







1、前言
在写此文之前,我想大家思考一个问题,我们为什么用缓存这个技术?
很多实战多年的老炮儿对这个问题很不屑,但是对于大多数新人开发来说,这个问题却很值得思考,你面试前,关于缓存,关于中间件,背了很多,学了很多,但是你真的考虑过,为什么要用到缓存技术吗?
我们先看一个关键词 : 数据库调优
关于数据库优化的流程和方案,你知道多少?我们先整理思路:
2、数据库调优的措施
2.1 调优的目标?
- 尽可能的 节省系统资源,以便系统提供更大负荷的服务 ——吞吐量更大。
- 合理的结构设计和参数调整,以提高用户操作的 响应速度 ——响应速度更快。
- 减少系统瓶颈,提高数据库的整体性能。
不过随着用户量的不断增加,以及应用程序复杂度的提升,我们很难用“更快”去定义数据库调优的目标,因为用户在不同时间段访问服务器遇到的瓶颈不同,比如双十一促销的时候会带来大规模的 并发访问,还有用户在进行不同业务操作的时候,数据库的 事务处理和 SQL查询 都会有所不同。因此我们还需要更加精细的定位,去确定调优的目标。
2.2 如何定位调优的问题
如何确定呢?一般情况下,有如下几种方式:
- 用户的反馈(主要)
- 日志分析(主要)
- 服务器资源使用监控
- 数据库内部状况监控
- 其它
除了活动会话监控以外,我们也可以对 事务 、 锁等待 等进行监控,这些都可以帮助我们对数据库的运 行状态有更全面的认识。
2.3 调优的维度和步骤
很多新人 在面对数据库调优这个概念时,还把它当作是一个知识点,一个技术去学习。其实,一个程序员到了一定程度,始终难以进步的原因,并不是不学习了,而是学习的视角错了,像数据库调优这个问题,你不可以再用一个普通程序员的视角来学习,思考。
它不是某个模块,某个需求,某个逻辑,而是要站在宏观的角度,来看待整个业务,这些业务可以划分多个不同而又相交的模块,在此之间,我们要权衡整体的 性能,可用度,等一系列指标。
此时你的身份,要转换成宏观调控者——将军。
数据库调优流程图
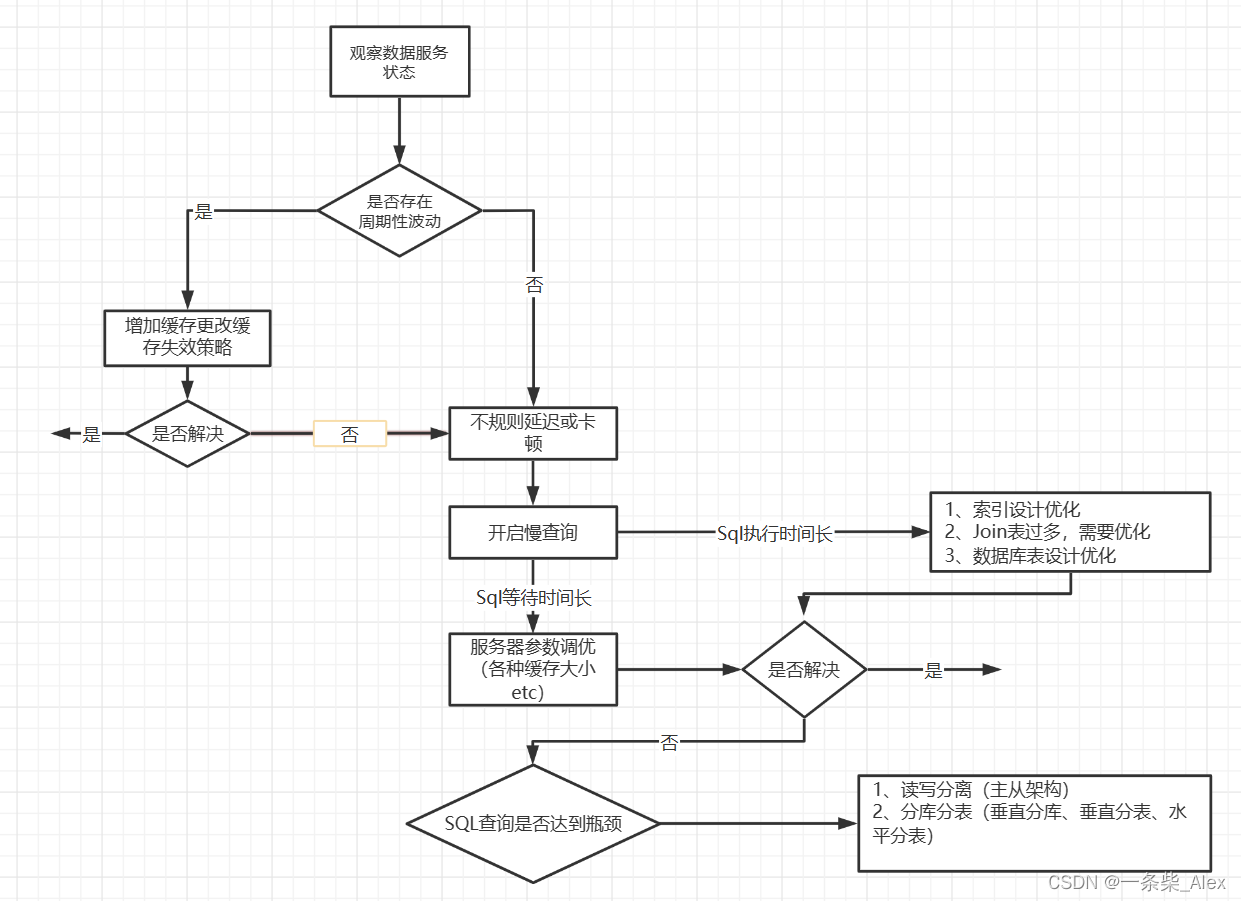
第一步、选择合适的DBMS
根据不同业务场景,选择不同的DBMS。
不同的DBMS 适用于不同的业务场景,业务强度,甚至数据库引擎的选择都是值得研究的事情,另外NoSQL 的存在,也进一步可以弥补业务功能的不足。
