都处于一种内部前后一致的状态。但程序的现实状态不可预料。
- 强烈保证:如果异常被抛出,程序状态不改变——如果函数成功,就完全成功;如果函数失败,程序会回复到调用函数之前的状态。
- 不抛掷(nothrow)保证:承诺绝不抛出异常,总能完成所承诺的功能。
应该尽量提供更高安全性的函数。
2.任何使用动态内存的东西(如STL容器)如果无法找到足够的内存以满足需求,通常便会抛出一个bad_alloc异常。
3.应当使异常安全性尽量更高并尽量等级一致。
(1)提供”不抛掷保证“:实现上当然希望有”不抛掷保证“,但是很多情况下并不现实,比如在调用纯C语言部分的函数时。
(2)提供”强烈保证“:
copy and swap方法很容易得到“强烈保证”等级的异常安全性:为计划修改的对象(原件)复制出一份副本,然后在副本上做一切必要的修改,修改成功后再将修改过的副本和原对象在一个不抛出异常的操作中转换。这样即使修改过程中抛出了异常,则原件并未改变。
但是该方法并不能保证整个函数都有强烈的异常安全性,比如函数可能调用了其他异常安全性更低(如基本承诺甚至无异常安全性)的函数,从而使该函数的异常安全性降低到更低的水平。即使相互调用的函数异常安全性水平相当,仍然可能会降低异常安全性,即所谓的”side effect“,这取决于它们所操作的数据是局部的还是全局的。这类似于”木桶原理“——相互调用的函数的异常安全性由水平最低的那个函数决定。该方法另外一个缺点是效率低下。
copy and swap方法在实现上通常采用所谓的“pimpl idiom“方法:将所有”隶属对象的数据“从原对象中放进另一个对象内,然后赋予原对象一个指针,指向那个实现对象。
(3)提供”基本保证“:当“强烈保证”不切实际时,应当提供“基本保证”。
4.系统中有一个函数不具备异常安全性,那么整个系统就不具备异常安全性。
编写代码时应确保:
- (1)以对象管理资源,以阻止资源泄漏。
- (2)挑选三个“异常安全保证”中的某一个实施于所有函数上。应当挑选现实能够保证的最强烈等级;只有当函数调用了传统代码,才别无选择地将系统设定为“无任何保证”。将这些东西写进开发文档里。
条款30:透切了解inlining的里里外外
申请有两种形式:隐式申请:在类内部定义的函数都默认为inline函数,甚至包括内部定义的友元函数。显示申请:使用inline关键字。
其次,inline函数一般要放到头文件中,因为编译器需要在程序调用内联函数时立刻将他替换,所以必须要知道这个函数的具体内容。类似的还有模板,必须在让编译器能够在调用模板的的程序所在的源文件中看到模板,然后才能对它实例化。有一点需要注意,如果你把一个函数模板定义为内联的,那么这个模板的所有实例都是内联的。如果没有必要让这个函数模板的所有实现都是内联的,那么就不要把它声明为内联。
大部分编译器,对于过于复杂的inline函数,都会忽略这个申请,比如带有循环或者递归的函数,以及虚函数,虚函数要求在程序执行到时才判断到底使用的是哪个函数,而内联函数意味着在程序执行前就将函数替换为被调用函数的内容。
有些时候,即使编译器希望使用内联函数,但还是会产生一个函数的本体,比如:使用某个内联函数的地址(指向函数的指针):
|
1
2 3 4 5 6 7 8 |
inline
int min(
const
int &a,
const
int &b)
{ return a > b ? a : b; } int (*pf)( const int &, const int &) = min; cout << pf( 3, 4) << endl; cout << min( 3, 4) << endl; |
很多时候,我们都倾向于把类的构造函数,析构函数设为内联函数,但这并不是一个好注意。因为很多看似简短的构造函数身后,隐藏着编译器为你默默填写的大量的函数,尤其是在继承派生体系中。
如果把一个函数声明为inline,那么如果修改了他,所有调用它的函数程序都得重新编译,而如果它只是一个普通函数,那么只需要重新链接就可以了。
所以,我们应该一开始先不要声明任何函数为inline,而是以后随着程序的逐步深入,才考虑哪些函数声明为inline
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
//(6)"将构造函数和析构函数进行inling"是一个很糟糕的想法.看下面这段代码: class Base { public: ... private: std::string bm1, bm2; }; class Derived: public Base { public: Derived() {} //空函数耶,够简单了吧?我想让它inlining,可以么? ... private: std::string dm1, dm2, dm3; }; |
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
Derived::Derived()
//"空白Derived构造函数"的观念性实现 { Base::Base(); //初始化"Base成分" try { dm1.std::string::string(); } catch(...) { Base::~Base(); throw; } try { dm2.std::string::string(); } catch(...) { dm1.std::string::~string(); Base::~Base(); throw; } try { dm3.std::string::string(); } catch(...) { dm2.std::string::~string(); dm1.std::string::~string(); Base::~Base(); throw; } } |
■ 将大多数inlining限制在小型,被频繁调用的函数身上.这可使日后的调试过程和二进制升级更容易,
也可使潜在的代码膨胀问题最小化,使程序的速度提升机会最大化.
