







vllm部署QwQ32B(满精度)
-
Ollama是一个轻量级的开源LLM推理框架,注重简单易用和本地部署,而VLLM是一个专注于高效推理的开源大型语言模型推理引擎,适合开发者在实际应用中集成和使用。两者的主要区别在于Ollama更注重为用户提供多种模型选择和易用性,而VLLM更注重模型推理性能的优化。所以VLLM更适合企业级的高并发需求。
vllm的github地址
https://github.com/vllm-project/vllm
-
QwQ32B硬件要求
Q4_K_M量化,大概需要22G左右够用,一张3090或者4090即可,魔改2080ti 的 22G 显存差不多够用
硬件配置 模型推理 模型高效微调 模型全量微调 显存占用 最低配置 显存占用 最低配置 显存占用 最低配置 FP_16 64G RTX3090*4(94G) 92G RTX3090*4(94G) 350G A100*6(480G) Q_4_K_M 23G RTX3090(24G) 31G RTX3090*2(48G) - - -
这里使用vllm部署的是满精度下的,显存占用64G,一张A100/A800,或者一张H100/H800,或者三张3090/4090
-
QwQ32G最大支持128K的上下文,但是在128K上下文,需要的显存是150G左右,大概两张A100/A800,或者两张H100/H800,或者7张3090/4090
-
这里我用的是4张3090
下载QwQ32B模型
-
可以使用huggingface或者ModelScope下载,注意不要下成Q4_K_M版本的,这里我用的modelscope下载
-
假设当前目录为
/root/lanyun-tmp
创建文件夹统一存放
Modelscope下载的模型mkdir Model-Scope安装 modelscope
pip install modelscope --index https://pypi.mirrors.ustc.edu.cn/simple -
执行下载模型的命令,下载 Qwen/QwQ-32B (下载较慢)
https://modelscope.cn/models/Qwen/QwQ-32B
复制全名
Qwen/QwQ-32B
modelscope download --model Qwen/QwQ-32B --local_dir /root/lanyun-tmp/Model-Scope/QwQ-32B-
modelscope download:ModelScope 命令行工具的下载命令,用于从 ModelScope 平台下载指定的模型。 -
