







想要在本地部署deepseek、qwen等模型其实很简单,快跟着小编一起部署吧
1 环境搭建
1.1下载安装环境
首先我们需要搭建一个环境ollama,下载地址如下 :Ollama

点击Download

根据自己电脑的系统选择对应版本下载即可
1.2 安装环境(window为例)
可以直接点击安装包进行安装,或者 OllamaSetup.exe /DIR="d:\some\location" 指定安装路径进行安装
2、模型安装
2.1 安装步骤如下图
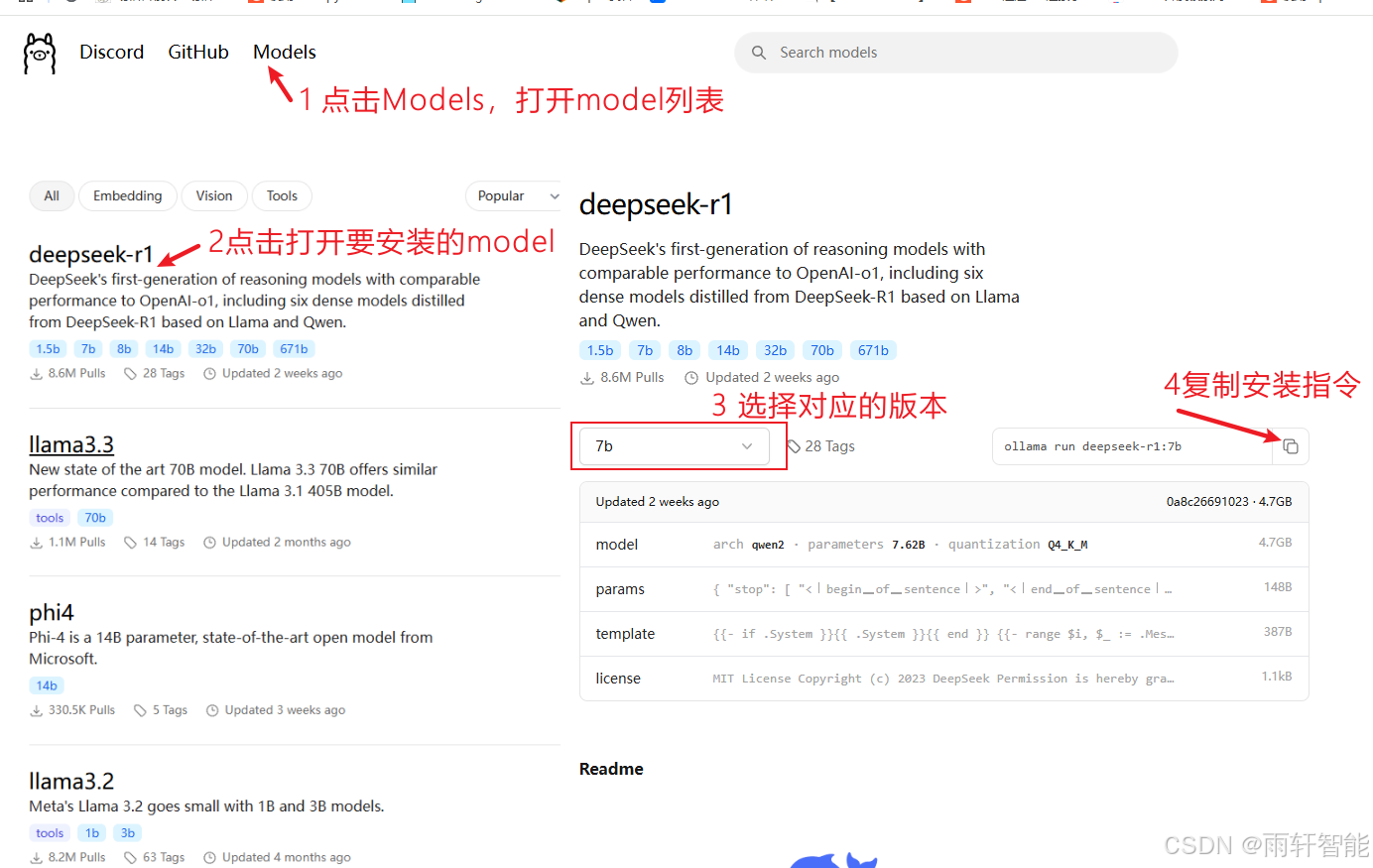
首先打开Models列表,选择要安装的模型,点击模型名称,在模型界面选择要安装的模型版本(

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











