






背景
最近需要部署模型,之前一直用的ollama部署的,考虑到这次机器能力比较强大,100+G的显存,所以选择了vllm进行部署,本文主要讲解vllm安装部署大模型,顺便也说一下ollama,希望能帮助到一些有用到的同学。
一、介绍
1. vLLM(Vectorized Large Language Model)
vLLM 是由加州大学伯克利分校开发的一个高性能大语言模型推理和服务框架。它通过 PagedAttention 技术优化了显存管理,显著提升了吞吐量和推理速度,特别适合在生产环境中部署大模型。
-
特点:
- 高吞吐量:比 Hugging Face Transformers 快 24 倍以上。
- 支持连续批处理(Continuous Batching)。
- 支持主流模型:Llama、ChatGLM、Qwen、Baichuan 等。
- 易于集成到 FastAPI、Ray 等服务中。
- 主要用于高性能推理服务部署。
-
适用场景:企业级 API 服务、高并发推理、需要低延迟和高吞吐的应用。
-
官网/项目地址:https://github.com/vllm-project/vllm
中英文文档信息:
https://docs.vllm.ai/en/latest/getting_started/quickstart.html
https://vllm.hyper.ai/docs/getting-started/quickstart/
2. Ollama
-
Ollama 是一个本地化运行大语言模型的轻量级工具,旨在让开发者在本地机器上轻松下载、运行和管理开源大模型(如 Llama3、Qwen、Mistral 等)。
-
特点:
- 极简安装,一键启动。
- 支持 macOS、Linux、Windows(预览)。
- 提供
ollama run model_name这样的命令行交互。 - 支持自定义模型(Modelfile)。
- 自带 Web UI(
http://localhost:11434)和 API 接口。 - 不需要写代码即可使用。
-
适用场景:本地开发、学习、测试、个人项目、快速原型。
-
官网地址:https://ollama.com
二、安装与部署教程
1.模型下载
可以通过HuggingFace下载,国内可以通过阿里魔搭平台下载
下载方法魔搭有三种方法下载,都可以选
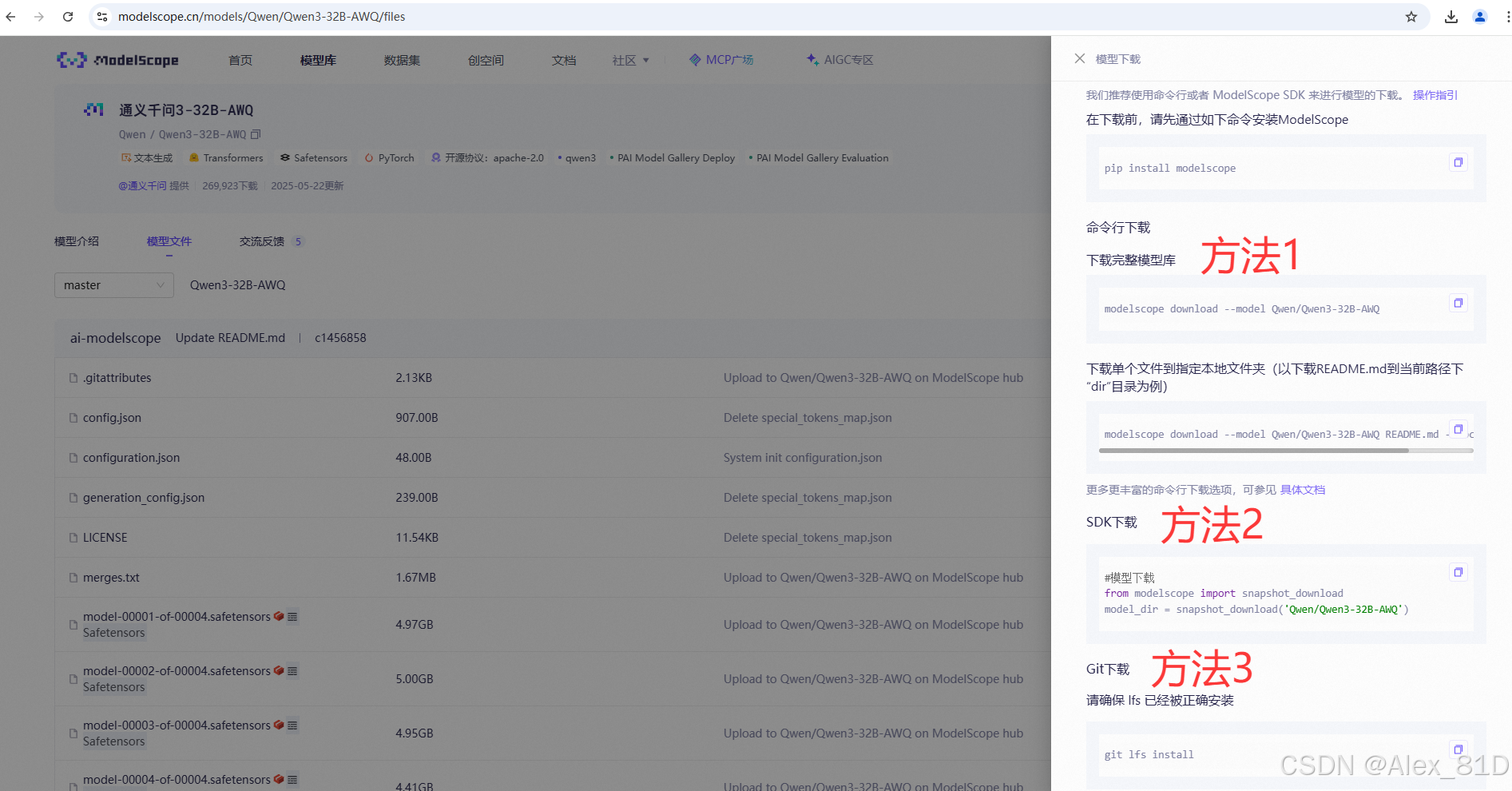
pip install modelscope
modelscope download --model Qwen/Qwen3-32B-AWQ --local_dir /data/llm/2.vLLM(推荐生产部署)
1. 环境准备
- GPU:NVIDIA GPU(推荐 24GB 显存以上,如 A100、3090、4090)
- CUDA 驱动:已安装
- Python:3.9 -- 3.12
2. 创建虚拟环境
如果是原生的python环境
创建虚拟环境
python -m venv venv
