







一、Java I/O的基本架构
Java的I/O操作类在java.io包下,大概有80多个类,这些类可以分成以下4组:
▶ 基于字节操作的I/O接口:InputStream和OutputStream
▶ 基于字符操作的I/O接口:Reader和Writer
▶ 基于磁盘操作的I/O接口:File
▶ 基于网络操作的I/O接口:Socket
前两组主要是传输数据的数据格式不同,后两组主要是传输数据的传输方式不同,数据格式和传输方式都是影响I/O操作传输效率的关键因素。
二、磁盘I/O的工作机制
1、访问文件的几种方式
① 标准方式的访问
读取的时候,当应用程序调用read()接口时,操作系统检查在内核的高速缓存中有没有需要的数据,如果已经有缓存了,就直接从缓存中返回,如果没有,则从磁盘中读取,然后缓存在操作系统的缓存中。
写入的时候,用户的应用程序调用write()接口将数据从用户地址空间复制到内核地址空间的缓存中,这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统来决定,除非显式的调用了sync同步命令。
② 直接I/O的方式
所谓直接I/O就是应用程序直接访问磁盘数据,而不经过操作系统的内核数据缓存区,这样做的目的就是减少一次从内核缓存区到应用程序缓存的数据复制,但是直接I/O也有负面影响,如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘进行加载,这种直接加载会非常缓慢。通常直接I/O和异步I/O结合使用,会有比较好的性能。
③ 同步访问文件的方式
它是指数据的读取和写入都是同步操作的,它与标准访问文件方式不同的是,只有当数据成功写入到磁盘时才返回给应用程序成功的标志,这种访问方式的性能比较差,只有对数据安全性要求比较高的场景中才会使用。通常这种操作方式的硬件都是定制的。
④ 异步访问文件的方式
这种方式是当数据的线程发出请求之后,线程会接着去处理其他的事情,而不是阻塞等待,当请求的数据返回后继续处理下面的操作,这种方式可以明显的提高应用程序的效率,但是不会改变访问文件的效率。
⑤ 内存映射的方式
它是指操作系统将内存中的某一块区域与磁盘中的文件关联起来,当要访问内存中的一段数据时,转换为访问文件的某一段数据,这种方式的目的同样是减少数据从内核空间缓存到用户空间缓存的数据复制操作,因为这两个空间的数据是共享的。
2、Java访问磁盘文件
3、Java的序列化技术
import java.io.*;
public class SerializeTest implements Serializable {
private static final long serialVersionUID = 1L;
private int num = 1390;
public static void main(String[] args) throws Exception {
//序列化
FileOutputStream fos = new FileOutputStream("E:\\Learn\\Test\\深入JavaWeb技术内幕\\JavaIOTest\\SerializeTest.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
SerializeTest st = new SerializeTest();
oos.writeObject(st);
oos.flush();
oos.close();
//反序列化
FileInputStream fis = new FileInputStream("E:\\Learn\\Test\\深入JavaWeb技术内幕\\JavaIOTest\\SerializeTest.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
SerializeTest st1 = (SerializeTest) ois.readObject();
System.out.println(st1.num);
ois.close();
}
}
当Java的序列化遇到一些复杂情况时的说明:
① 当父类继承Serializable接口时,所有的子类都可以被序列化;
② 子类实现了Serializable接口,父类没有实现,父类中的属性不能被序列化(不报错,但数据会丢失),子类中的属性仍能正确序列化;
③ 如果序列化的属性是对象,则这个对象也必须实现Serizliazble接口,否则会报错;
④ 在反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错;