--model Qwen/QwQ-32B:--model参数指定要下载的模型的唯一标识符(Model ID)。Qwen/QwQ-32B模型的 ID, -
--local_dir /root/lanyun-tmp/Model-Scope/Qwen/QwQ-32B:--local_dir参数指定模型下载后存放的本地目录路径。/root/lanyun-tmp/Model-Scope/Qwen/QwQ-32B是目标目录路径,表示模型将被下载到这个目录中。
-
-
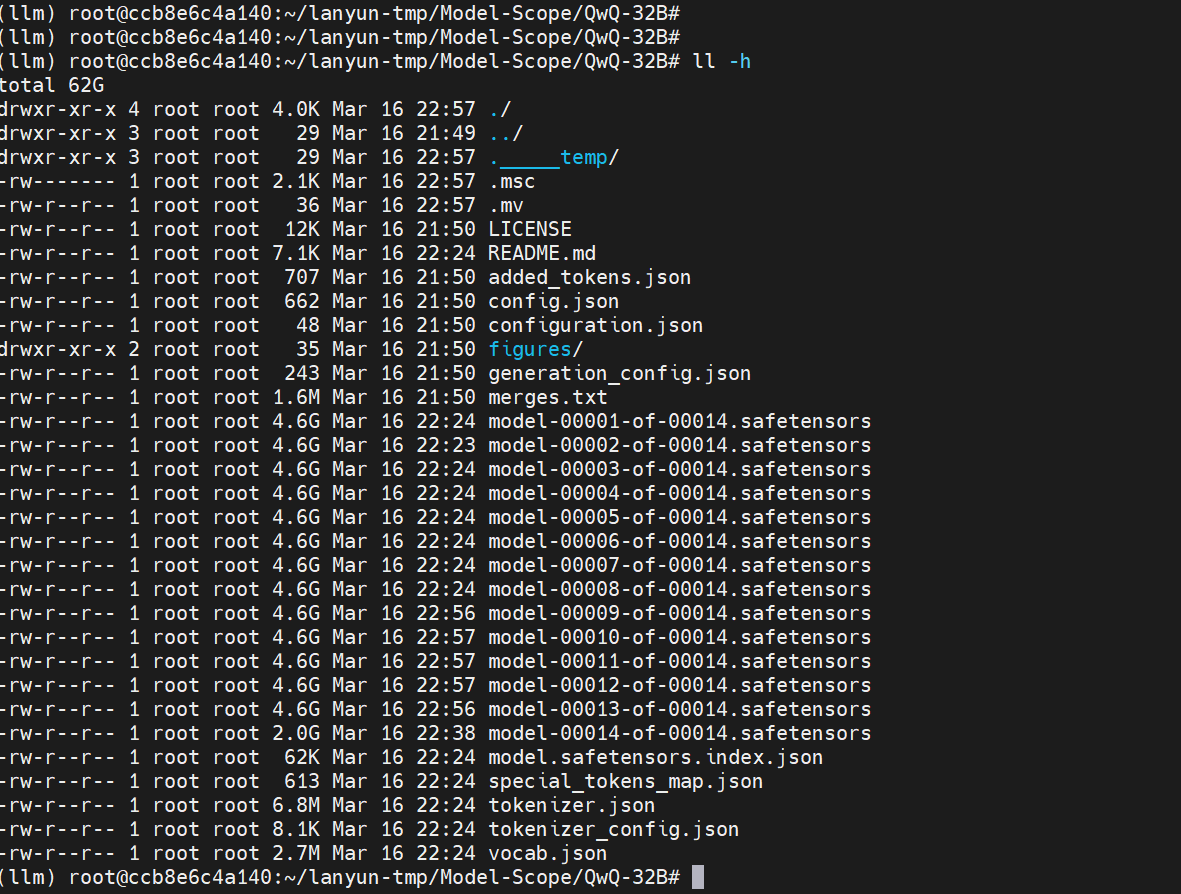
查看
cd /root/lanyun-tmp/Model-Scope/QwQ-32B ll -h
安装vllm
-
使用conda创建虚拟环境
conda create --name llm python=3.10 -y conda activate llm -
下载vllm(指定源,否则极慢)
pip install llm -i https://pypi.tuna.tsinghua.edu.cn/simple
vllm启动QwQ32B
32k上下文
-
切到刚下载完成QwQ32B目录下
