







1、组合两个表(175)
person表:

address表:

2、建表语句
person表:
CREATE TABLE `person` (
`PersonId` int NOT NULL,
`FirstName` varchar(20) DEFAULT NULL,
`LastName` varchar(20) DEFAULT NULL,
PRIMARY KEY (`PersonId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
address表:
CREATE TABLE `address` (
`AddressId` int NOT NULL,
`PersonId` int DEFAULT NULL,
`City` varchar(20) DEFAULT NULL,
`State` varchar(20) DEFAULT NULL,
PRIMARY KEY (`AddressId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
要求:
编写一个SQL查询来报告 Person 表中每个人的姓、名、城市和州。如果 personId 的地址不在 Address 表中,则报告为空 null 。以任意顺序 返回结果表。
3、解题语句
SELECT
LastName,FirstName,City,State
FROM
person
LEFT JOIN
address
ON
person.PersonId = address.PersonId;
4、题目总结
1、外键的考察,PersonId作为address表的外键;
2、left join的使用,当右表不存在时就显示为null;
3、使用on来拼接过滤条件,不要使用where;
4、联表查询就是将两张表联在一起,一个外键可理解为一个占位符,减少冗余。
5、left join表示左表全查,reight join表示右表全查,关键字左边叫左表,关键字右边叫右表。
2、第二高薪水(176)
employee表:

1、题目描述
编写一个 SQL 查询,获取并返回 employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null ,若有多条,只返回一条。
2、建表语句
CREATE TABLE `employee_176` (
`id` int NOT NULL,
`salary` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
insert into employee_176 (id, salary) values (1, 100),(2, 100),(3, 100);
3、解题语句
方式一:使用临时表(没有第二高是不会返回NULL,不符合题意)
SELECT
salary
FROM
(SELECT DISTINCT salary FROM employee_176 ORDER BY salary DESC LIMIT 1,1) AS emp;
方式二:使用max()函数,不存在第二高薪水不会返回NULL
SELECT
id , salary
FROM
employee_176
WHERE
salary =(SELECT MAX(salary)
FROM employee_176
WHERE salary < (SELECT MAX(salary) FROM employee_176))
LIMIT 1;
方式三:使用ifnull( , )函数,不存在第二高薪水会返回NULL,符合题意
SELECT
IFNULL
(
(SELECT DISTINCT salary
FROM employee_176
ORDER BY salary DESC
LIMIT 1 OFFSET 1),NULL
)
AS '第二高薪水'
4、题目总结
1、该题关键使用limit 1 offset 1,尤其是offset的使用,偏移指定的距离;当然也可以不写offset,用逗号隔开两个参数:limit 1,1
2、使用ifnull()函数是为了当不存在第二高薪水时返回null;IFNULL原理是如果第一个参数为NULL,则返回第二个参数,否则返回第一个参数。
3、临时表就是从一个select结果集中再去查询,也叫子查询;
4、from后面的临时表时记得加上临时表的别名,即as emp;
3、第N高薪水(177)
1、题目描述

编写一个SQL查询来报告 Employee 表中第 n 高的工资。如果没有第 n 个最高工资,查询应该报告为 null 。


2、建表语句
Create table If Not Exists employee (id int, salary int);
insert into employee (id, salary) values ('1', '100');
insert into employee (id, salary) values ('2', '200');
insert into employee (id, salary) values ('3', '300');
3、解题语句
DELIMITER $$
DROP FUNCTION IF EXISTS getTwoSalary $$
CREATE
/*[DEFINER = { user | CURRENT_USER }]*/
FUNCTION `leetcode`.`getTwoSalary`(N INT)
RETURNS INT
/*LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'*/
/*定义该函数只读取数据*/
READS SQL DATA
BEGIN
SET N = N-1;
RETURN(
SELECT DISTINCT salary FROM employee ORDER BY salary DESC LIMIT N,1
);
END$$
DELIMITER ;
使用刚创建的函数:
SELECT DISTINCT getTwoSalary(3) FROM employee;
4、题目总结
1、该题考查函数的创建,因为N是变化的,需作为参数传给函数;而函数返回值就是要查询的数据;
2、创建函数出现以下异常:(开启了bin-log)
This function has none of DETERMINISTIC, NO SQL, or READS SQL
DATA in its declaration and binary logging is enabled (you
*might* want to use the less safe log_bin_trust_function_creators variable)
解决一:在创建函数时指定函数
1 DETERMINISTIC 不确定的
2 NO SQL 没有SQl语句,当然也不会修改数据
3 READS SQL DATA 只是读取数据,当然也不会修改数据
4 MODIFIES SQL DATA 要修改数据
5 CONTAINS SQL 包含了SQL语句
解决二:开启信任
SET GLOBAL log_bin_trust_function_creators =TRUE;
3、由于函数没查询到就返回null,符号题目要求;
4、创建函数时记得用delimit $$来临时改变SQL语句的结束符;
5、注意用 select distinct去重;
4、分数排名(178)
1、题目描述

