







https://leetcode.cn/problems/customer-placing-the-largest-number-of-orders/

SELECT
customer_number
FROM
orders
GROUP BY
customer_number
ORDER BY
COUNT(customer_number) DESC
LIMIT 1
嵌套函数
select customer_number
from orders
group by customer_number
having count(order_number)>=all(
select count(order_number)
from orders
group by customer_number
)
用窗口函数
select t.customer_number
from
(select customer_number, rank() over(order by count(order_number) desc) as ranking
from orders
group by customer_number) t
where t.ranking = 1
rank() over(order by 列名)的用法
—rank()over(order by 列名排序)的结果是不连续的,如果有4个人,其中有3个是并列第1名,那么最后的排序结果结果如:1 1 1 4
—dense_rank()over(order by 列名排序)的结果是连续的,如果有4个人,其中有3个是并列第1名,那么最后的排序结果如:1 1 1 2
注意:使用rank()over(order by 排序字段 顺序)排序的时候,空值是最大的
如果排序字段为null,可能造成在排序时将null字段排在最前面,影响排序的正确性。
所以建议将dense_rank()over(order by 列名 排序)改为dense_rank()over(order by 列名排序 nulls last)
这样只要排序字段为null,就会放在最后,而不会影响排序结果
case
一个数据库表:有三个字段:姓名,科目,成绩,科目字段分别有语文,数学,英语这三个值,写一个sql,查出来的结果每条记录有四个字段,分别为姓名,语文成绩,数学成绩,英语成绩
为了将表中的数据按照科目拆分为不同的列,你需要使用条件聚合。假设你的表名为scores,以下是一个可能的SQL查询,它使用了CASE语句和聚合函数MAX(或其他聚合函数,如SUM,但在这个场景下MAX是合适的,因为我们假设每个学生每门科目只有一个成绩):
SELECT
姓名,
MAX(CASE WHEN 科目 = '语文' THEN 成绩 ELSE NULL END) AS 语文成绩,
MAX(CASE WHEN 科目 = '数学' THEN 成绩 ELSE NULL END) AS 数学成绩,
MAX(CASE WHEN 科目 = '英语' THEN 成绩 ELSE NULL END) AS 英语成绩
FROM
scores
GROUP BY
姓名;
group by
group by通常都是和聚合函数还有having一起使用。
select 聚合函数(字段1),字段2 from 表名 where 条件 group by 字段2,字段3
或者
select 聚合函数(字段1),字段2 from 表名 where 条件 group by 字段2,字段3 having 过滤条件
使用了group by 后,要求select出的结果字段都是可汇总的,否则就会出错。
group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面。
常用的聚合函数有:count() 计数, sum() 求和 , avg() 求平均值, max() 求最大值, min()求最小值。
原文链接:https://blog.csdn.net/weixin_47976708/article/details/129642649
组内排序


分组后组内排序
select sell_date,count(distinct product) as num_sold,
group_concat(distinct product order by product asc) as products from Activities
group by sell_date order by sell_date
分组后组内取最大值
字符串拆分
前缀查询 就用like吧
using等价于join操作中的on
使用using必须满足如下两个条件:
- 查询必须是等值连接。
- 等值连接中的列必须具有相同的名称和数据类型。
销售分析III
Sales.sale_date 在且只在 ‘2019-01-01’ and ‘2019-03-31’ 的Product.product_id
SELECT p.product_id,product_name FROM sales s,product p
WHERE s.product_id=p.product_id
GROUP BY p.product_id
HAVING SUM(sale_date < '2019-01-01')=0
AND SUM(sale_date>'2019-03-31')=0;
select product_id, product_name
from Sales join Product
using(product_id)
group by product_id
having sum(sale_date between "2019-01-01" and "2019-03-31") = count(sale_date)
1158. 市场分析 I
我写的
select
Users.user_id as buyer_id,
Users.join_date as join_date,
count(SUBSTRING(Orders.order_date,1,4) = '2019') as orders_in_2019
from Users join Orders on Users.user_id = Orders.buyer_id
group by Users.user_id
order by Users.user_id asc
输出
{"headers": ["buyer_id", "join_date", "orders_in_2019"],
"values": [[1, "2018-01-01", 2],
[2, "2018-02-09", 2],
[3, "2018-01-19", 1],
[4, "2018-05-21", 1]]}
正确答案
{"headers": ["buyer_id", "join_date", "orders_in_2019"],
"values": [[1, "2018-01-01", 1],
[2, "2018-02-09", 2],
[3, "2018-01-19", 0],
[4, "2018-05-21", 0]]}
我的答案 订单年份为2019这个条件没生效,统计了所有订单
正确答案
select Users.user_id as buyer_id, join_date, ifnull(UserBuy.cnt, 0) as orders_in_2019
from Users
left join (
select buyer_id, count(order_id) cnt
from Orders
where order_date between '2019-01-01' and '2019-12-31'
group by buyer_id
) UserBuy
on Users.user_id = UserBuy.buyer_id
或者
select u.user_id as buyer_id,
u.join_date,
count(if(year(o.order_date) = '2019', 1, null)) as orders_in_2019
from users u
left join orders o on o.buyer_id = u.user_id
group by user_id;
分组,组内统计筛选
- 部门工资最高的员工

