







浅浅试一下
import jieba
import jieba.posseg as psg
from collections import Counter
text = '我现在在jupyter notebook上写文本分析的代码!'
cut = jieba.cut(text)
'/'.join(cut)
print(text)
我现在在jupyter notebook上写文本分析的代码!
1.试图将句子最准确的切开,适合文本分析:
words = psg.cut(text)
for word,flag in words:
print(word,flag)
我 r
现在 t
在 p
jupyter eng
x
notebook eng
上写 v
文本 n
分析 vn
的 uj
代码 n
! x
2.把句子中所有可以组成词的词语都扫描出来,速度快,但不能解决歧义:
'/'.join(jieba.cut(text,True))
‘我/现在/在/jupyter// //notebook/上/写/文本/本分/分析/的/代码/!’
数据采集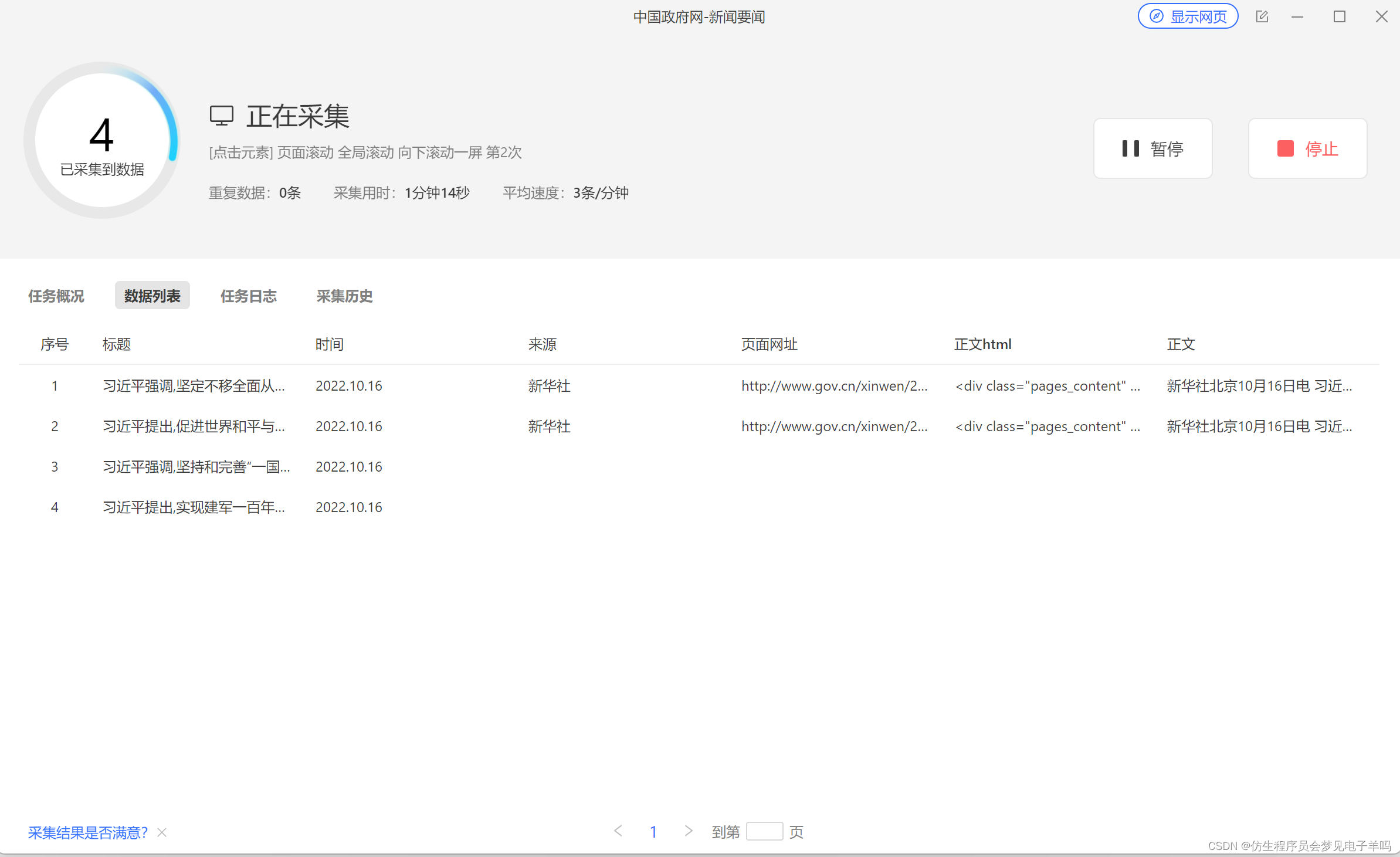