编写SQL查询对分数进行排序。排名按以下规则计算:
- 分数应按从高到低排序
- 如果两个分数相等,那么两个分数的排名应该相同
- 在排名相同的分数后,排名数应是下一个连续的整数。换句话说,排名间不应该有空缺的数字。
按score降序返回结果表。

2、建表语句
CREATE TABLE `scores` (
`id` bigint NOT NULL COMMENT '主键',
`score` float DEFAULT NULL COMMENT '成绩',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='成绩表'
#插入数据
INSERT INTO scores() VALUES(1,66.56),(2,76.56),
(3,66.56),(4,86.75),(5,96.52),(6,79.99),(7,76.56);
3、解题语句
#dense_rank()over函数: 相同的排序序号也相同,且排序序号连续
SELECT id AS 'id',score AS '成绩',dense_rank()over(ORDER BY score DESC) AS '排名' FROM scores;
#其他排序函数的使用
#rank()over函数: 相同的排序序号也相同,但排序序号不连续
SELECT id AS 'id',score AS '成绩',rank()over(ORDER BY score DESC) AS '排名' FROM scores;
#row_number()over函数: 排序序号一直连续下去
SELECT id AS 'id',score AS '成绩',row_number()over(ORDER BY score ASC) AS '排名' FROM scores;
#ntile(3)over函数: 分为3组
SELECT id AS 'id',score AS '成绩', ntile(3)over(ORDER BY score DESC) AS '排名' FROM scores;
4、题目总结
1、四大排序函数:
- rank()over:相同的排序序号也相同,但排序序号不会连续;如1 2 2 4 5 5 7
- dense_rank()over:相同的排序序号就相同,并且序号是连续的;如1222345567
- row_number()over:不考虑相同的,排序序号一直连续下去;1234567
- ntile(group_num)over:将结果分成group_num个组;
2、本题使用dense_rank()over函数:密集排名,符合题目要求;
5、连续出现的数字(180)
1、题目描述
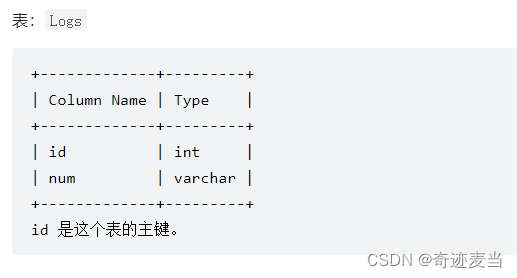
编写一个SQL查询,查找所有至少连续出现三次的数字。返回的结果表中的数据按任意顺序排列。
2、建表语句
#建表语句
CREATE TABLE `logs` (
`id` bigint NOT NULL,
`num` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
#插入数据
INSERT INTO logs() VALUES(1,'18'),(2,'12'),(3,'28'),(4,'14'),
(5,'14'),(6,'14')(7,'18'),(8,'18'),(9,'18'),(10,'24');
3、解题语句
#核心是使用窗口函数Lead()over()和Lag()over()
SELECT q.Num AS '连续三次出现' FROM(
SELECT
Id,
Num,
#从当前记录获取后一行记录的num值,如果没有后一行,则返回null
LEAD(Num)OVER(ORDER BY Id) AS 'next',
#从当前记录获取前一行记录的num值,如果没有前一行,则返回null
Lag(Num)OVER(ORDER BY Id) AS 'last'
FROM
LOGS)AS q
WHERE
q.next=q.Num AND q.last=q.Num;
其它解法:
#使用用户变量:
SELECT DISTINCT num AS '连续三次出现'
FROM (
SELECT num,
CASE
WHEN @prev = Num THEN @count := @count + 1
WHEN (@prev := Num) IS NOT NULL THEN @count := 1
END AS CNT
FROM LOGS, (SELECT @prev := NULL,@count := NULL) AS t
) AS temp
WHERE temp.CNT >= 3
#优点: 简单; 缺点: 如果id不连续时,查询不到
SELECT Num AS '连续三次出现' FROM LOGS
WHERE (Id+1, Num) IN (SELECT * FROM LOGS)
AND (Id+2, Num) IN (SELECT * FROM LOGS)
4、题目总结
1、SQL中 ‘:=’ 表示对变量赋值;
2、IN前面可以写多个字段,如上面的(Id+1, Num) IN (SELECT * FROM LOGS),之前都是
id IN(1,2,3)见得比较多;
3、重点理解窗口函数:Lead()over()和Lag()over();
4、重点理解的SQL语句:
SELECT
Id,
Num,
#从当前记录获取后一行记录的num值,如果没有后一行,则返回null
LEAD(Num)OVER(ORDER BY Id) AS 'next',
#从当前记录获取前一行记录的num值,如果没有前一行,则返回null
Lag(Num)OVER(ORDER BY Id) AS 'last'
FROM
LOGS;
上面SQL的查询结果是:
+----+------+------+------+
| Id | Num | next | last |
+----+------+------+------+
| 1 | 18 | 12 | NULL |
| 2 | 12 | 28 | 18 |
| 3 | 28 | 14 | 12 |
| 4 | 14 | 14 | 28 |
| 5 | 14 | 14 | 14 |
| 7 | 14 | 18 | 14 |
| 9 | 18 | 24 | 14 |
| 10 | 24 | 14 | 18 |
| 20 | 14 | 18 | 24 |
| 21 | 18 | NULL | 14 |
+----+------+------+------+
LEAD()OVER:【简单理解】将每一条记录往上提升一位,最后一位置空;(按位左移)
LAG()OVER:【简单理解】将每一条记录玩下移动一位,第一位置空;(按位右移)
6、超过经理收入的员工(181)
1、题目描述