⑤ 在反序列化时,如果serialVersionUID被修改,则反序列化时会失败。
三、网络I/O的工作机制
1、TCP状态转化图
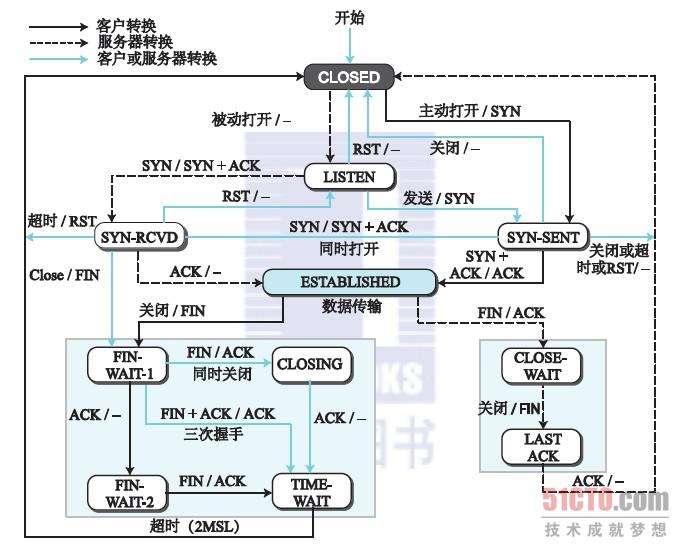
2、TCP的三次握手
四次握手的过程如下:
① A发送同步信号SYN(Synchronization)+A的ISN给B;
② B确认收到A的同步信号,并记录A的ISN到本地,命名为B的ACK(Acknowledgement);
③ B发送同步信号SYN+B的ISN给A;
④ A确认到B的同步信号,并记录B的ISN到本地,命名为A的ACK。
很显然2和3的这两个步骤可以合并,只需要三次握手,可以提高连接的速度与效率。
补充:
① 第一个包,即A发给B的SYN中途丢失,没有到达B
A为周期性超时重传,直到收到B的确认;
② 第二个包,即B发送给A的SYN+ACK中途丢失,没有到达A
B会周期性超时重传,直到收到A的确认;
③ 第三个包,即A发送给B的ACK中途丢失,没有到达B
A发完ACK单方面认为TCP为Established状态,而B显然认为TCP为Active状态
a.假定此时双方都没有数据发送,B会周期性超时重传,直到收到A的确认,收到之后B的TCP连接状态也为Established,此时双向可以发包;
b.假定此时A有数据发送,B收到A的数据+ACK,自然会切换到Established状态,并接受A的数据;
c.假定此时B有数据发送,但现在发送不了,B会周期性的超时重传SYN+ACK,直到收到A的确认才可以发送数据。
参考于:https://www.zhihu.com/question/24853633
3、影响网络传输的因素
将一份数据从一个地方正确的传输到另外一个地方所需要的时间就被称之为响应时间,影响响应时间的因素有如下几点:
① 网络带宽:它是指一条物理链路在1s内能够传输的最大比特数(注意是比特不是字节,一个字节8bit);
② 传输距离:也就是数据在光纤中要走的距离,虽然光的转播速度很快,但由于数据在光纤中的移动并不是走直线的,会有一个折射率,大概是光的2/3,这个消耗的时间也就是通常我们所说的传输延时;
③ TCP拥塞控制:TCP传输是一个“停-等-停-等”的协议,传输方和接受方的步调要一致,要达到步调一致就要通过拥塞控制来调节,TCP在传输时会设定一个“窗口”,这个“窗口”的大小是由带宽和RTT(响应时间)来决定的,计算的公式是带宽(b/s)*RTT(s),通过这个值可以得出理论上最优的TCP缓冲区的大小。
4、Java Socket的工作机制
5、建立通信链路
客户端示例:
import java.net.Socket;
public class ApplicationATest {
public static void main(String[] args) throws Exception {
//客户端
System.out.println("开始创建客户端Socket实例......");
Socket s1=new Socket("192.168.188.1",9001);//IP地址是你自己主机的地址,dos下输入ipconfig查看,端口号与服务端保持一致
if(s1.isConnected()){
System.out.println("成功与服务端建立远程连接");
System.out.println("服务端的远程地址是:"+s1.getRemoteSocketAddress());
s1.close();
System.out.println("连接关闭");
}
}
}
服务端示例:
import java.net.ServerSocket;
import java.net.Socket;
public class ApplicationBTest {
public static void main(String[] args) throws Exception {
//服务端
System.out.println("开始创建服务端Socket实例......");
ServerSocket serverSocket = new ServerSocket(9001);//端口号自定义
System.out.println("开始进入阻塞状态,正在等待客户端发起请求......");
Socket s2 = serverSocket.accept();
if (s2.isConnected()) {
System.out.println("成功与客户端建立连接");
System.out.println("客户端的远程地址是:" + s2.getRemoteSocketAddress());