分组,且找出该组中某个字段的最值
答案
select
d.Name as Department,
e.Name as Employee,
e.Salary
from
Employee e,Department d
where
e.DepartmentId=d.id
and
(e.Salary,e.DepartmentId)
in (select max(Salary),DepartmentId from Employee group by DepartmentId);
利用开窗函数可以取每个部门最高,也可以取前二高,前三高,也可以只取第一第三,都OK的
- 每个部门最高
SELECT S.NAME, S.EMPLOYEE, S.SALARY
FROM (SELECT D.NAME,
T.NAME EMPLOYEE,
T.SALARY,
ROW_NUMBER() OVER(PARTITION BY T.DEPARTMENTID ORDER BY T.SALARY DESC) RN
FROM EMPLOYEE T
LEFT JOIN DEPARTMENT D
ON T.DEPARTMENTID = D.ID) S
WHERE S.RN = 1
SQL中 ROW_NUMBER 函数的用法
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号。在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号。
说明:返回结果集分区内行的序列号,每个分区的第一行从1开始。
语法:ROW_NUMBER () OVER ([ <partition_by_clause> ] <order_by_clause>) 。
备注:ORDER BY 子句可确定在特定分区中为行分配唯一 ROW_NUMBER 的顺序。
参数:<partition_by_clause> :将 FROM 子句生成的结果集划入应用了 ROW_NUMBER 函数的分区。
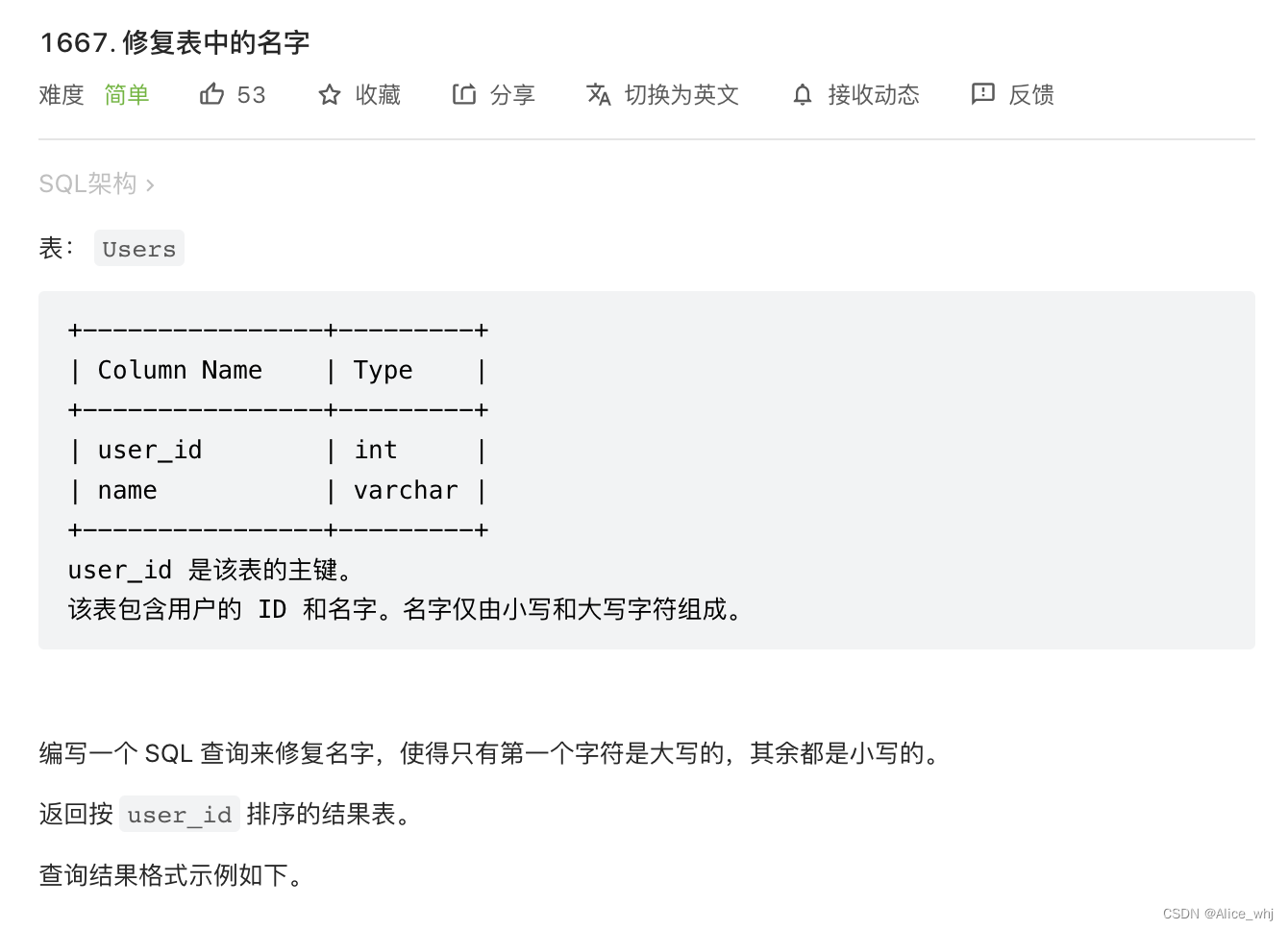
我的答案
select user_id,
if(length(name)=1,upper(name),
concat(upper(substr(name,1,1)),lower(substr(name,2,length(name))))
) as name
from Users order by user_id
评论区别人的答案
select
user_id,
concat(upper(left(name,1)),lower(substr(name,2))) as name
from
Users
order by
user_id
select user_id,
concat(upper(left(name, 1)), lower(right(name, length(name) - 1))) name