要求:编写一个SQL查询来查找收入比经理高的员工,以任意顺序返回结果;

解释:
- 因为Joe的7000薪资比他的经理Sam6000的薪资高,故输出结果Joe;
- 而Henry的8000薪资小于他的经理Max9000的薪资;
2、建表语句
CREATE TABLE `employee_181` (
`id` bigint NOT NULL COMMENT '主键',
`name` varchar(20) NOT NULL COMMENT '员工姓名',
`salary` decimal(10,2) NOT NULL COMMENT '薪水',
`managerId` int DEFAULT NULL COMMENT '经理的id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO employee_181() VALUES(1,'张三',5500.00,3),
(2,'李四',6400.00,4),(3,'王五',4500.00,NULL),(4,'邓涛',7000.00,NULL);
3、解题语句
#方法一: 自连接inner join
SELECT
e.name AS '收入高于经理的员工'
FROM
employee_181 AS e
INNER JOIN
employee_181 AS m
ON
e.managerId = m.id AND e.salary > m.salary;
方法二: 笛卡尔积+where
SELECT
e.name AS '收入高于经理的员工'
FROM
employee_181 AS e,
employee_181 AS m
WHERE
e.ManagerId = m.Id AND e.Salary > m.Salary;
方法三: 子查询
SELECT
e.name AS '收入高于经理的员工'
FROM
employee_181 AS e
WHERE
salary > (SELECT
salary
FROM
employee_181 AS m
WHERE
e.managerId = m.id);
4、题目总结
1、金钱类型最好用decimal( , )数据类型;
2、员工和经理都在这同一个表中,张三、李四是员工,王五、邓涛是经理,张三的经理是王五,李四的经理是邓涛;
3、自连接的考察;理解下面的SQL语句:employee_181表与自己连接,故叫自连接
SELECT
*
FROM
employee_181 AS emp