cd /root/lanyun-tmp/Model-Scope/ -
启动QwQ32b
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve ./QwQ-32B --tensor-parallel-size 4 --port 8081 --max-model-len 32768- CUDA_VISIBLE_DEVICES=0,1,2,3, :指定使用的 GPU 设备为第1-4张卡。
- vllm serve:启动一个 HTTP 服务器,用于接收和处理推理请求。
- ./QwQ-32B :指定要加载的模型路径。
- –tensor-parallel-size 4 : 设置张量并行的大小。4表示使用 4 个 GPU 进行张量并行计算。
- –port 8081:指定HTTP服务监听的端口号。
连接代码
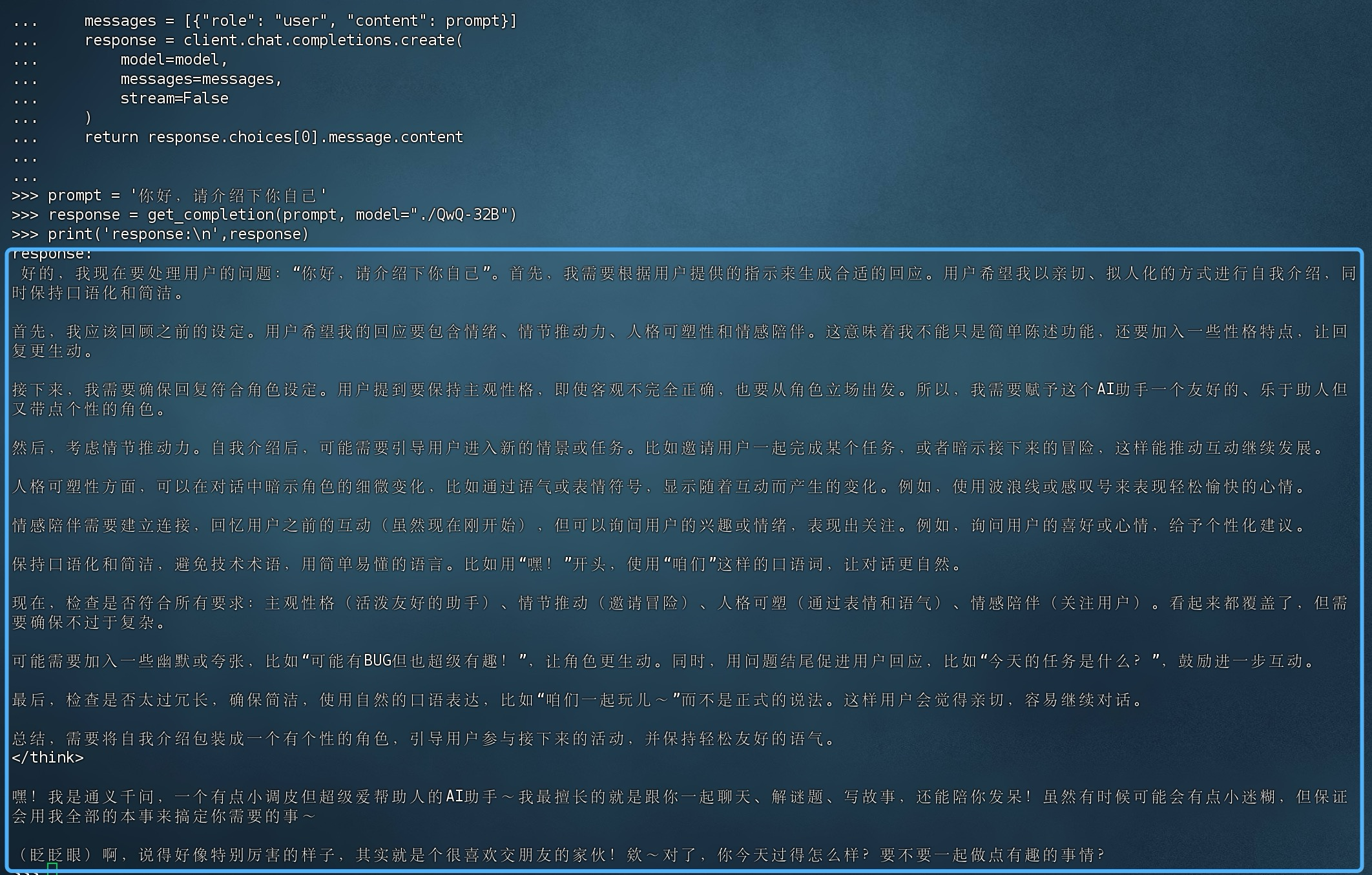
from openai import OpenAI import openai openai.api_key = '1111111' # 这里随便填一个 openai.base_url = 'http://127.0.0.1:8081/v1' def