






在使用Python进行文本分析时,常常需要进行词频统计,除了词云图,我们还经常想要计算研究所关注的词汇在总词汇中的比重,这可以使用jieba库做词频统计来实现。
- 文本词频统计代码实现
import jieba import refrom collections import Counterimport jsonimport matplotlib.pyplot as plt stopfile=open(r'C:甥敳獲全球价值链.txt', 'r', encoding='UTF-8').read() stopfile = stopfile.replace(" ","")stoplist = stopfile.split('') words = [x for x in jieba.lcut(stopfile) if len(x) >= 2 and x not in stoplist] top10 = Counter(words).most_common(10) print(json.dumps(top10, ensure_ascii=False)) # 画出柱状图 plt.rcParams['font.sans-serif'] = ['SimHei'] c=top10plt.rcParams['font.family']='sans-serif' name_list=[x[0] for x in c] num_list=[x[1] for x in c] b=plt.bar(range(len(num_list)), num_list,tick_label=name_list)- Jupyter Notebook返回结果
- [["制造业", 221], ["我国", 171], ["价值链", 144], ["全球", 112], ["创新", 77], ["促进", 75], ["发展", 71], ["政策", 71], ["研究", 69], ["出口", 63]]
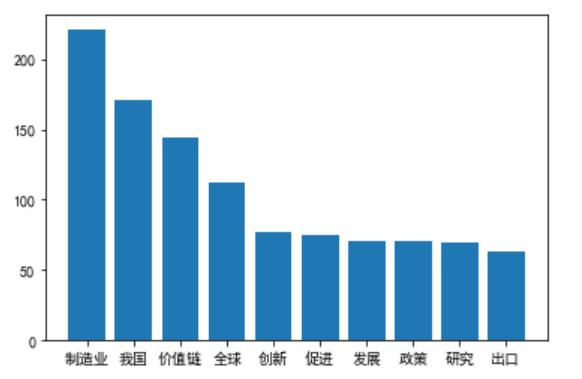
- 重点词汇在总词汇中的比重代码实现
keywords = ['全球价值链','创新','产品质量','政策','位置','制造业']b=Counter(words)#提取重点词汇的频次wordsfreq = [b[x] for x in keywords]totalfreq = sum(wordsfreq) # 所有词语的总数s= sum(b.values())# 计算比重weight = totalfreq/sprint(keywords)print(wordsfreq)print(totalfreq)print(weight)- Jupyter Notebook返回结果
- ['全球价值链', '创新', '产品质量', '政策', '位置', '制造业']
- [0, 77, 25, 71, 14, 221]
- 408
- 0.07792207792207792














 7069
7069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