INNER JOIN
employee_181 AS manager
ON
emp.managerId = manager.id AND emp.salary > manager.salary;
7、查找重复的电子邮箱(182)
1、题目描述
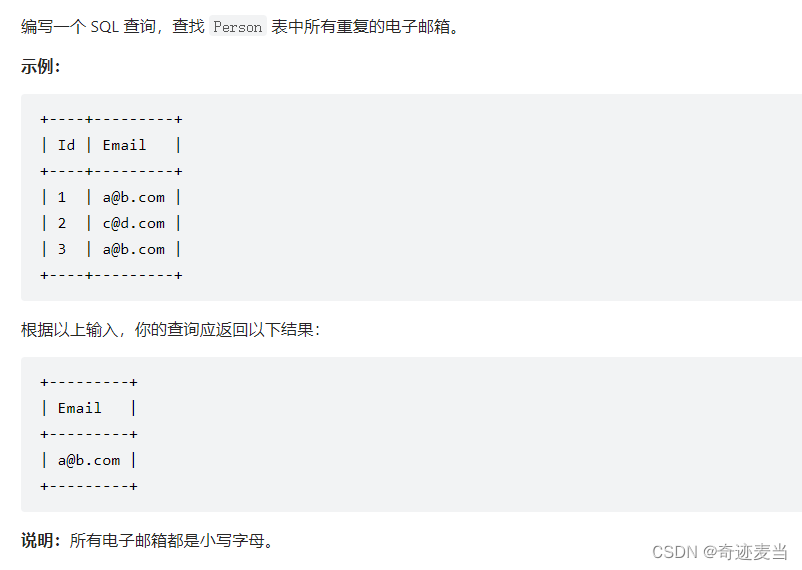
2、建表语句
CREATE TABLE `person_182` (
`id` bigint NOT NULL,
`email` varchar(18) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据
INSERT INTO person_182() VALUES(1,'123abc456@163.com'),(2,'456abc456@163.com'),
(3,'123abc456@163.com'),(4,'456abc123@163.com');
3、解题语句
#方式一: 子查询,可以查询出为null的
SELECT
email AS '重复的邮箱' ,p.num AS '重复数'
FROM
(SELECT COUNT(1) AS num ,email
FROM
person_182
GROUP BY
email) AS p
WHERE
p.num > 1;
方式二:group by + having + 聚合函数count(),但如果为null,查询不出来
SELECT
email AS '重复的邮箱',COUNT(email) AS '重复数'
FROM
person_182
GROUP BY
email
HAVING COUNT(email) > 1;
方式三:自连接,这里用p1.id < p2.id代替p1.id != p2.id,不能查询到为null的;
SELECT DISTINCT
p1.email AS '重复的邮箱'
FROM
person_182 p1
JOIN
person_182 p2
ON
p1.email=p2.email
AND
p1.id < p2.id;
4、题目总结
1、聚合函数和group by 的配置使用
SELECT COUNT(1) FROM person_182 GROUP BY email;
2、查重复的常用三种方式:子查询、自连接、group by +having+聚合函数
8、从不订购的客户(183)
1、题目描述
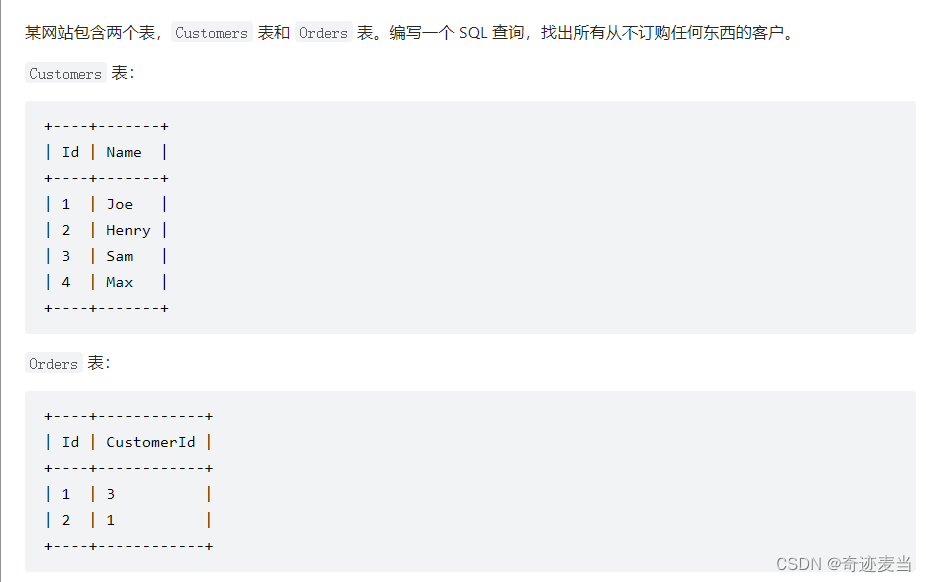

