






曾经几时,QwQ-32B(3月6日发布)以其小身板、大能量,对硬件要求较低,成为中小组织本地化部署LLM的最佳选择之一,4月29日Qwen 3的推出,可能将改变这一选择。
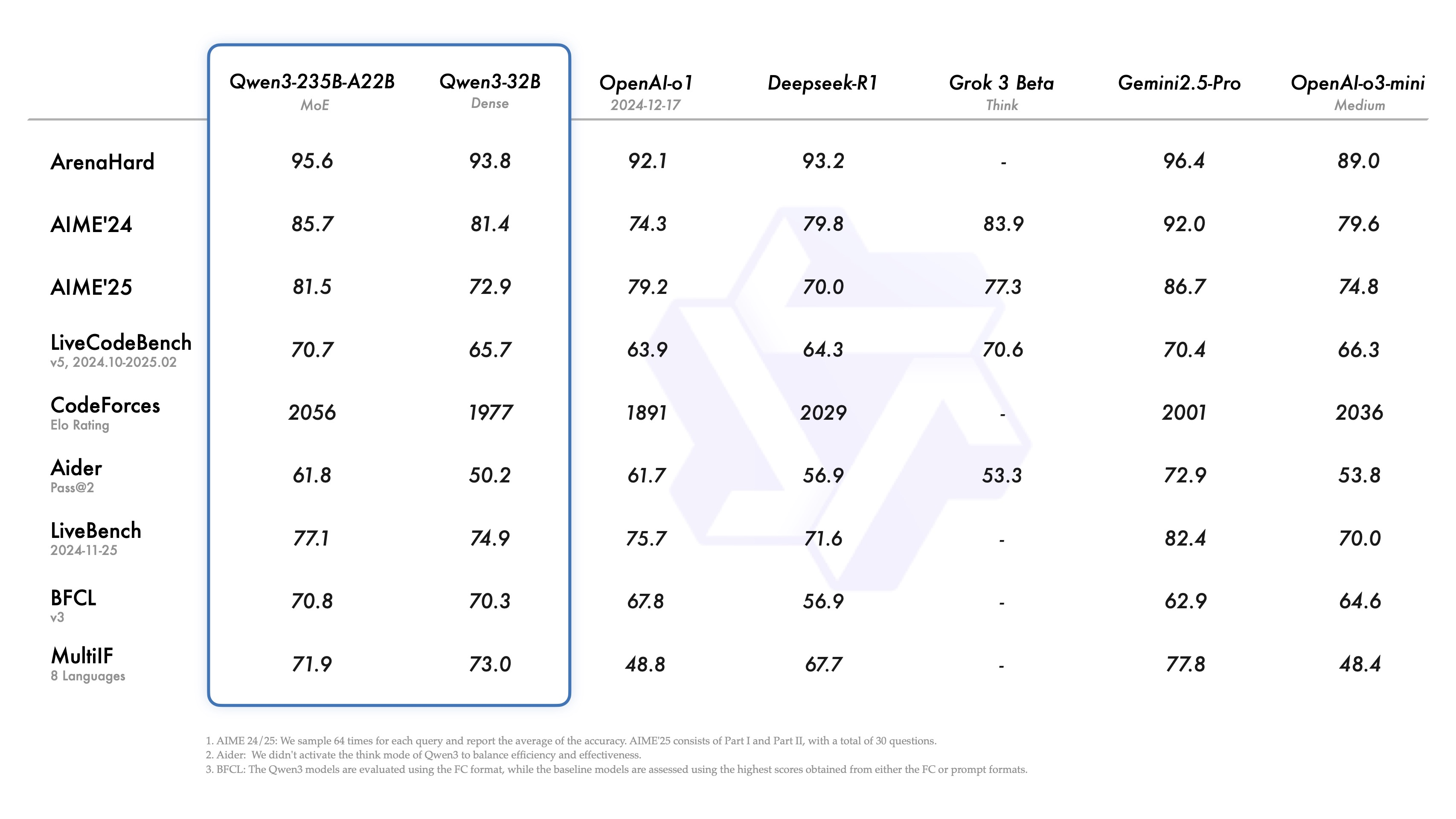
Qwen 3 是 Qwen 系列中最新一代的大型语言模型,提供一整套稠密(或密集,Dense )和混合专家 (MoE) 模型。旗舰型号 Qwen3-235B-A22B 在编码、数学、通用能力等基准测试评估方面与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等其他顶级型号相比,取得了具有竞争力的结果。
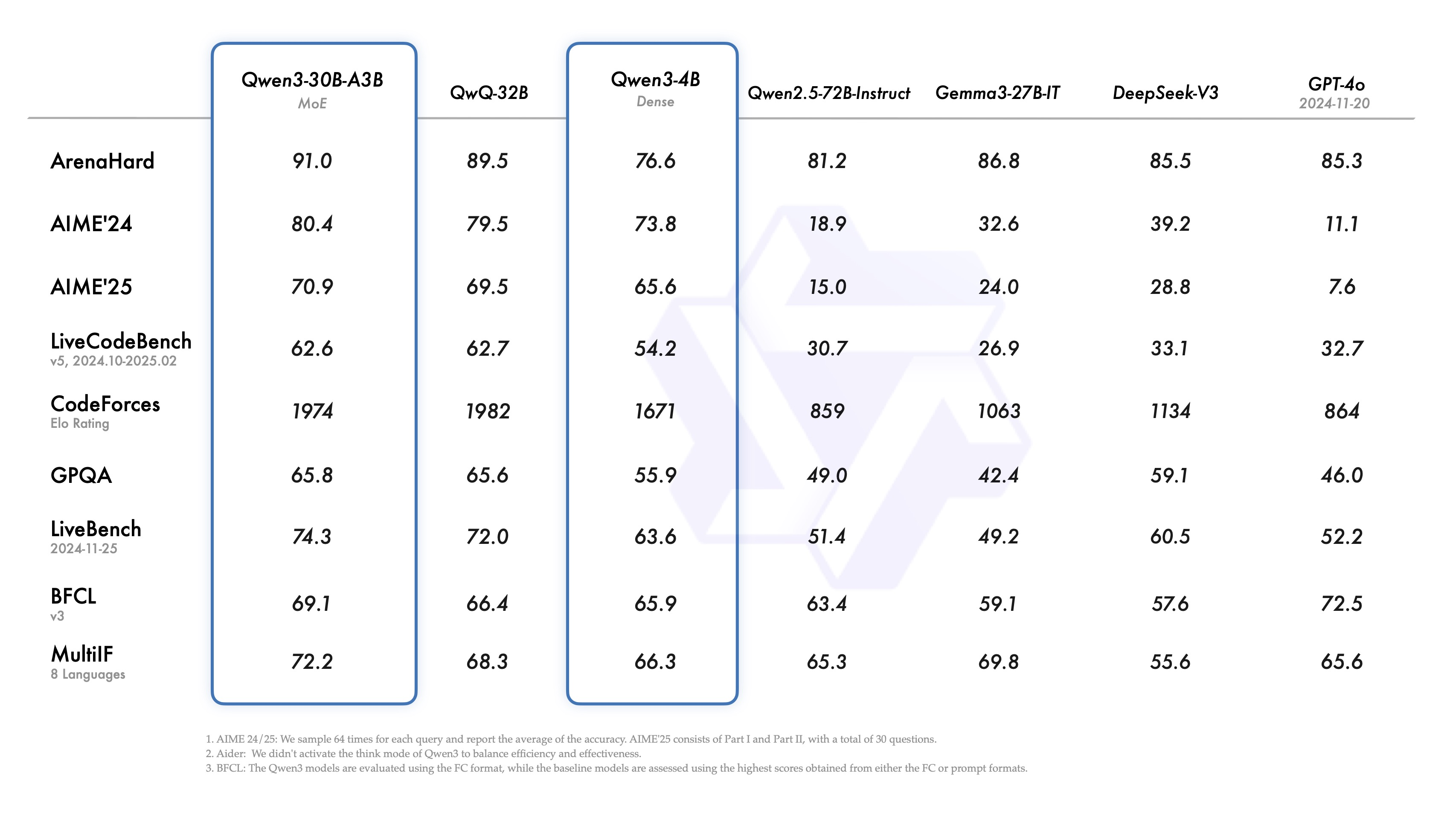
此外,小型 MoE 模型 Qwen3-30B-A3B 以 10 倍的激活参数胜过 QwQ-32B,即使是像 Qwen3-4B 这样的微型模型也可以与 Qwen2.5-72B-Struct 的性能相媲美。
-
支持在单个模型中在思维模式(用于复杂的逻辑推理、数学和编码)和非思维模式(用于高效的通用对话)之间无缝切换,确保在各种场景中实现最佳性能。
-
推理能力显著增强,超越了之前的 QwQ(思维模式)和 Qwen2.5 指导模型(非思考模式)进行数学、代码生成和常识性逻辑推理。
-
卓越的人类偏好对齐,擅长创意写作、角色扮演、多轮对话和指导遵循,以提供更自然、更吸引人和身临其境的对话体验。
-
在智能体能力方面拥有丰富的专业知识,能够在思考和非思考模式下与外部工具进行精确集成,并在基于智能体的复杂任务中实现开源模型的领先性能。
-
支持 100+ 种语言和方言,具有强大的多语言教学遵循和翻译能力。
-
与主流模型的测试成绩对比:
可以在 Qwen Chat 网页版 (chat.qwen.ai) 和通义 APP 中试用 Qwen3,通义APP里面直接将Qwen3-32B定义为“稳定高效,企业部署首选”。
 基于OpenUI构建的Qwen Chat 网页版 (chat.qwen.ai)将Qwen3-235B和Qwen3-32B分别定义为最强大的混合专家语言模型和最强大的密集模型:
基于OpenUI构建的Qwen Chat 网页版 (chat.qwen.ai)将Qwen3-235B和Qwen3-32B分别定义为最强大的混合专家语言模型和最强大的密集模型:
Qwen3 模型支持两种思考模式:
思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
这种灵活性使用户能够根据具体任务控制模型进行“思考”的程度。例如,复杂的问题可以通过扩展推理步骤来解决,而简单的问题则可以直接快速作答,无需延迟。至关重要的是,这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。如上文所述,Qwen3 展现出可扩展且平滑的性能提升,这与分配的计算推理预算直接相关。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
高级用法:
Qwen3提供了一种软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。具体来说,您可以在用户提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。
/no_think 切换后结果如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