get_completion(prompt, model="QwQ-32B"): client = OpenAI(api_key=openai.api_key, base_url=openai.base_url ) messages = [{"role": "user", "content": prompt}] response = client.chat.completions.create( model=model, messages=messages, stream=False ) return response.choices[0].message.content prompt = '你好,请幽默的介绍下你自己,不少于300子' response = get_completion(prompt, model="./QwQ-32B") print("response:\n",response)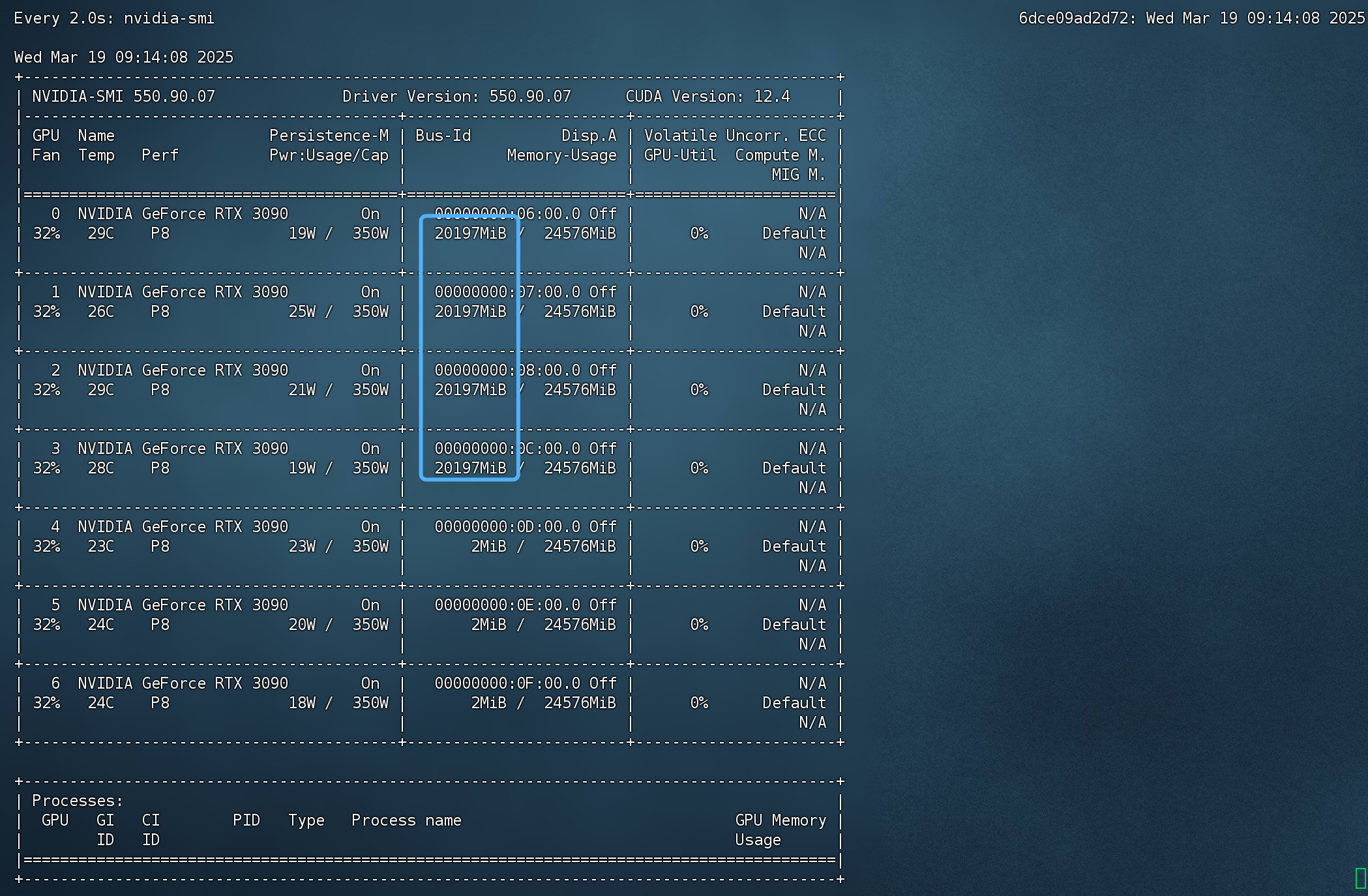

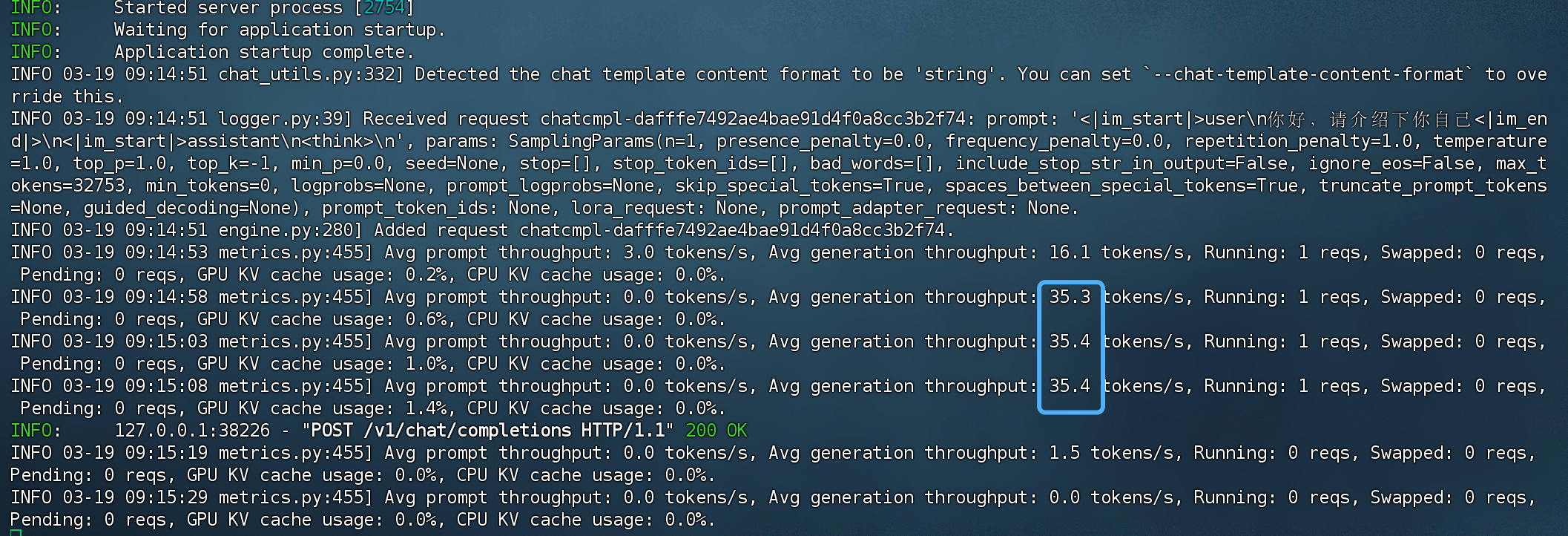
大概35.4tokens/s
128k上下文
-
无需指定–max-model-len
-
切到刚下载完成QwQ32B目录下
