







Clustering集群
Zeebe本质是作为一个brokers集群运行,形成一个点对点网络。在这个网络中,所有brokers的功能与服务都相同,没有单点故障。
Gossip协议
Zeebe实现了gossip协议,并借此知悉哪些broker当前是集群的一部分。
集群使用一组已知的brokers(初创节点)进行初始化并启动,其他brokers节点可以连接到这些已知节点上。为了实现这一点,每个broker在其配置中必须至少有一个初创broker节点作为其初始通信节点:
---
cluster:
initialContactPoints: [node1.mycluster.loc:26502]当broker首次连接到集群时,它会从初创节点获取拓扑,并开始与其他代理进行通信。代理在重新启动时将集群拓扑保留在本地。
Raft协议
为确保容错性,Zeebe基于Raft协议实现跨服务器复制数据。
数据被划分为分区(分片),每个分区都有多个副本(replicas)。在副本集中,leader由Raft协议确定,该leader接收请求并处理所有业务。所有其他brokers都是被动的追随者。当leader不可用时,所有其他brokers会透明地选择出新领leader。
站在不同分区的角度来看,集群中的每个broker可能同时是领导者和从属者。在理想情况下,这会导致客户流量均匀分布在所有brokers之间。
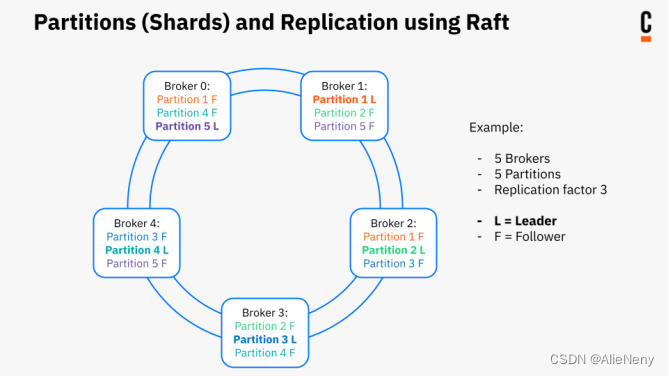
分区之间是没有主动负载平衡的。任何分区的每个领导者选举都是自治的,独立于其他分区的领导者选举。这在极端情况下,是有可能会导致某一个broker节点成为所有分区的领导者。对于容错来说,这不是问题,因为复制的保证仍然存在。但是,这可能会对吞吐量产生负面影响,因为所有流量都到达一个节点。
如若出现了上述情况,为了达到较为均衡的领导者分布,可以在Self-Managed环境中使用Rebalancing API,而BaaS环境下,这部分能力对用户或使用者是不透明的。
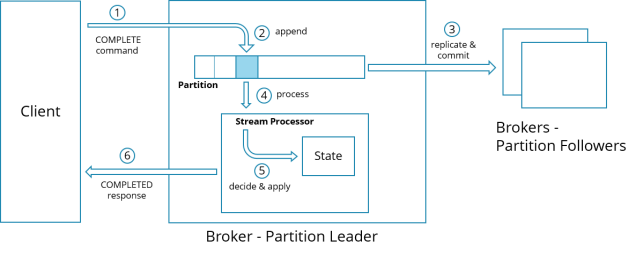
Commit
在处理分区上的新记录之前,必须将其复制到仲裁broker(通常为大多数),此过程称为Commit(提交)。Commit可确保记录是持久的,即使在单个代理上完全丢失数据的情况下也是如此,因为还有数据按分区是具备副本的。Commit的逻辑是由Raft协议定义的。
流程生命周期
在Zeebe中,流程执行在内部由ProcessInstance类型的事件表示。这些事件将写入日志流,并可由exporter发现。
每个事件都是流程实例生命周期中的一个步骤。一个流程实例的所有事件都具有相同的 processInstanceKey。属于同一元素实例的事件(例如任务)具有相同的key。元素实例具有不同的生命周期,具体取决于元素的类型。
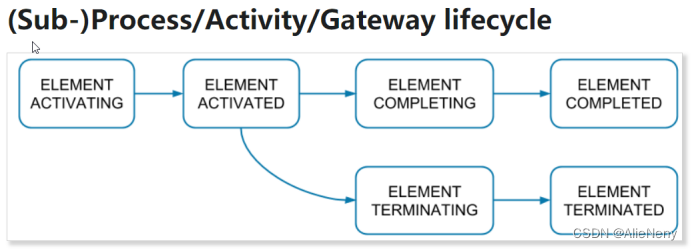
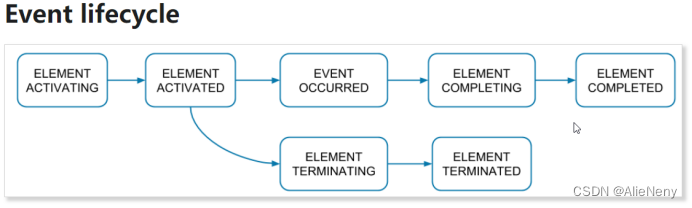

接下来,通过一个示例详细了解一下流程生命周期的概念。

根据上述示例流程,成功执行会在提交日志中生成以下记录:

协议
Zeebe客户端通过无状态网关连接到代理,于客户端和网关之间的通信基于gRPC协议。通信协议是使用 Protocol Buffers v3(proto3)定义的,可以在 Zeebe 代码库中找到它。
gRPC最初由Google开发,目前还是一个开源项目,感兴趣的话,可以通过项目网站上快速了解gRPC。
gRPC具有许多有益的功能,使其非常适合Zeebe,包括:
- 支持双向流式处理,用于在客户端和服务器之间打开持久连接并发送或接收消息流
- 默认使用通用 HTTP/2 协议
- 使用协议缓冲区作为接口定义和数据序列化机制——具体来说,Zeebe 使用 proto3,其支持十种不同编程语言的客户端生成。
目前,Zeebe官方支持两个gRPC客户端:Java 客户端和Golang客户端。社区客户端是用其他语言创建的,包括 C#、Ruby 和 JavaScript。同时,Zeebe还支持加载任意gRPC服务器拦截器来拦截传入请求。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