2、建表语句
Customers表:
CREATE TABLE `customers` (
`id` bigint NOT NULL,
`name` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO
customers()
VALUES
(1,'张三'),(2,'李四'),(3,'王五'),(4,'赵六'),(5,'孙七');
Orders表:
CREATE TABLE `orders` (
`id` bigint NOT NULL,
`customerId` bigint NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO orders() VALUES(1,3),(2,1);
3、解题语句
方式一:LEFT JOIN
SELECT
NAME AS '从不订购的用户'
FROM
customers AS c
LEFT JOIN
orders AS o
ON
c.id = o.customerId
WHERE o.customerId IS NULL;
方式二:NOT IN +子查询
SELECT
NAME AS '从不订购的用户'
FROM
customers AS c
WHERE
c.id NOT IN(SELECT customerId FROM orders);
方式三:NOT EXISTS
SELECT
NAME AS '从不订购的用户'
FROM
customers AS c
WHERE
NOT EXISTS(SELECT customerId FROM orders AS o WHERE c.id = o.customerId)
4、题目总结
1、IS NULL/IS NOT NULL的使用:判断是否为NULL
2、IN/NOT IN的使用:
3、EXISTS的使用: EXISTS后跟子查询,子查询能查询到则满足where条件,不能查询到则不满足where条件,NOT EXISTS则相反;
9、部门工资最高的员工(184)
1、题目描述
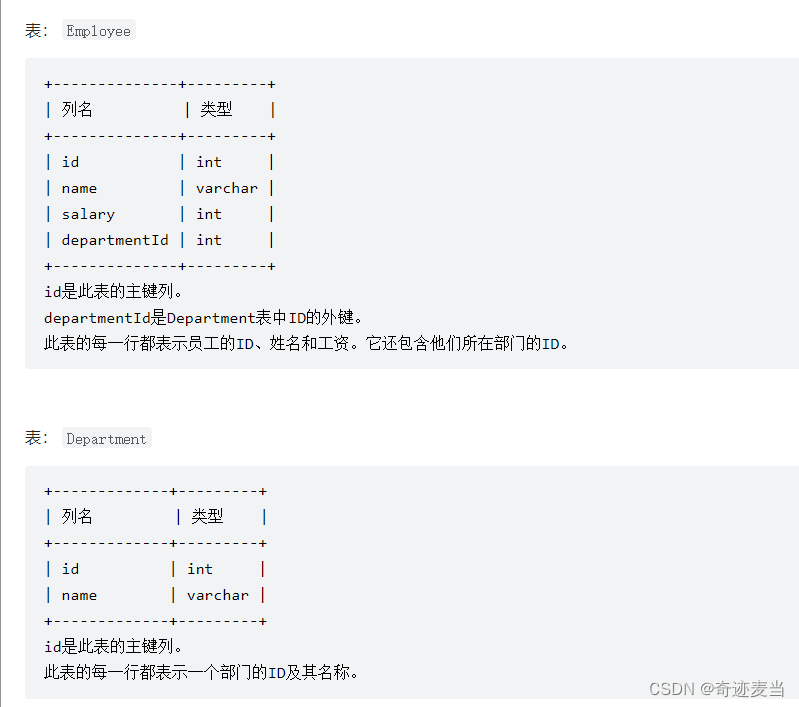
编写SQL查询以查找每个部门中薪资最高的员工。按 任意顺序 返回结果表。
查询结果格式如下例所示:
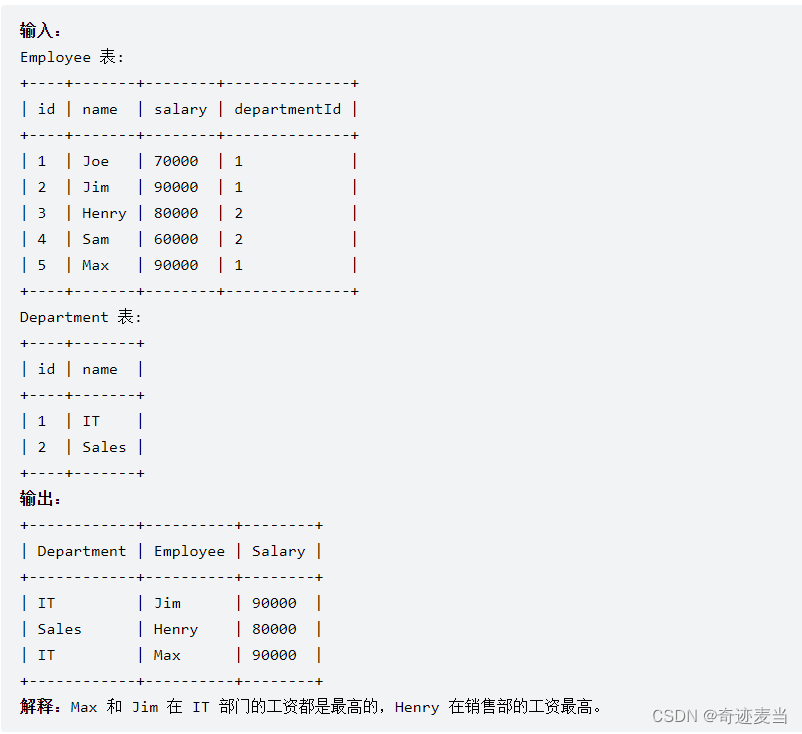
2、建表语句
employee_184表:
CREATE TABLE `employee_184` (
`id` int NOT NULL COMMENT '主键',
`name` varchar(20) NOT NULL COMMENT '员工姓名',
`salary` decimal(5,2) NOT NULL COMMENT '员工薪水',