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm==0.9.2也可以使用conda来创建和管理 Python 环境,具体参考博主的另一篇文章:
https://blog.csdn.net/Alex_81D/article/details/135692506
# 创建虚拟环境
conda create -n vllm python==3.10
conda init bash
conda deactivate
conda activate vllm # 最新版发现好像有点问题
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm==0.9.2等着疯狂下载吧,这个过程需要大概一个小时左右吧,具体根据你的网速
3.启动模型服务
CUDA_VISIBLE_DEVICES=0,1 \
nohup vllm serve /data/llms/models/Qwen/Qwen3-32B-AWQ/ \
--host 0.0.0.0 --port 9999 --dtype half --trust-remote-code --served-model-name qwen3_32b_awq \
--gpu-memory-utilization 0.4 --reasoning-parser qwen3 \
--disable-log-stats --uvicorn-log-level debug \
--max-model-len 20480 \
> qwen3_14b_awq.log 2>&1 &上面的路径为你本地下载好的模型路径
参数总结表格
| 参数 | 含义 | 推荐值/说明 |
|---|---|---|
| 模型路径 | 要加载的模型位置 | 必须为 HuggingFace 格式 |
| --tensor-parallel-size N | 使用 N 张 GPU 并行 | 与 GPU 数量一致 |
| --max-model-len N | 支持的最大上下文长度 | 不要超过模型训练长度 |
| --port N | HTTP 服务监听端口 | 如 6001、8000 等 |
| --enforce-eager | 强制使用 eager 模式 | 用于调试或兼容性 |
| --uvicorn-log-level | 日志等级 | debug, info 等 |
| --gpu-memory-utilization | 显存使用率 | 推荐 0.8~0.95 |
| --served-model-name | 对外显示的模型名 | 用于 /v1/models 接口 |
主要参数设置
以下是启动 vLLM 服务器时常用的一些参数:
--model:要使用的 HuggingFace 模型名称或路径(默认值:facebook/opt-125m)。--host和--port:指定服务器地址和端口。--dtype:模型权重和激活的精度类型。可能的值:auto、half、float16、bfloat16、float、float32。默认值:auto。--tokenizer:要使用的 HuggingFace 标记器名称或路径。如果未指定,默认使用模型名称或路径。