第二步、优化表的设计
- 表的结构尽量遵循第三范式原则,这样可以让数据结构更加清晰规范,减少冗余字段,同时也减少更新,插入删除时发生的异常情况。
- 如果 查询应用较多,尤其是多表联查的情况较多,可以采用反范式化 进行优化。反范式化利用的 空间换时间的思想,通过增加冗余字段,提高查询效率。
- 3表字段的数据类型 选择,关系到了查询效率的高低以及存储空间的大小。一般来说,如果字段可以采用数值类型就不要采用字符类型;字符长度要尽可能设计得短一些。针对字符类型来说,当确定字符长度固定时就可以采用 CHAR 类型;当长度不固定时,通常采用 VARCHAR 类型。
数据表的结构设计很基础,也很关键。好的表结构可以在业务发展和用户量增加的情况下依然发挥作用,不好的表结构设计会让数据表变得非常臃肿,查询效率也会降低。
第三步、优化逻辑查询
即SQL语法上的优化,就是对一些性能不佳的SQL语句进行等价变换。
第四步、优化物理查询
最常用的就是 对特殊字段建立索引。
第5步:使用 Redis 或 Memcached 作为缓存
第6步:库级优化
库级优化是站在数据库的维度上进行的优化策略,比如控制一个库中的数据表数量。另外,单一的数据库总会遇到各种限制,不如取长补短,利用"外援”的方式。通过 主从架构 优化我们的读写策略,通过对数据库进行垂直或者水平切分,突破单一数据库或数据表的访问限制,提升查询的性能
1、读写分离
如果读和写的业务量都很大,并且它们都在同一个数据库服务器中进行操作,那么数据库的性能就会出现瓶颈这时为了提升系统的性能,优化用户体验,我们可以采用 读写分离 的方式降低主数据库的负载,比如用主数据库(master) 完成写操作,用从数据库 (slave) 完成读操作。


2、数据分片
对 数据库分库分表。当数据量级达到千万级以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力。如果你使用的是 MySQL,就可以使用 MySQL 自带的分区表功能,当然你也可以考虑自己做 垂直拆分(分库)、水平拆分 (分表)、垂直+水平拆分 (分库分表)。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