`departmentId` int NOT NULL COMMENT '员工所在的部门Id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO employee_184() VALUES(1,'张三',7000.00,1),
(2,'李四',9000.00,1),(3,'王五',8000.00,2),
(4,'赵六',6000.00,2),(5,'孙七',9000.00,1);
department表:
CREATE TABLE `department` (
`id` int NOT NULL COMMENT '主键',
`name` varchar(20) NOT NULL COMMENT '部门名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO department() VALUES(1,'IT'),(2,'sales');
3、解题语句
方式一:
SELECT
e.name,e.salary,d.name
FROM
employee_184 AS e,
department AS d
WHERE
e.departmentId = d.id
AND
(e.salary,e.departmentId)
IN (SELECT MAX(salary),departmentId FROM employee_184 GROUP BY departmentId)
ORDER BY e.salary DESC
方式二:窗口函数:dense_rank()over
SELECT
s.d_name, s.e_name, s.salary
FROM
(SELECT d.name AS d_name,
e.name AS e_name,
e.salary,
dense_rank()over(PARTITION BY e.department_id ORDER BY e.salary DESC) r
FROM
employee_184 e
LEFT JOIN
department d
ON
e.department_id = d.ID)AS s
WHERE s.r = 1;
4、题目总结
1、PARTITION BY:按什么划分
SELECT
salary,
dense_rank()over(PARTITION BY department_id ORDER BY salary DESC) AS '薪资排名'
FROM
employee_184;
SELECT
COUNT(1)
FROM
employee_184
GROUP BY
salary;
SELECT
salary
FROM
employee_184
GROUP BY
salary;
2、方式二中修改条件WHERE s.r = 1,可以查询第二高、第三高、或薪水在某个范围的员工;
10、部门工资前三高的所有员工(185)⏫
1、题目描述

