







spark下载链接:https://pan.baidu.com/s/1xZj2YGqds1JZAJF6o9uKfA
提取码:o9wv
一、安装
1.解压缩spark-1.6.0-bin-hadoop2.6.tgz
tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
2.进入con目录
-
spark-env.sh新增参数
cp spark-env.sh.template spark-env.shvim spark-env.shexport SCALA_HOME=/usr/local/src/scala-2.10.5 export JAVA_HOME=/usr/local/src/jdk1.8.0_172 export HADOOP_HOME=/usr/local/src/hadoop-2.6.5 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop SPARK_MASTER_IP=master SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6.0-bin-hadoop2.6 SPARK_DRIVER_MEMORY=1G
-
slaves新增参数
cp slaves.template slavesvim slavesslave1 #从节点的hostname或者ip slave2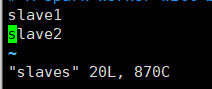
3.将spark-1.6.0-bin-hadoop2.6分发到slave、slave2
scp -r spark-1.6.0-bin-hadoop2.6 slave1:/usr/local/src
scp -r spark-1.6.0-bin-hadoop2.6 slave2:/usr/local/src
4.启动Spark
./sbin/start-all.sh
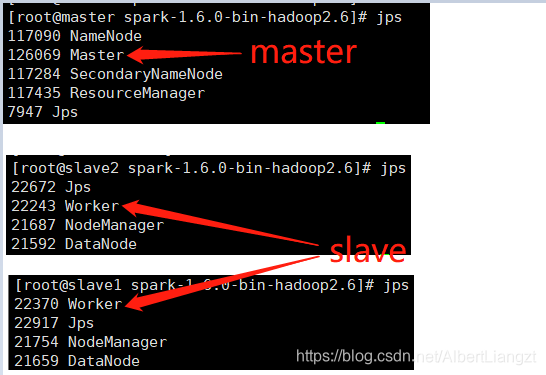
启动成功标志
-
master会有Master进程
-
slave会有Worker进程
二、验证
1.本地模式:
终端展示运行结果
./bin/run-example SparkPi 10 --master local[2]
2.集群模式 Spark Standalone:
从spark监控页面看结果
终端展示运行结果
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://master:7077 lib/spark-examples-1.6.0-hadoop2.6.0.jar 100
3.集群模式 Spark on Yarn集群上yarn-cluster模式:
从yarn集群看结果
yarn集群log运行结果
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster lib/spark-examples-1.6.0-hadoop2.6.0.jar 10














 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