s2.close();
System.out.println("连接关闭");
}
}
}
6、数据传输
四、NIO的工作方式
可参考链接: 攻破JAVA NIO技术壁垒
1、NIO的工作机制
public void selector() throws IOException {
ByteBuffer buffer = ByteBuffer.allocate(1024);
Selector selector = Selector.open();//调用Selector的静态工厂创建一个选择器
ServerSocketChannel ssc = ServerSocketChannel.open();//创建一个服务端的Channel
ssc.configureBlocking(false);//设置为非阻塞方式
ssc.socket().bind(new InetSocketAddress(8080));//将服务端的Channel绑定到一个Socket对象
ssc.register(selector, SelectionKey.OP_ACCEPT);//注册监听的事件,将Channel注册到选择器上
while (true) {//无限循环,保持监听状态
Set<SelectionKey> keys = selector.keys();//取得所有的key集合
Iterator<SelectionKey> iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = (SelectionKey) iterator.next();
if ((key.readyOps() & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT) {
ServerSocketChannel ssc2 = (ServerSocketChannel) key.channel();//获取这个key所代表的通信信道对象
SocketChannel sc = ssc2.accept();//服务端接受请求
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
iterator.remove();
} else if ((key.readyOps() & SelectionKey.OP_READ) == SelectionKey.OP_READ) {
SocketChannel sc = (SocketChannel) key.channel();
while (true) {
buffer.clear();//将缓冲区的索引状态重置为初始位置
int a = sc.read(buffer);//读取数据到buffer
if (a <= 0) {//数据读取完毕,跳出循环
break;
}
//将缓存字节数组的指针设置为数组的开始序列即数组下标0,这样就可以从buffer开头,
//对该buffer进行读取了,最多只能读取之前写入的数据长度,而不是整个缓冲的容量大小,
//如果没有这个方法,就是从buffer最后开始读取,读出来的都是byte=0时候的字符。
buffer.flip();
}
iterator.remove();
}
}
}
}在上面这段程序中,是将Server端的监听连接请求的事件和处理请求的事件放在一个线程中,但是在应用中,我们通常会把它们放在两个线程中,一个线程专门负责监听客户端的连接请求,而且是以阻塞方式执行的;另外一个线程专门负责处理请求,这个专门负责处理请求的线程才会真正采用NIO的方式,比如Web服务器Tomcat和Jetty都是采用这种方式。
下面是基于NIO工作方式的Socket请求处理方式的处理过程:

2、Buffer的工作方式
可以把Buffer简单地理解为一组基本数据类型的元素列表,它通过几个变量来保存这个数据的当前位置状态:capacity, position, limit, mark:
| 索引 | 说明 |
|---|---|
| capacity | 缓冲区数组的总长度 |
| position | 下一个要操作的数据元素的位置 |
| limit | 缓冲区数组中不可操作的下一个元素的位置:limit<=capacity |
| mark | 用于记录当前position的前一个位置或者默认是-1 |
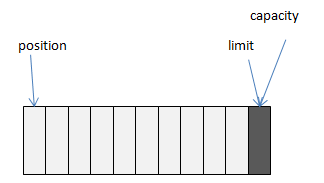
举例:我们通过ByteBuffer.allocate(11)方法创建了一个11个byte的数组的缓冲区,初始状态如上图,position的位置为0,capacity和limit默认都是数组长度。当我们写入5个字节时,变化如下图:
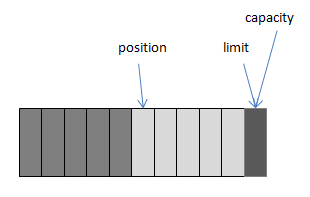
这时我们需要将缓冲区中的5个字节数据写入Channel的通信信道,所以我们调用ByteBuffer.flip()方法,变化如下图所示(position设回0,并将limit设成之前的position的值):
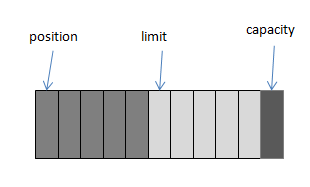
这时底层操作系统就可以从缓冲区中正确读取这个5个字节数据并发送出去了。在下一次写数据之前我们再调用clear()方法,缓冲区的索引位置又回到了初始位置。
调用clear()方法:position将被设回0,limit设置成capacity,换句话说,Buffer被清空了,其实Buffer中的数据并未被清空,只是这些标记告诉我们可以从哪里开始往Buffer里写数据。如果Buffer中有一些未读的数据,调用clear()方法,数据将“被遗忘”,意味着不再有任何标记会告诉你哪些数据被读过,哪些还没有。如果Buffer中仍有未读的数据,且后续还需要这些数据,但是此时想要先先写些数据,那么使用compact()方法。compact()方法将所有未读的数据拷贝到Buffer起始处。然后将position设到最后一个未读元素正后面。limit属性依然像clear()方法一样,设置成capacity。现在Buffer准备好写数据了,但是不会覆盖未读的数据。
调用mark()方法:它将记录当前position的上一次位置,之后可以通过调用reset()方法恢复到这个position。
调用rewind()方法:它可以将position设回0,所以你可以重读Buffer中的所有数据,limit保持不变,仍然表示能从Buffer中读取多少个元素。
3、NIO的数据访问方式
五、I/O调优
1、磁盘I/O优化
2、TCP网络参数调优
[root@192 ~]# cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999 echo "1024 65535" > /proc/sys/net/ipv4/ip_local_port_range设置向外连接可用端口范围 表示可以使用的端口为65535-1024个(0~1024为受保护的)
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse 设置time_wait连接重用 默认0
echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle 设置快速回收time_wait连接 默认0
echo 180000 > /proc/sys/net/ipv4/tcp_max_tw_buckets 设置最大time_wait连接长度 默认262144
echo 1 > /proc/sys/net/ipv4/tcp_timestamps 设置是否启用比超时重发更精确的方法来启用对RTT的计算 默认0
echo 1 > /proc/sys/net/ipv4/tcp_window_scaling 设置TCP/IP会话的滑动窗口大小是否可变 默认1
echo 20000 > /proc/sys/net/ipv4/tcp_max_syn_backlog 设置最大处于等待客户端没有应答的连接数 默认2048
echo 15 > /proc/sys/net/ipv4/tcp_fin_timeout 设置FIN-WAIT状态等待回收时间 默认60
echo "4096 87380 16777216" > /proc/sys/net/ipv4/tcp_rmem 设置最大TCP数据发送缓冲大小,分别为最小、默认和最大值 默认4096 87380 4194304
echo "4096 65536 16777216" > /proc/sys/net/ipv4/tcp_wmem 设置最大TCP数据 接受缓冲大小,分别为最小、默认和最大值 默认4096 87380 4194304
echo 10000 > /proc/sys/net/core/somaxconn 设置每一个处于监听状态的端口的监听队列的长度 默认128
echo 10000 > /proc/sys/net/core/netdev_max_backlog 设置最大等待cpu处理的包的数目 默认1000
echo 16777216 > /proc/sys/net/core/rmem_max 设置最大的系统套接字数据接受缓冲大小 默认124928
echo 262144 > /proc/sys/net/core/rmem_default 设置默认的系统套接字数据接受缓冲大小 默认124928