import jieba
import jieba.analyse
# 待分词的文本路径
sourceTxt = r"C:\Users\83854\Documents\shujvji\news1.txt"
# 分好词后的文本路径
targetTxt = r"C:\Users\83854\Documents\shujvji\fenci1.txt"
# 对文本进行操作
with open(sourceTxt, 'r', encoding = 'utf-8') as sourceFile, open(targetTxt, 'a+', encoding = 'utf-8') as targetFile:
for line in sourceFile:
seg = jieba.cut(line.strip(), cut_all = False)
# 分好词之后之间用空格隔断
output = ' '.join(seg)
targetFile.write(output)
targetFile.write('\n')
prinf('写入成功!')
# 提取关键词
with open(targetTxt, 'r', encoding = 'utf-8') as file:
text = file.readlines()
"""
几个参数解释:
* text : 待提取的字符串类型文本
* topK : 返回TF-IDF权重最大的关键词的个数,默认为20个
* withWeight : 是否返回关键词的权重值,默认为False
* allowPOS : 包含指定词性的词,默认为空
"""
keywords = jieba.analyse.extract_tags(str(text), topK = 10, withWeight=True, allowPOS=())
print(keywords)
print('提取完毕!')
import jieba
import jieba
import re
#打开要处理的文章
reader = open( r"C:\Users\83854\Documents\shujvji\news1.txt",'r',encoding='utf8')
strs =reader.read()
result = open( r"C:\Users\83854\Documents\shujvji\fenci1.txt","w")
# 分词,去重,列表
word_list = jieba.cut(strs,cut_all=True)
# 正则表达式去除数字,符号,单个字
new_words = []
for i in word_list:
m = re.search("\d+",i)
n = re.search("\W+",i)
if not m and not n and len(i)>1:
new_words.append(i)
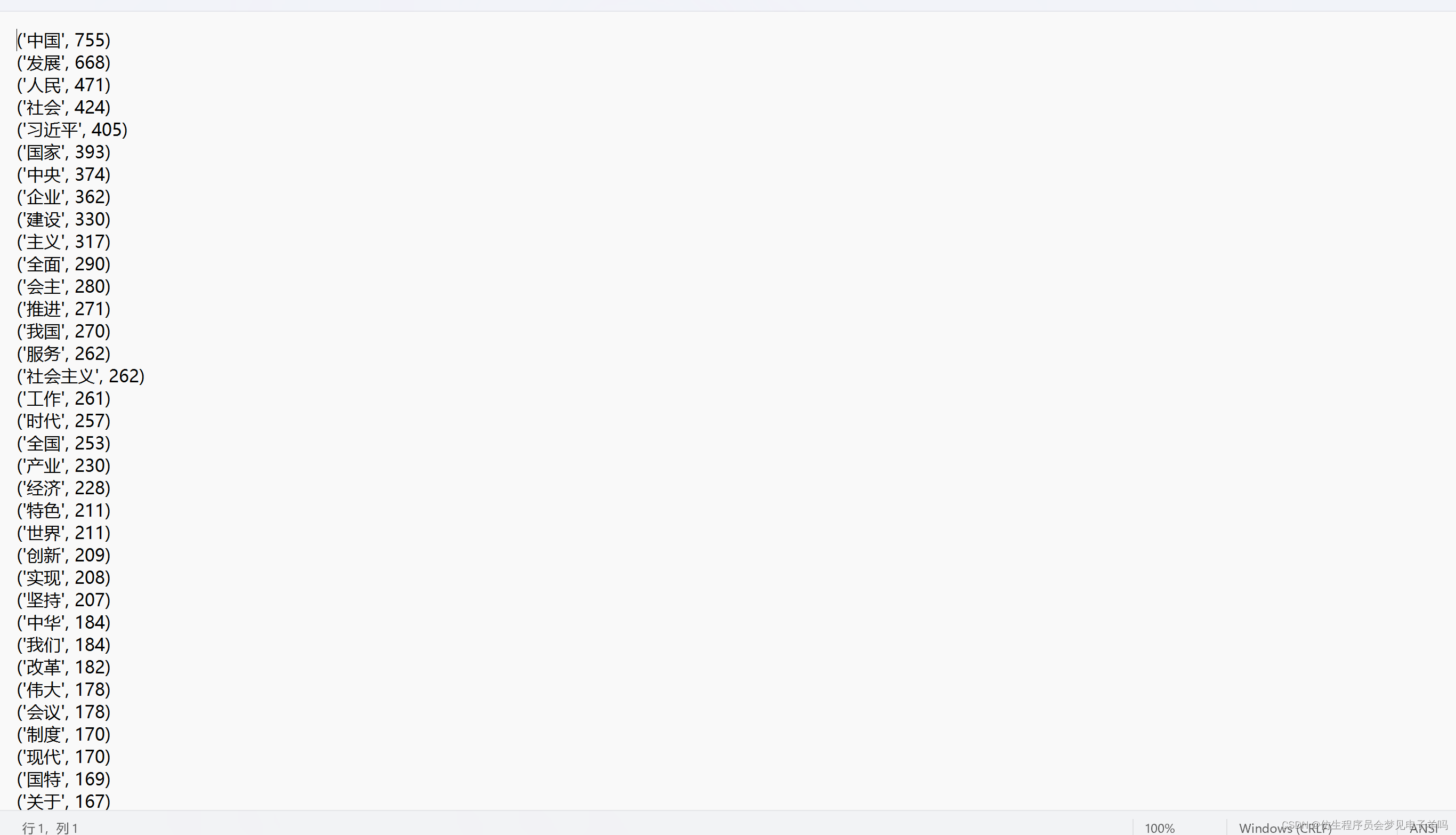
# 统计词频
word_count = {} # 创建字典
for i in set(new_words): # 用set去除list中的重复项
word_count[i] = new_words.count(i)
# 格式整理
list_count = sorted(word_count.items(),key=lambda co:co[1],reverse=True)
# 打印结果
for i in range(300):
print(list_count[i],file=result)
#关闭文件
reader.close()
result.close()















 7944
7944

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