■ 不要因为function templates出现在头文件,就将它们声明为inline.
条款31:将文件间的编译依存关系降至最低
|
1
2 3 4 5 6 7 8 9 10 11 12 |
class Person
{ public: Person( const string &nm , Date d): name(nm), birthday(d) {} void getBirthday() { cout << birthday.getYear() << "." << birthday.getMonth() << "." << birthday.getDay() << endl; } private: string name; Date birthday; }; |
|
1
2 3 4 5 6 7 8 9 10 |
class Date;
class String; class PersonImpl; class Peason { public: void getBirthday(); private: std::tr1::shared_ptr<PersonImpl> pImpl; }; |
1.若果使用对象的引用或对象指针可以完成任务,那么就不要使用对象。因为对象的引用和指针时,只用了类的名字,而不需要它的定义,而使用对象时必须要有对象的定义。
2.尽量用类声明替换类定义。比如声明一个函数时,函数的形参,返回值是一个类时,只要求类的声明就好了。但是在调用函数前,必须知道这些类的定义。
3.为声明式和定义事提供不同的头文件。你的程序只需要类的声明就能完成,那么就让他include类声明的头文件。这个思想来源于C++标准库。
下面举一个例子:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
//data.h class Date { public: Date( int d, int m, int y): day(d), month(m), year(y) {} int getDay() { return day; } int getMonth() { return month; } int getYear() { return year; } Date( const Date &date): day(date.day), month(date.month), year(date.year) {} private: int day; int month; int year; }; //personIplm.h #include "date.h" class PersonImpl { public: PersonImpl(Date d): birthday(d) {} Date &getBirthday() { return birthday; } private: Date birthday; }; //person.h class Date; class PersonImpl; class Person { public: Person(Date d); void getBirthday(); private: std::tr1::shared_ptr<PersonImpl> pImpl; }; //person.cpp Person::Person(Date d): pImpl( new PersonImpl(d)) {} void Person::getBirthday() { cout << pImpl->getBirthday().getYear() << "." << pImpl->getBirthday().getMonth() << "." << pImpl->getBirthday().getDay() << endl; } //main.cpp int main() { Person p(Date( 12, 9, 2012)); p.getBirthday(); return 0; } |
另外一种方法是通过抽象类来实现:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
//person.h class Date; //接口类:抽象基类描述派生类接口 //不带数据成员 class Person { public: //工厂函数,返回指向这个类的指针 static std::tr1::shared_ptr<Person> creat( const Date &d); virtual Date getBirthday() const = 0; }; //date.h class Date { public: Date( int d, int m, int y): day(d), month(m), year(y) {} int getDay() { return day; } int getMonth() { return month; } int getYear() { return year; } Date( const Date &date): day(date.day), month(date.month), year(date.year) {} private: int day; int month; int year; }; //realperson.h #include "date.h" #include "person.h" //具体的类 class RealPerson: public Person { public: RealPerson( const Date &d): birthday(d) {} virtual ~RealPerson() {} Date getBirthday() const { return birthday; } private: Date birthday; }; //person.cpp #include "realPerson.h" std::tr1::shared_ptr<Person> Person::creat( const Date &d) { return std::tr1::shared_ptr<Person>( new RealPerson(d)); } |
总之,编译依存性最小化的一般构想是依赖于声明,而不依赖于定义。基于此构想的两个手段是:句柄类和接口类。















 2098
2098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