--max-num-seqs:每次迭代的最大序列数。--max-model-len:模型的上下文长度,默认值自动从模型配置中获取。--tensor-parallel-size、-tp:张量并行副本数量(对于 GPU)。默认值:1。--distributed-executor-backend=ray:指定分布式服务的后端,可能的值:ray、mp。默认值:ray(当使用超过一个 GPU 时,自动设置为ray)。
python3 -m vllm.entrypoints.openai.api_server --model /input1/Qwen3-0.6B/ --host 0.0.0.0 --port 8080 --dtype auto --max-num-seqs 32 --max-model-len 4096 --tensor-parallel-size 1 --trust-remote-code4.支持的功能
- 多 GPU 并行(
--tensor-parallel-size 2) - 批处理大小控制
- 异步推理
- Prometheus 监控
- 与 LangChain、LlamaIndex 集成
https://zhuanlan.zhihu.com/p/1928120910411441449
https://kkgithub.com/QwenLM/Qwen-Agent
https://blog.csdn.net/qq_40902709/article/details/147086232
https://blog.csdn.net/hbkybkzw/article/details/146485866
3.Ollama(推荐新手)
1.安装 Ollama
pip install modelscope
# 编写shell文件 ollama-modelscope-install.sh
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux
# 运行ollama安装脚本, 默认/usr/share/ollama
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh# 查看ollama是否已经安装完毕
ollama -v 2.配置
## 指定ollama模型存储位置
OLLAMA_MODELS=/your-model-path
## 指定ollama启动端口。
OLLAMA_HOST=0.0.0.0:xxxx
## 启动ollama服务
ollama serve3.部署Deepseek-r1:14b
首次部署时需要等待ollama下载模型文件
## 部署Deepseek-r1:14b,首次部署时需要等待ollama下载模型文件。
ollama run deepseek-r1:14b
*若提示“could not connect to ollama app”,则需要在上面命令前加上 OLLAMA_HOST=0.0.0.0:xxxx *4.vLLM vs Ollama 对比
| 特性 | vLLM | Ollama |
|---|---|---|