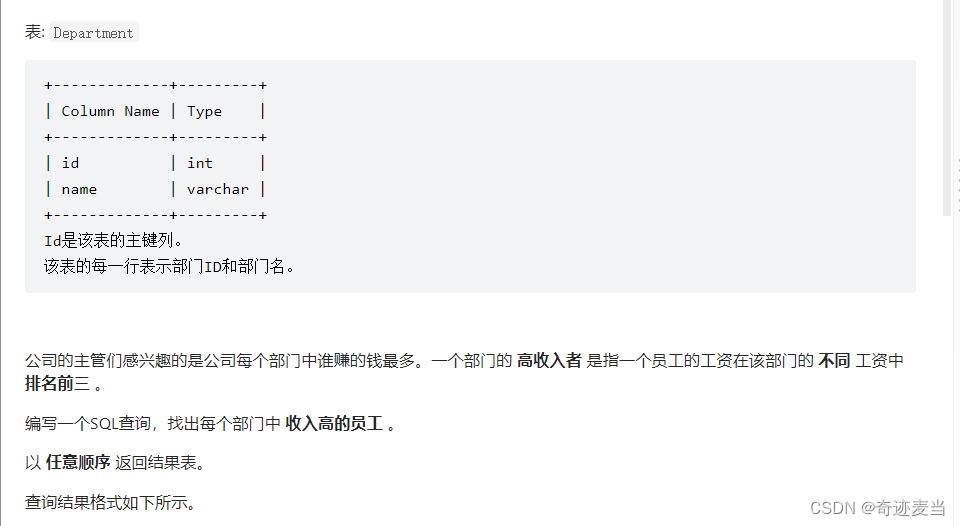

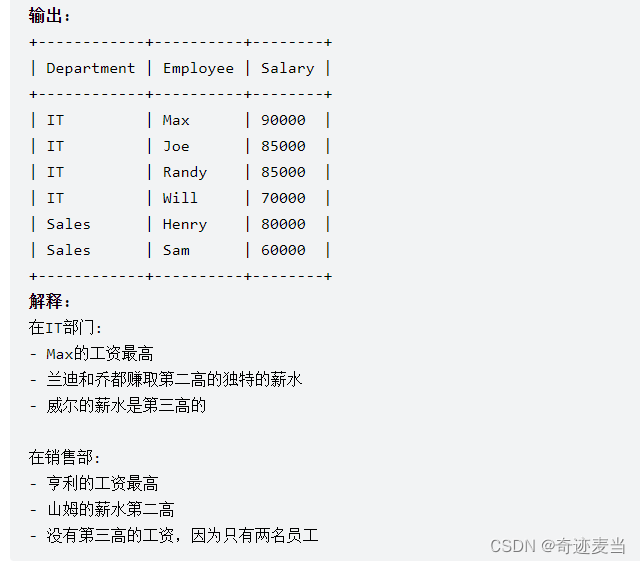
2、建表语句
employee_185:
CREATE TABLE `employee_185` (
`id` int NOT NULL COMMENT '主键',
`name` varchar(20) NOT NULL COMMENT '员工姓名',
`salary` decimal(7,2) NOT NULL COMMENT '员工薪水',
`department_id` int NOT NULL COMMENT '员工所在的部门Id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO employee_185() VALUES(1,'张三',7000.00,1),
(2,'李四',9000.00,1),(3,'王五',8000.00,2),
(4,'赵六',6000.00,2),(5,'孙七',9000.00,1);
department表:
CREATE TABLE `department` (
`id` int NOT NULL COMMENT '主键',
`name` varchar(20) NOT NULL COMMENT '部门名',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
插入数据:
INSERT INTO department() VALUES(1,'IT'),(2,'sales');
3、解题语句
SELECT
s.d_name, s.e_name, s.salary
FROM
(SELECT d.name AS d_name,
e.name AS e_name,
e.salary,
dense_rank()over(PARTITION BY e.department_id ORDER BY e.salary DESC) r
FROM
employee_184 e
LEFT JOIN
department d
ON
e.department_id = d.ID)AS s
WHERE s.r <=3;
4、题目总结
1、核心是排序函数dense_rank()over()函数的使用;
2、PARTITION BY关键字的使用,按照部门进行划分,得到不同部门的各员工薪水;
11、删除重复的电子邮箱(196)
1、题目描述

编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
以 任意顺序 返回结果表。 (注意: 仅需要写删除语句,将自动对剩余结果进行查询)
查询结果格式如下所示。