from Users
order by user_id
● CONCAT 用来拼接字符串
● LEFT 从左边截取字符
● RIGHT 从右边截取字符
● UPPER 变为大写
● LOWER 变为小写
● LENGTH 获取字符串长度
行程和用户
这里是分组后,,每组里,status !=‘completed’ 占改组总数的比例,保留两位小数
select
request_at 'Day',
convert(sum(status !='completed')/count(*),decimal(15,2)) 'Cancellation Rate'
from Trips
left join Users a on Trips.client_id = a.users_id
left join Users b on Trips.driver_id = b.users_id
where a.banned = 'No' and b.banned = 'No'
and request_at >= '2013-10-01'
and request_at <= '2013-10-03'
group by request_at
order by request_at
最主要的是
convert(sum(status !=‘completed’)/count(),decimal(15,2))
我一开始用的是
count(status !=‘completed’)/count()
一直不对,其实因为
status !=‘completed’ 为true=1,false时=0
而count(0)=1,count(1)=1
所以应该用sum
除法
convert(除数/被除数,decimal(15,2))
decimal(15,2)中的2是保留几位小数
这一行
convert(sum(status !='completed')/count(*),decimal(15,2)) 'Cancellation Rate'
还可以替换为
round(avg(Status!='completed'), 2) 'Cancellation Rate'
SQL AVG()函数
AVG()通过对表中行数计数并计算其列值之和,求得该列的平均值。AVG()可用来返回所有列的平均值,也可以用来返回特定列或行的平均值。
ROUND() 函数
ROUND() 函数用于把数值字段舍入为指定的小数位数。
SELECT ROUND(column_name,decimals) FROM TABLE_NAME;
这里阻塞我的点
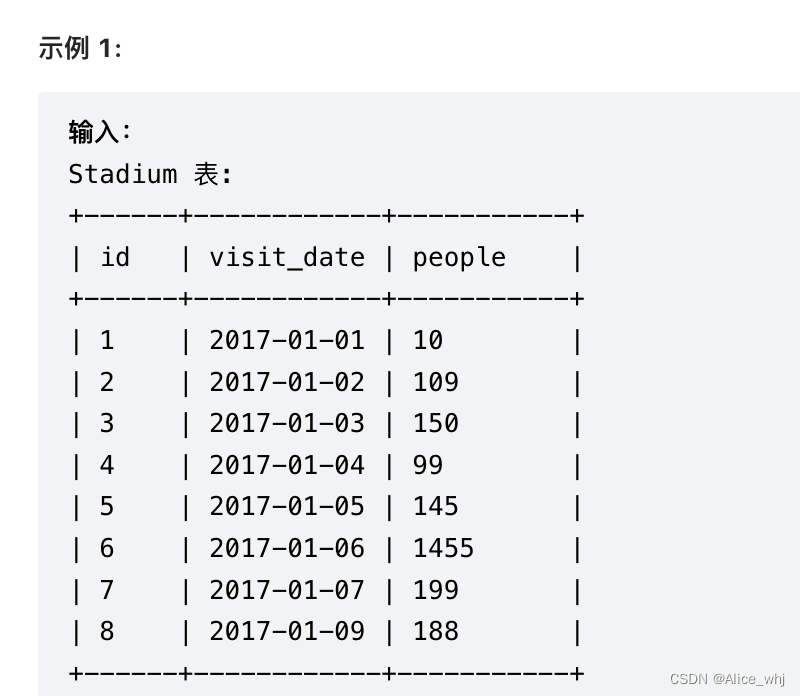
将一行转成多行,比如一个表
table
字段 field1 field2 field3
记录1 1 2 3
记录2 4 5 6
我想转成
field
1
2
3
4
5
6