| 安装难度 | 中等(需 Python、CUDA) | 极简(一键安装) |
| 性能 | ⭐⭐⭐⭐⭐(高吞吐) | ⭐⭐⭐(适合单机) |
| 易用性 | 需编码/命令行 | 命令行 + Web UI |
| 支持模型 | HuggingFace 所有模型 | Ollama 库中的模型 |
| 本地运行 | ✅ | ✅ |
| 生产部署 | ✅✅✅(推荐) | ✅(轻量级) |
| API 兼容 OpenAI | ✅ | ✅(部分兼容) |
| 自定义模型 | ✅(通过 HuggingFace或者魔搭) | ✅(通过 Modelfile) |
| 显存优化 | PagedAttention(强) | 一般 |
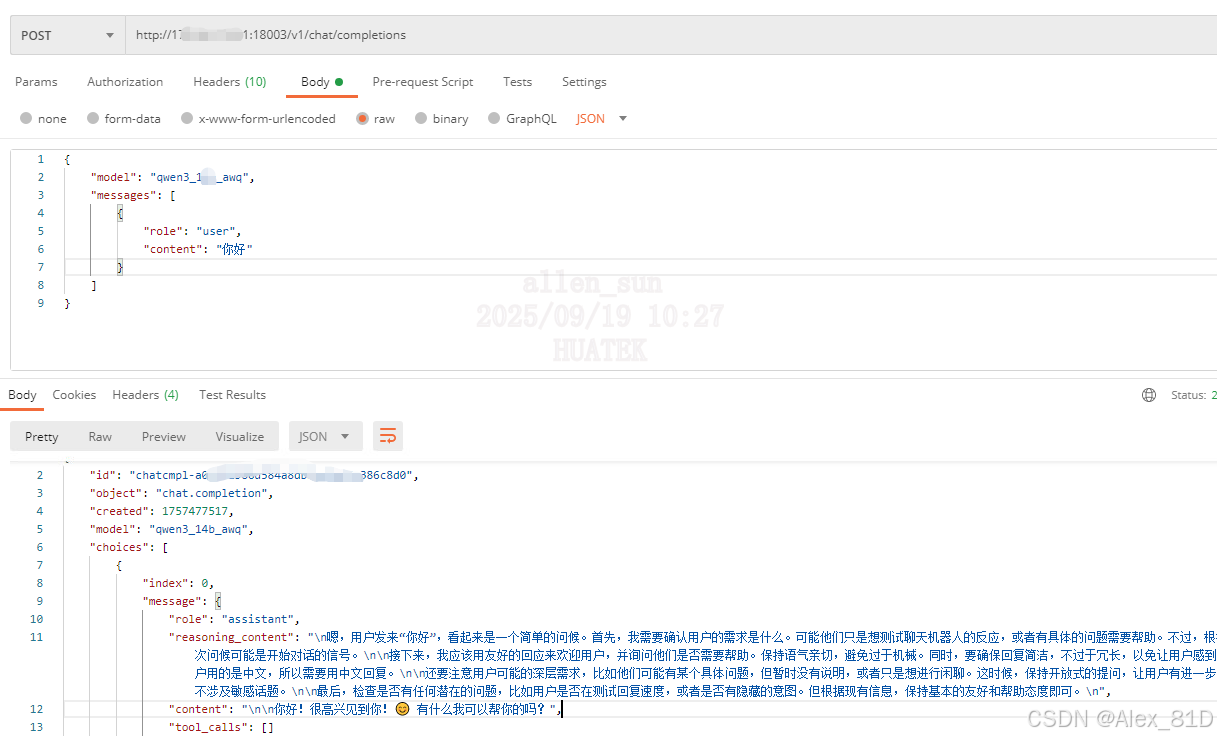
5.API调用
url: http://192.168.0.0:8088/v1/chat/completions
三、遇到的问题以及解决方法
1.ValueError: ‘llava‘ is already used by a Transformers config, pick another name.
line 728, in register raise ValueError(f"'{key}' is already used by a Transformers config, pick another name.") ValueError: 'llava' is already used by a Transformers config, pick another name.
解决方法:
对transformers进行降级,降级到4.30.1或者4.30.0。
pip install -U transformers==4.51.3
https://blog.csdn.net/jacke121/article/details/143879099
2.版本不兼容:发现有些模型在新版vllm上启动不起来,需要更新版本,这个是我目前使用较为稳定的版本 0.9.2,更新vllm版本
pip show vllm | grep Version
pip install -U vllm==0.9.2
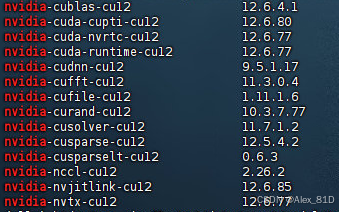
对应的cuda版本如下:12.6.x
3.GPU不足
4.gpu-memory-utilization、--tensor-parallel-size
gpu-memory-utilization 0.7–gpu-memory-utilization:建议0.7~0.9,过高可能导致OOM 。
–tensor-parallel-size:必须与GPU数量一致,否则会报错ValueError: Total number of attention heads must be divisible by tensor parallel size 。


















 3629
3629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