echo 16777216 > /proc/sys/net/core/wmem_max 设置最大的系统套接字数据发送缓冲大小 默认124928
echo 262144 > /proc/sys/net/core/wmem_default 设置默认的系统套接字数据发送缓冲大小 默认124928
echo 2000000 > /proc/sys/fs/file-max 设置最大打开文件数 默认385583注意,以上设置都是临时性的,系统重启后就会丢失。
3、网络I/O优化
① 减少网络交互的次数。
要减少网络交互的次数通常需要在网络交互的两端设置缓存,如Oracle的JDBC就提供了对查询结果的缓存,在客户端和服务器端都有,可以有效减少对数据库的访问。除了设置缓存还可以合并访问请求,比如在查询数据库时,我们要查询10个ID,可以每次查一个ID,也可以一次查10个ID。再比如,在访问一个页面进通常会有多个JS和CSS文件,我们可以将多个JS文件合并在一个HTTP链接中,每个文件用逗号隔开,然后发送到后端的Web服务器。
② 减少网络传输数据量的大小。
通常的办法是将数据压缩后再传输,比如在HTTP请求中,通常Web服务器将请求的Web页面gzip压缩后再传输给浏览器。还有就是通过设计简单的协议,尽量通过读取有用的协议头来获取有价值的信息,比如在设计代理程序时,4层代理和7层代理都是在尽量避免读取整个通信数据来获取所需要的信息。
③ 尽量减少编码。
在网络传输中数据都是以字节形式进行传输的,但是我们要发送的数据都是字符形式的,从字符到字节必须编码,但是这个编码过程是比较费时的,所以在经过网络I/O传输时,尽量直接以字节形式发送。
④ 根据应用场景设计合适的交互方式。
a. 同步与异步
同步就是一个任务的完成需要依赖另一个任务时,只有等待被依赖的任务完成后,依赖的任务才能完成,这是一种可靠的任务序列,要成功都成功,要失败都失败。而异步不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,只要自己完成了整个任务就算完成了,所以它是不可靠的任务序列,比如打电话和发信息。同步能够保证程序的可靠性,而异步可以提升程序的性能。
b. 阻塞与非阻塞
阻塞就是CPU停下来等待一个慢的操作完成后,CPU才接着完成其它的工作,非阻塞就是在这个慢的操作执行时,CPU去做其它工作,等这个慢的操作完成时,CPU在完成后续的操作。虽然非阻塞的方式可以明显提高CPU的利用率,但是也可能有不好的效果,就是系统的线程切换会比较频繁。
c. 两种方式的组合
组合的方式有四种,分别是:同步阻塞、异步阻塞、同步非阻塞、异步非阻塞,这四种方式对I/O性能都有影响,如下所示:
| 组合方式 | 性能分析 |
| 同步阻塞 | 这种方式I/O性能一般很差,CPU大部分时间处于空闲状态 |
| 同步非阻塞 | 这种方式通常能提升I/O性能,但是会增加CPU消耗 |
| 异步阻塞 | 这种方式经常用于分布式数据库,比如在一个分布式数据库中,通常有一份是同步阻塞的记录, 还有2~3份会备份一起写到其他机器上,这些备记录通常都采用异步阻塞的方式来写I/O |
| 异步非阻塞 | 这种组合方式用起来比较复杂,只有在一些非常复杂的分布式情况下使用,集群之间的消息同步 机制一般使用这种I/O组合方式,它适合同时要传多份相同的数据到集群中的不同机器,同时数据 的传输量虽然不大却非常频繁的情况 |
注意:虽然异步和非阻塞能够提升I/O的性能,但是也会带来一些额外的性能成本,比如会增加线程数量从而增加CPU的消耗,同时也会导致程序设计复杂度的上升,如果设计的不合理,反而会导致性能下降。
六、设计模式解析之适配器模式
1、适配器模式的类结构

Target(目标接口):客户端期待的接口;
Adaptee(源接口):需要被适配的接口;
Adapter(适配器):将源接口适配成目标接口,继承源接口,实现目标接口。
2、Java I/O中的适配器模式
七、设计模式解析之装饰器模式
1、装饰器模式的类结构

Component:抽象组件角色,定义一组抽象的接口,规定这个被装饰组件都有哪些功能;
ConcreteComponent:实现这个抽象组件的所有功能;
Decorator:装饰器角色,它持有一个Component对象实例的引用,定义一个与抽象组件一致的接口;
ConcreteDecorator:具体的装饰器实现者,负责实现装饰器角色定义的功能。















 1390
1390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









