







1.读取cvs文件数据写入parquet文件
val spark =SparkSession.builder().appName("test").master("local").getOrCreate()
val file = "hdfs://clusters/test/demo.csv"
val frame = spark.read.option("header","true").csv(file)
frame.printSchema()
val newfile = file.split("\\.")(0)+".parquet"
frame.write.parquet(newfile)
报错提示:
org.apache.parquet.schema.InvalidSchemaException: A group type can not be empty. Parquet does not support empty group without leaves. Empty group: spark_schema
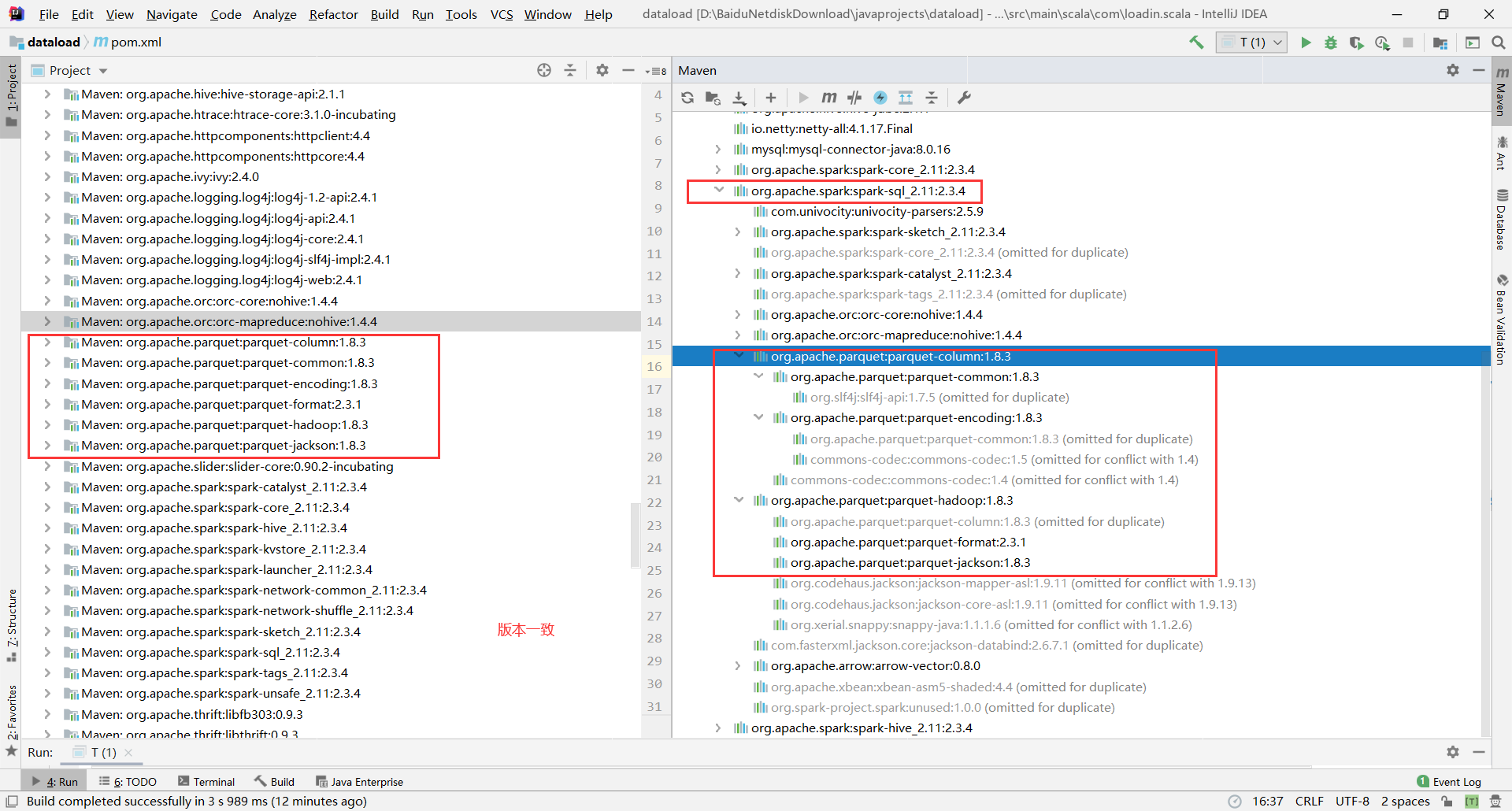
网上找了一大堆资料,大体解释都是说dataframe的schema结构问题,但本文并非此问题。
经过N次尝试,最终确定问题所在是 .parquet(newfile)。代码程序查询,发现此parquet方法调用的parquet包存在两个,默认使用了第一个包,而然这个包并非是spark-sql下的parquet包。
然后,就抱着试试的心态删除了版本1.8.1的parquet包,留下和spark依赖中的parquet包,重新运行代码,直捣黄龙。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









