






几天前偶尔看到有人发帖子问“ 如何自动识别判断url中的中文参数是GB2312还是Utf-8编码”
也拜读了wcwtitxu使用巨牛的正则表达式检测UTF8编码的算法。
使用无数或条件的正则表达式用起来却是性能不高。
刚好曾经在项目中有类似的需求,这里把处理思路和整理后的源代码贴出来供大家参考
先聊聊原理:
UTF8的编码规则如下表
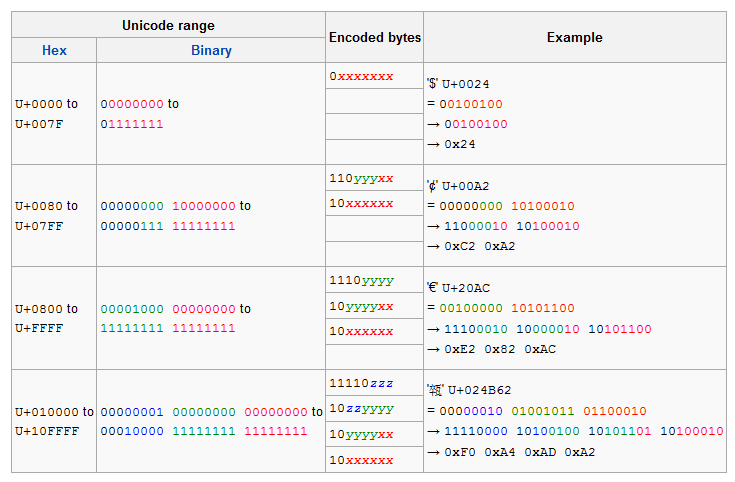
看起来很复杂,总结起来如下:
ASCII码(U+0000 - U+007F),不编码
其余编码规则为
- 第一个Byte二进制以形式为n个1紧跟个0 (n >= 2), 0后面的位数用来存储真正的字符编码,n的个数说明了这个多Byte字节组字节数(包括第一个Byte)
- 结下来会有n个以10开头的Byte,后6个bit存储真正的字符编码。
因此对整个编码byte流进行分析可以得出是否是UTF8编码的判断。
根据这个规则,我给出的C#代码如下:
再附上单元测试代码:
另:
如果是判断一个文件是否使用了UTF8编码,不一定非用这种方法,因为通常以UTF8格式保存的文件最初两个字符是BOM头,标示该文件使用了UTF8编码。
参考:















 5539
5539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