2、建表语句
#建表语句
CREATE TABLE `person_196` (
`id` int NOT NULL COMMENT 'id主键',
`email` varchar(20) DEFAULT NULL COMMENT '电子邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
#插入数据
INSERT INTO
person_196(id,email)
VALUES
(1,'zhangsan123@qq.com'),(2,'lisi123@qq.com'),(3,'zhangsan123@qq.com');
3、解题语句
方式一:连表查询,自己连自己(不推荐,会产生笛卡尔积,可能产生笛卡尔积现象!! 这里没有产生笛卡尔积现象)。
DELETE
p1
FROM
person_196 p1 , person_196 p2
WHERE
p1.email = p2.email AND p1.id > p2.id;
方式二:子查询 + group by来去重
DELETE FROM person_196 WHERE id NOT IN
(
SELECT id FROM (SELECT MIN(id) AS id FROM person_196 GROUP BY email) AS t
);
4、题目总结
1、update、delete、insert中都可以存在select子句。
2、本题关键在SELECT MIN(id) AS id FROM person_196 GROUP BY email,原理是先对email分组,然后在每一组中得到最小id。
3、由于group by 生成的是中间表,不能对中间表操作,所以需要在套一层select。
4、select子查询需要写别名。
5、自己联自己如果条件没设置好,就可能产生笛卡尔结果集,所以尽量避免,但确定不会产生,就无所谓。
6、笛卡尔积:多张表查询时,底层匹配次数是几张表的乘积,从而影响效率。
7、笛卡尔积现象:多张表查询时,若不限制查询条件,查询出的数据条数是多张表记录条数的乘积。(记录条数多、数据量大时内存一下就爆满了)。你试一下:select * from person_196 p1, person_196 p2;就知道了。
8、建议单表查询,不要联表!!逻辑放在Service层去做。单表查询逻辑简单、提高缓存、减少锁竞争、避免笛卡尔积等等优点。
12、上升的温度
1、题目描述
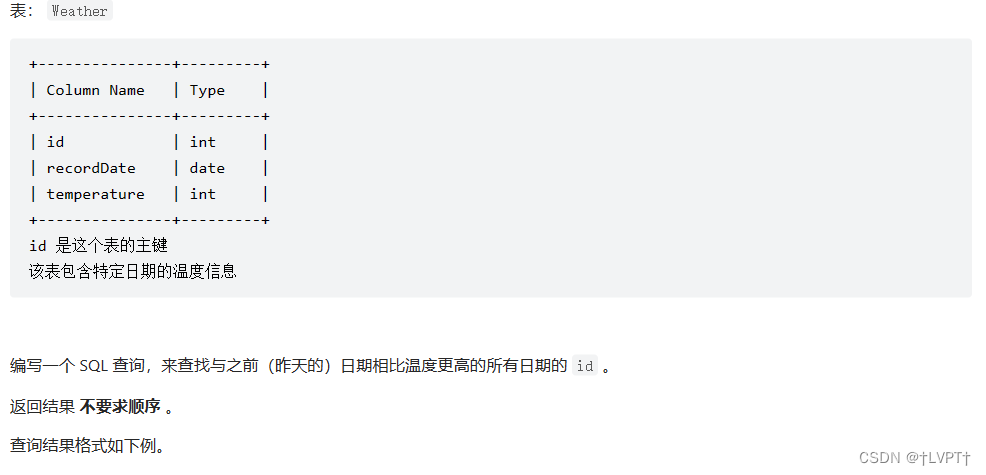

2、建表语句
CREATE TABLE `weather` (
`id` int NOT NULL COMMENT '主键',
`recordDate` date DEFAULT NULL COMMENT '记录水温日期',
`temperature` int DEFAULT NULL COMMENT '水的温度',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
#插入数据
INSERT INTO weather() VALUES(1,'2023-03-01',22)(2,'2023-03-02',18)(3,'2023-03-03',15)(4,'2023-03-04',25);
3、解题语句
方式一:联表查询(产生笛卡尔积) + DATEDIFF()函数
SELECT
w2.id
FROM
weather w1 , weather w2
WHERE
DATEDIFF(w2.recordDate , w1.recordDate) = 1 AND
w2.temperature > w1.temperature;
方式二:使用窗口函数lag() over() + 子查询
SELECT
id
FROM
(SELECT
#前3个字段为当前记录
id,
temperature,
recordDate,
#后2个字段为当前记录的上一条记录recordDate/temperature的值,没有就返回null
lag(recordDate,1) over(ORDER BY recordDate) AS last_date,
lag(temperature,1) over(ORDER BY recordDate) AS last_temperature
FROM
Weather
) AS w
WHERE
temperature > last_temperature AND
DATEDIFF(recordDate, last_date) = 1;
4、题目总结
1、DATEDIFF()函数表示比较两个日期相差的天数。例如:
#返回-1
SELECT DATEDIFF('2023-03-01 21:10:10','2023-03-02 21:10:10');
#返回1
SELECT DATEDIFF('2023-03-02 21:10:10','2023-03-01 21:10:10');
2、窗口函数:lag(recordDate,1) over(ORDER BY recordDate):按recordDate字段排序后,获取当前记录的上一条记录的recordDate的值,若第二个参数为2,者就是上上一条记录,以此类推。
3、联表其实会将两张表的笛卡尔积组合在一起,然后条件过滤得到结果,不推荐联表。
#不加过滤条件产生笛卡尔积现象(两表记录数的乘积,所有组合结果),始终产生笛卡尔积。
SELECT * FROM weather w1 , weather w2;
#或
SELECT * FROM weather w1 INNER JOIN weather w2;
4、关于各种MySQL内置函数,在官网的第12章,时间与日期类函数在12.7小节。
题目来源:https://leetcode.cn
给我,高高飞起来啊!
——麦当














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