我的做法
select
a.id as id,
b.id as id,
c.id as id
from Stadium a left join Stadium b on a.id+1 = b.id
left join Stadium c on a.id+2 = c.id
where a.people >=100 and b.people >=100 and c.people >= 100
最终还是错的,,

还是无法成为三行
我的本意是 distinct(5,6,7,6,7,8)
?????还是不会,,再看

将多条数据合成一条数据,多条数据以扩展字段点方式存储
我的答案
select
id as id,
(CASE WHEN month = 'Jan' THEN revenue as Jan_revenue
WHEN month = 'Feb' THEN revenue as Feb_revenue
WHEN month = 'Mar' THEN revenue as Mar_revenue
WHEN month = 'Apr' THEN revenue as Apr_revenue
ELSE revenue as May_revenue
END) AS REMARK
from Department
group by id order by id
当然,错了,语法错误
正确答案
SELECT id,
SUM(CASE WHEN month='Jan' THEN revenue END) AS Jan_Revenue,
SUM(CASE WHEN month='Feb' THEN revenue END) AS Feb_Revenue,
SUM(CASE WHEN month='Mar' THEN revenue END) AS Mar_Revenue,
SUM(CASE WHEN month='Apr' THEN revenue END) AS Apr_Revenue,
SUM(CASE WHEN month='May' THEN revenue END) AS May_Revenue,
SUM(CASE WHEN month='Jun' THEN revenue END) AS Jun_Revenue,
SUM(CASE WHEN month='Jul' THEN revenue END) AS Jul_Revenue,
SUM(CASE WHEN month='Aug' THEN revenue END) AS Aug_Revenue,
SUM(CASE WHEN month='Sep' THEN revenue END) AS Sep_Revenue,
SUM(CASE WHEN month='Oct' THEN revenue END) AS Oct_Revenue,
SUM(CASE WHEN month='Nov' THEN revenue END) AS Nov_Revenue,
SUM(CASE WHEN month='Dec' THEN revenue END) AS Dec_Revenue
FROM department
GROUP BY id
ORDER BY id;
首先,,同一个月份的奖金要相加后放在一个字段,这个忘了,,其次,case–when–用的不对
by the way,提点别的
group_concat()详解
是将分组中括号里对应的字符串进行连接.如果分组中括号里的参数xxx有多行,那么就会将这多行的字符串连接,每个字符串之间会有特定的符号进行分隔。
将分组中column1这一列对应的多行的值按照column2 升序或者降序进行连接,其中分隔符为seq
如果用到了DISTINCT,将表示将不重复的column1按照column2升序或者降序连接
如果没有指定SEPARATOR的话,也就是说没有写,那么就会默认以 ','分隔
GROUP_CONCAT([DISTINCT] column1 [ORDER BY column2 ASC\DESC] [SEPARATOR seq]);
[ ORDER BY column2 ASC\DESC] :表示将会根据column2升序或者降序连接.其中column2不一定一定要求是column1,只要保证column2在这个分组中即可.如果没有写ORDER BY句段,那么连接是没有顺序的。
[ SEPARATOR seq] : 表示各个column1将会以什么分隔符进行分隔,例如SEPARATOR '’,则表示column1将会以进行分隔。如果没有指定seq的时候,也即没有写SEPARATOR seq这个句段,那么就会默认是以,分隔的。
CONCAT函数中要连接的数据含有NULL,最后返回的是NULL,但是GROUP_CONCAT不会这样,他会忽略NULL值。
值得一提的是,GROUP_CONCAT只是将xxx这一列中的多行数据进行连接成为一行字符串,而CONCAT则是可以将多列数据进行连接。
CASE WHEN条件表达式函数
CASE WHEN condition THEN result
[WHEN...THEN...]
ELSE result
END















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