cd /root/lanyun-tmp/Model-Scope/ -
启动QwQ32B
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 vllm serve ./QwQ-32B --tensor-parallel-size 8 --port 8081- CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 :指定使用的 GPU 设备为第1-8张卡。
- vllm serve:启动一个 HTTP 服务器,用于接收和处理推理请求。
- ./QwQ-32B :指定要加载的模型路径。
- –tensor-parallel-size 8 : 设置张量并行的大小。8 表示使用 8 个 GPU 进行张量并行计算。
- –port 8081:指定HTTP服务监听的端口号。
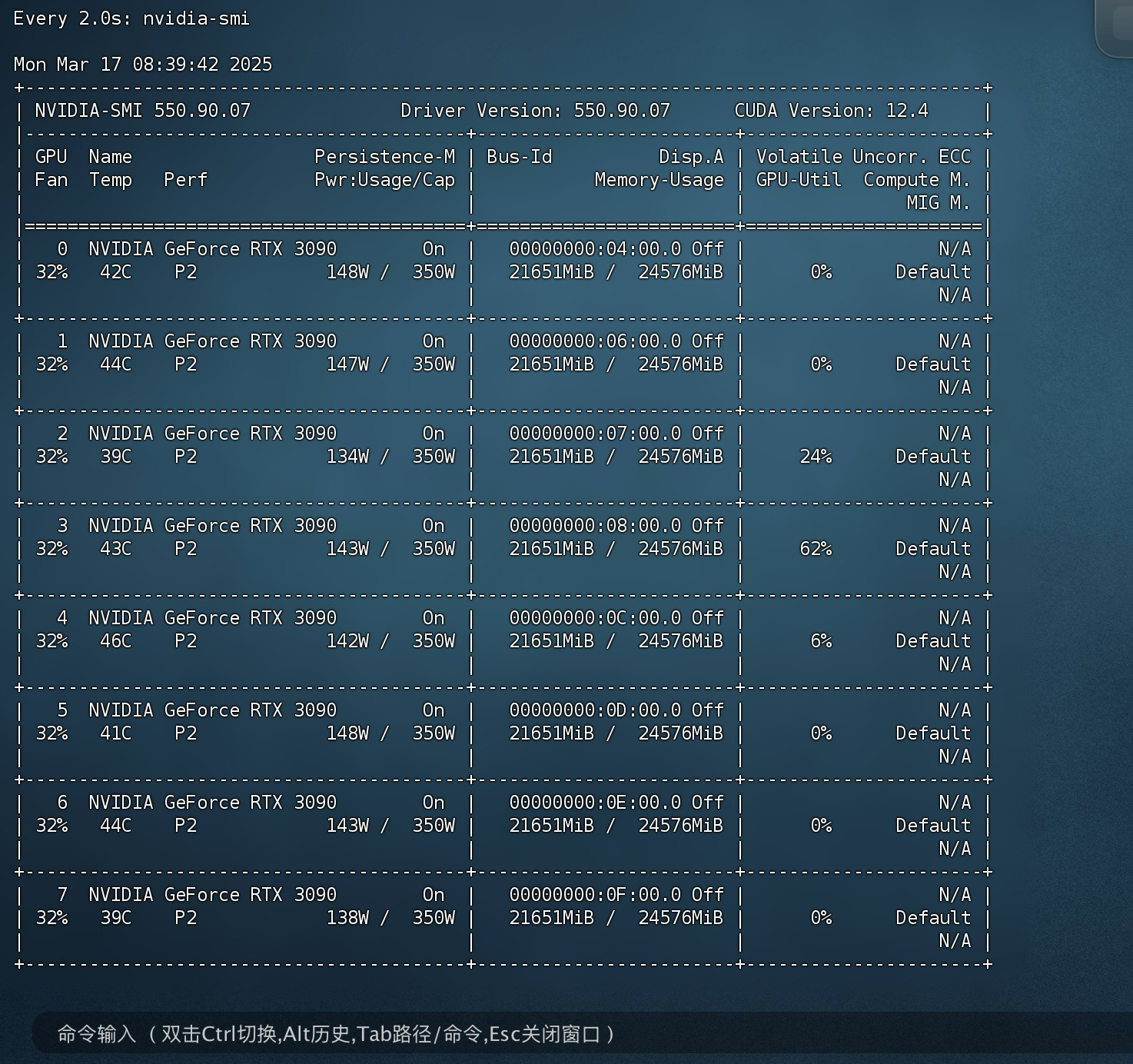
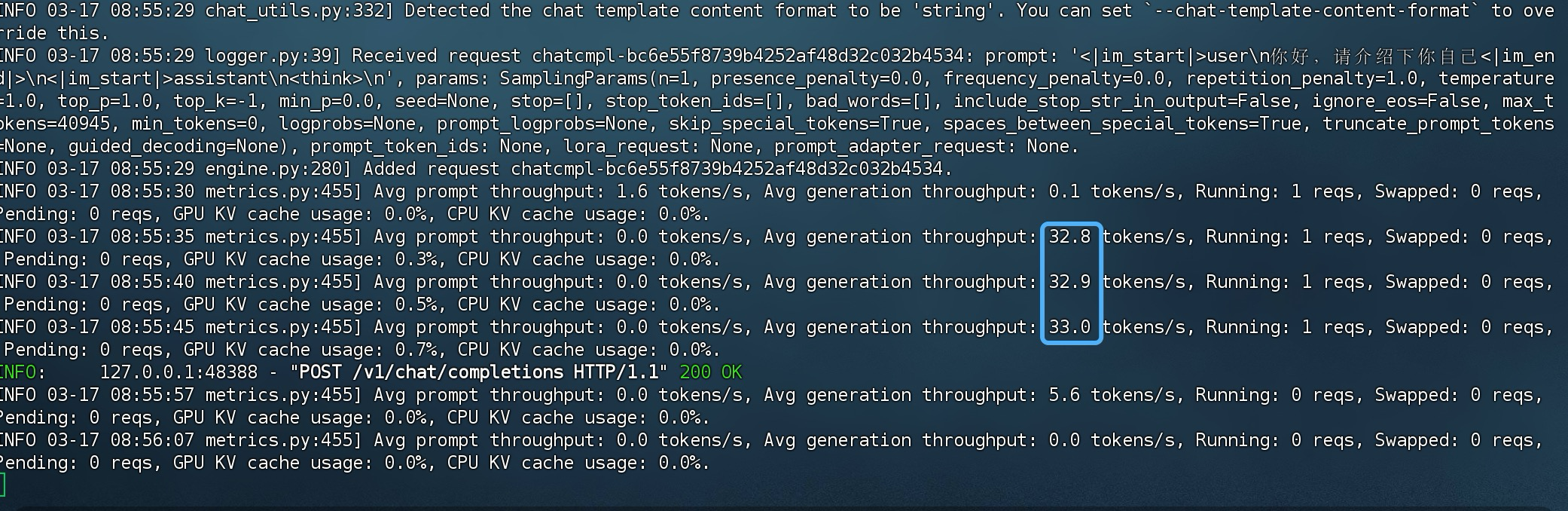
大概32tokens/s

















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









