







1.RANK(),dense_rank()
【语法】RANK ( ) OVER ( [query_partition_clause] order_by_clause )
dense_RANK ( ) OVER ( [query_partition_clause] order_by_clause )
【功能】聚合函数RANK 和 dense_rank 主要的功能是计算一组数值中的排序值。
【参数】dense_rank与rank()用法相当,
【区别】dence_rank在并列关系是,相关等级不会跳过。rank则跳过rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)
dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
分析功能:列出Col2分组后根据Col1排序,并生成数字列。比较实用于在成绩表中查出各科前几名的信息。
SELECT a.*,RANK() OVER(PARTITION BY col2 ORDER BY col1) "Rank" FROM table a;
结果如下:
COL1 COL2 Rank
1 1 1
2 1 2
3 1 3
4 1 4
3 2 1
4 2 2
5 2 3
5 2 3
6 2 5
在9i版本新增加了合计功能(aggregate),即对给定的参数值在设定的排序查询中计算出其排序值。
这些参数必须是常数或常值表达式,且必须和ORDER BY子句中的字段个数、位置、类型完全一致。
合计功能:计算出数值(4,1)在Orade By Col1,Col2排序下的排序值,也就是col1=4,col2=1在排序以后的位置
SELECT RANK(4,3) WITHIN GROUP (ORDER BY col1,col2) "Rank" FROM table;
dense_rank与rank()用法相当,但是有一个区别:dence_rank在并列关系是,相关等级不会跳过。rank则跳过
当rank时为:
select m.a,m.b,m.c,rank() over(partition by a order by b) liu from test3 m
A B C LIU
a cai kai 1
a jin shu 2
a liu wang 3
b lin ying 1
b yang du 2
b yang 99 2
b yao cai 4
而如果用dense_rank时为:
select m.a,m.b,m.c,dense_rank() over(partition by a order by b) liu from test3 m
A B C LIU
a cai kai 1
a jin shu 2
a liu wang 3
b lin ying 1
b yang du 2
b yang 99 2
b yao cai 3 2.lag()和lead()
【语法】LAG(EXPR,<OFFSET>,<DEFAULT>)
LEAD(EXPR,<OFFSET>,<DEFAULT>)
【功能】LAG函数可以在一次查询中取出当前行的同一字段的前面第N行的数据。
LEAD函数可以在一次查询中取出当前行的同一字段的后面第N行的数据。
【参数】EXPR是从其他行返回的表达式
OFFSET是缺省为1 的正数,表示相对行数。 希望检索的当前行分区的偏移量
DEFAULT是在OFFSET表示的数目超出了分组的范围时返回的值。
例:我想查看在每个员工后面来的那个员工的日期
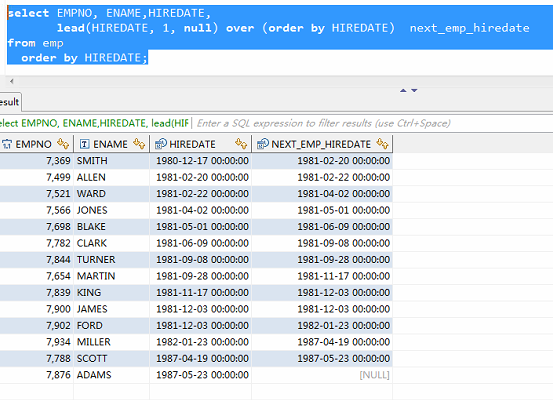
更详细的说明参考:lag()与lead()函数















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









